Download
1 / 1
10 likes | 86 Views
Finding Related Communities on the Web. Masashi Toyoda. We propose a new web search technique, which finds related communities from a given URL.

E N D
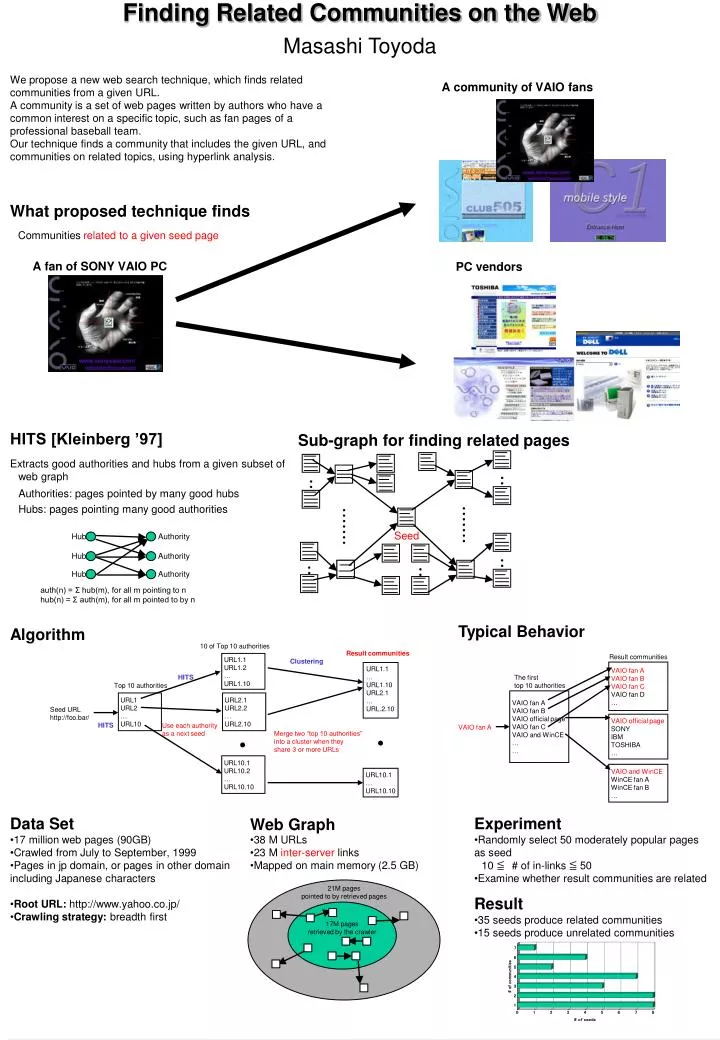
Finding Related Communities on the Web Masashi Toyoda We propose a new web search technique, which finds related communities from a given URL. A community is a set of web pages written by authors who have a common interest on a specific topic, such as fan pages of a professional baseball team. Our technique finds a community that includes the given URL, and communities on related topics, using hyperlink analysis. A community of VAIO fans What proposed technique finds Communities related to a given seed page A fan of SONY VAIO PC PC vendors HITS [Kleinberg ’97] Sub-graph for finding related pages Extracts good authorities and hubs from a given subset of web graph Authorities: pages pointed by many good hubs Hubs: pages pointing many good authorities Seed Hub Authority Hub Authority Hub Authority • auth(n) = Σ hub(m), for all m pointing to n • hub(n) = Σ auth(m), for all m pointed to by n Typical Behavior Algorithm 10 of Top 10 authorities Result communities Result communities URL1.1 URL1.2 … URL1.10 Clustering VAIO fan A VAIO fan B VAIO fan C VAIO fan D … URL1.1 … URL1.10 URL2.1 … URL.2.10 HITS The first top 10 authorities Top 10 authorities VAIO fan A VAIO fan B VAIO official page VAIO fan C VAIO and WinCE … … URL1 URL2 … URL10 URL2.1 URL2.2 … URL2.10 Seed URL http://foo.bar/ VAIO official page SONY IBM TOSHIBA … HITS Use each authority as a next seed VAIO fan A Merge two “top 10 authorities” into a cluster when they share 3 or more URLs URL10.1 URL10.2 … URL10.10 VAIO and WinCE WinCE fan A WinCE fan B … URL10.1 … URL10.10 Data Set Web Graph Experiment • 17 million web pages (90GB) • Crawled from July to September, 1999 • Pages in jp domain, or pages in other domain including Japanese characters • Root URL: http://www.yahoo.co.jp/ • Crawling strategy: breadth first • 38 M URLs • 23 M inter-server links • Mapped on main memory (2.5 GB) • Randomly select 50 moderately popular pages as seed • 10 ≦# of in-links ≦ 50 • Examine whether result communities are related 21M pages pointed to by retrieved pages Result 17M pages retrieved by the crawler • 35 seeds produce related communities • 15 seeds produce unrelated communities






















