Download

1 / 33
571 likes | 1.17k Views
Web Communities. Prasanna Desikan (06/13/2002). Definition. Web community: Groups of individuals who share common interests, together with the web pages most popular among them. Web page collections with a shared topic. Types of Communities. Explicitly- defined.

E N D
Web Communities Prasanna Desikan (06/13/2002)
Definition Web community: • Groups of individuals who share common interests, together with the web pages most popular among them. • Web page collections with a shared topic.
Types of Communities • Explicitly- defined. • Communities that manifest themselves as newsgroups or as resource collections on directories such as Yahoo! • Implicitly- defined. • Communities that result from nature of content-creation of the web.
Terms and Definitions • Directed Bipartite Graph: A graph whose nodes set can be partitioned into two sets F and C, and every directed edge in the graph is from a node u in F to a node v in C.
Terms and Definitions • Completed Bipartite Graph: A bipartite graph that contains all possible edges between a vertex of F and a vertex of C. • Core: A complete bipartite sub-graph with at least inodes from F and at least j nodes from C. • In the web world, the i pages the contains the links are referred to as ‘fans’ and the j pages that are referenced as ‘centers’.
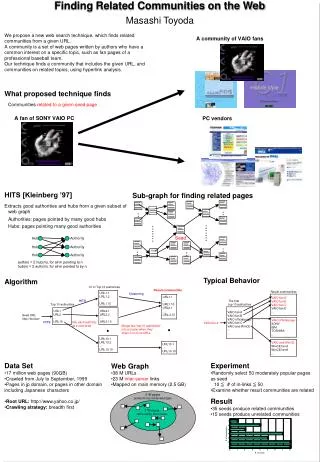
Inferring Web Communities From Link Topology • Community is a core of central authoritative pages linked together by hub pages. • Identify communities corresponding to the principal and non-principal eigenvectors discovered by HITS. • For communities on broad topics: the grouping of pages discovered is relatively independent of the exact choice of root set.
Inferring Web Communities From Link Topology Findings on Structure of Communities. • Robustness: For broad topics, HITS produces stable, robust communities. • Topic Generalization: HITS tend to generalize topics that are not broad. • “Michael Jordan” produces links to pages on MJ and his team. • “Dennis Ritchie” produces links that reference to “C – Programming Language.”
Inferring Web Communities From Link Topology • Other Generalization: HITS tends to converge on topics with greater density of linkage. • E.g for a query on “linguistics”, the top authorities are focused on a sub-topic “computational linguistics” because of its greater density of linkage on web. • Temporal Issues: For obtaining long-term “core” of a topic, we can superimpose the results of HITS on the same topic, spaced-out several month periods.
Trawling the Web for Emerging Web Communities • Trawling: Systematic Enumeration of emerging communities from web crawl. • Scan through a web crawl and identify all instances of graph structures that are indicative signatures of communities.
Trawling the Web for Emerging Web Communities Data Source: A copy of web from Alexa. Pre-processing data. • Identify potential fan pages (a page that has links to at least six different websites) – out of 200 million pages around 24 million were extracted. • Eliminate mirrors (out of 24 million it removed around 60% of pages.
Trawling the Web for Emerging Web Communities • Prune by in-degree. • Eliminate all pages that have an in-degree greater than a threshold value k. k is set as 50 in the experiments. • Iterative pruning. • When looking for (i,j) cores any potential fan with out-degree smaller than j can be pruned and the corresponding edges deleted from the graph.
Trawling the Web for Emerging Web Communities • Inclusion-exclusion pruning. • Let {c1,c2,…..,cj} be centers adjacent to a fan x. • N(ct) = neighborhood of ct, the set of fans that point to ct. • x is a part of core if and only if the intersection of sets N(ct) has size at least i. • Filter nepotistic cores.
Trawling the Web for Emerging Web Communities Evaluation of Communities. • Fossilization: 30% of communities were fossilized. • A fossil is a community core not all of whose fans exist on the web today. • Reliability: Only 4% of the trawled cores were coincidental i.e a collection of fan pages without any cogent theme unifying them.
Trawling the Web for Emerging Web Communities • Quality: 56% were not in Yahoo as constructed from the crawl. And 29% were not in Yahoo at the time of the paper. • This indicates identification of emerging communities by trawling.
Self Organization and Identification of Web Communities • Web community is defined as a collection of web pages such that each member page has more hyperlinks (in either direction) within the community than outside of the community. • Approach: Maximal Flow – Minimal Cut framework. • Benefits: Focused crawling, automatic population of portal categories.
A Simple Community Identification Example Figure : Maximum Flow methods will separate the two subgraphs with any choice of s and t that has s on the left subgraph and t on the right subgraph, removing the three dashed links.
Exact Flow Community • An artificial source ‘s’, is added with infinite capacity edges routed to all seed vertices in S. • Each pre-existing edge is made bi-directional and rescaled to a constant value k.
Exact Flow Community • All vertices except the source, sink, and seed vertices are routed to the artificial sink with unit capacity. • A residual flow graph is produced by a maximum flow procedure. • All vertices accessible from s through non-zero positive edges form the desired result and satisfy our definition of a community.
Sample Results From Community Identification The scores are the total number of inbound and outbound links that a web page has to other pages that are also in the community.
Characterization of Communities Table 3: The fifteen most significant text features for each community, sorted in descending order of the Kullback-Leibler metric.
Discovering Seeds of New Interest Spread From Premature Pages. • A method for discovering topics, which stimulate communities of people into earnest communications on the topics’ meaning, and grow into a trend of popular interest. • Community is a group of people sharing some value.
Agora Methodon Links • Archive page - Page of highest rank according to Google in a community. • Agora Pages -Pages linked from multiple archive-pages but are not in any community themselves are taken as novel topics attracting multiple communities, called agora-topic pages.
Agora Methodon Links • Step 1: A query representing user’s interest domain is entered to a search engine (Google here, obtaining 105 to 106 pages). • Step 2: Communities, of pages obtained in Step 1, are obtained and archive-pages are selected from communities.
Agora Method on Links • Step 3: Pages, not in the communities but linked from multiple archive-pages, are obtained as agora-pages. Having all obtained results by here, archive pages (black nodes), agora-pages (red nodes) and the links between them are visualized as in Fig.1.
Fig: The output of Agora on Links, for domain query “Human Genome”
Evaluation • Stage 1. An interest domain is fixed, a group of people relevant to the domain gathered, and the domain-name is input as a query (e.g. ”information retrieval”). • Stage 2. The output graph adding real and fake red nodes, as if they all were really obtained as agora-pages, is shown to the subjects. That is, some red nodes, not really obtained, were added with red links to black archive-nodes. Subjects reported individual impressions and exchanged ideas in the group.
Sample Results • Institutes in ‘red’ were the ones who have data sources of human or mouse genomes, and is useful for researchers in other institutes to look at those data. • 8 of the 12 ‘red’ nodes were termed as “interesting for thinking of future work” by the subjects.
References • [1]D. Gibson, J. Klienberg, and P.Raghavan. Inferring web communties from link topology. In Proc. 9th ACM Conference on Hypertext and Hypermedia. • [2]Ravi Kumar, Prabhakar Raghavan, Sridhar Rajagopalan, and Andrew Tomkins. Trawling the web for emerging cyber-communities. In Proc 8th Int. World Wide Web Conf.,1999. • [3] Gary William Flake, Steve Lawrence, C. Lee Giles . Efficient Identification of Web Communities. Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. • [4] Gary William Flake, Steve Lawrence, C. Lee Giles, Frans M. Coetzee. Self-Organization and Identification of Web Communities. IEEE Computer, 35(3), 66–71, 2002.
References • [5] Naohiro Matsumura , Yukio Ohsawa , Mitsuru Ishizuka Discovering Seeds of New Interest Spread from Premature Pages Cited by Multiple Communities, 2001 International Conference on Web Intelligence.
Kullback-Leibler Metric • Let p and q be probability distributions with support X and Y respectively. The relative entropy or Kullback-Liebler distance between two probability distributions p and q is defined as Back