Download

1 / 21
210 likes | 296 Views
In Search of PetaByte Databases. Jim Gray Tony Hey. 12/1/1999. 9/1/2000. 9/1/2001. The Cost of Storage (heading for 1K$/TB soon). Summary. DBs own the sweet-spot: 1GB to 100TB Big data is not in databases HPTS does not own high performance storage (BIG DATA) We should

E N D
In Search of PetaByte Databases Jim Gray Tony Hey
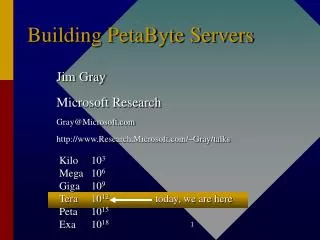
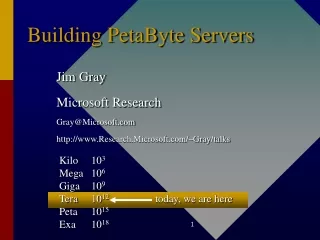
12/1/1999 9/1/2000 9/1/2001 The Cost of Storage(heading for 1K$/TB soon)
Summary • DBs own the sweet-spot: • 1GB to 100TB • Big data is not in databasesHPTS does not own high performance storage (BIG DATA) • We should • Cost of storage is people: • Performance goal:1 Admin per PB
State is Expensive • Stateless clones are easy to manage • App servers are middle tier • Cost goes to zero with Moore’s law. • One admin per 1,000 clones. • Good story about scaleout. • Stateful servers are expensive to manage • 1TB to 100TB per admin • Storage cost is going to zero(2k$ to 200k$). • Cost of storage is management cost
Personal 100 GB todayThe Personal Petabyte (someday) • It’s coming (2M$ today…2K$ in 10 years) • Today the pack rats have ~ 10-100GB • 1-10 GB in text (eMail, PDF, PPT, OCR…) • 10GB – 50GB tiff, mpeg, jpeg,… • Some have 1TB (voice + video). • Video can drive it to 1PB. • Online PB affordable in 10 years. • Get ready: tools to capture, manage, organize, search, display will be big app.
10 TBAn Image Database: TerraServer • Snapshot of the USA (1 meter granularity) • 10,000,000,000,000 (=10^13) sq meters • == 15TB raw (some duplicates) • == 5 TB cooked • 5x compression • + Image pyramid • + gazetteer • Interesting things: • Its all in the Database • Clustered (allows flaky hardware, online upgrade) • Triplexed – snapshot each night
Databases (== SQL) • VLDB survey (Winter Corp). • 10 TB to 100TB DBs. • Size doubling yearly • Riding disk Moore’s law • 10,000 disks at 18GB is 100TB cooked. • Mostly DSS and data warehouses. • Some media managers
DB iFS • DB2: leave the files where they live • Referential integrity between DBMS and FS. • Oracle: put the files in the DBMS • One security model • One storage management model • One space manager • One recovery manger • One replication system • One thing to tune. • Features: transactions,….
Interesting facts • No DBMSs beyond 100TB. • Most bytes are in files. • The web is file centric • eMail is file centric. • Science (and batch) is file centric. • But…. • SQL performance is better than CIFS/NFS.. • CISC vs RISC
BarBar: the biggest DB • 350 TB • Uses Objectivity™ • SLAC events • Linux cluster scans DB looking for patterns
300 TB (cooked)Hotmail / Yahoo • Clone front ends ~10,000@hotmail. • Application servers • ~100 @ hotmail • Get mail box • Get/put mail • Disk bound • ~30,000 disks • ~ 20 admins
AOL (msn)(1PB?) • 10 B transactions per day (10% of that) • Huge storage • Huge traffic • Lots of eye candy • DB used for security/accounting. • GUESS AOL is a petabyte • (40M x 10MB = 400 x 1012)
Google1.5PB as of last spring • 8,000 no-name PCs • Each 1/3U, 2 x 80 GB disk, 2 cpu 256MB ram • 1.4 PB online. • 2 TB ram online • 8 TeraOps • Slice-price is 1K$ so 8M$. • 15 admins (!) (== 1/100TB).
ComputationalScience • Traditional Empirical Science • Scientist gathers data by direct observation • Scientist analyzes data • Computational Science • Data captured by instrumentsOr data generated by simulator • Processed by software • Placed in a database • Scientist analyzes database • tcl scripts • on C programs • on ASCII files
Astronomy • I’ve been trying to apply DB to astronomy • Today they are at 10TB per data set • Heading for Petabytes • Using Objectivity • Trying SQL (talk to me offline)
Fast Moving Objects • Find near earth asteroids: SELECT r.objID as rId, g.objId as gId, r.run, r.camcol, r.field as field, g.field as gField, r.ra as ra_r, r.dec as dec_r, g.ra as ra_g, g.dec as dec_g, sqrt( power(r.cx -g.cx,2)+ power(r.cy-g.cy,2)+power(r.cz-g.cz,2) )*(10800/PI()) as distance FROM PhotoObj r, PhotoObj g WHERE r.run = g.run and r.camcol=g.camcol and abs(g.field-r.field)<2 -- the match criteria -- the red selection criteria and ((power(r.q_r,2) + power(r.u_r,2)) > 0.111111 ) and r.fiberMag_r between 6 and 22 and r.fiberMag_r < r.fiberMag_g and r.fiberMag_r < r.fiberMag_i and r.parentID=0 and r.fiberMag_r < r.fiberMag_u and r.fiberMag_r < r.fiberMag_z and r.isoA_r/r.isoB_r > 1.5 and r.isoA_r>2.0 -- the green selection criteria and ((power(g.q_g,2) + power(g.u_g,2)) > 0.111111 ) and g.fiberMag_g between 6 and 22 and g.fiberMag_g < g.fiberMag_r and g.fiberMag_g < g.fiberMag_i and g.fiberMag_g < g.fiberMag_u and g.fiberMag_g < g.fiberMag_z and g.parentID=0 and g.isoA_g/g.isoB_g > 1.5 and g.isoA_g > 2.0 -- the matchup of the pair and sqrt(power(r.cx -g.cx,2)+ power(r.cy-g.cy,2)+power(r.cz-g.cz,2))*(10800/PI())< 4.0 and abs(r.fiberMag_r-g.fiberMag_g)< 2.0 • Finds 3 objects in 11 minutes • Ugly, but consider the alternatives (c programs an files and…)
Particle Physics – Hunting the Higgs and Dark Matter • April 2006: First pp collisions at TeV energies at the Large Hadron Collider in Geneva • ATLAS/CMS Experiments involve 2000 physicists from 200 organizations in US, EU, Asia • Need to store,access, process, analyse 10 PB/yr with 200 TFlop/s distributed computation • Building hierarchical Grid infrastructure to distribute data and computation • Many 10’s of million $ funding – GryPhyN, PPDataGrid, iVDGL, DataGrid, DataTag, GridPP • ExaBytes and PetaFlop/s by 2015
Astronomy: Past and Future of the Universe • Virtual Observatories – NVO, AVO, AstroGrid • Store all wavelengths, need distributed joins • NVO 500 TB/yr from 2004 • Laser Interferometer Gravitational Observatory • Search for direct evidence for gravitational waves • LIGO 250 TB/yr, random streaming from 2002 • VISTA Visible and IR Survey Telescope in 2004 • 250 GB/night, 100 TB/yr, Petabytes in 10 yrs • New phase of astronomy, storing, searching and analysing Petabytes of data
Engineering, Environment and Medical Applications • Real-Time Health Monitoring • UK DAME project for Rolls Royce Aero Engines • 1 GB sensor data/flight, 100,000 engine hours/day • Earth Observation • ESA satellites generate 100 GB/day • NASA 15 PB by 2007 • Medical Images to Information • UK IRC Project on mammograms and MRIs • 100 MB/mammogram, UK 3M/yr, US 26M/yr • 200 MB/patient, Oxford 500 women/yr • Many Petabytes of data of real commercial interest
Grids, Databases and Cool Tools • Scientists: • will build Grids based on Globus Open Source m/w • will have instruments generating Petabytes of data • will annotate their data with XML-based metadata • Realize a version of Licklider and Taylor’s original vision of resource sharing and the ARPANET • TP and DB community: • Should assist in developing Grid Interfaces to DBMS • Should develop ‘Cool Tools’ for Grid Services • There will be commercial Grid applicationsand viable business opportunities
Summary • DBs own the sweet-spot: • 1GB to 100TB • Big data is not in databases • HPTS crowd is not really high performance storage (BIG DATA) • Cost of storage is people: • Performance goal:1 Admin per PB