Download

1 / 31
310 likes | 322 Views
Learn about the challenges and solutions in 3D medical image registration using CT, MRI, PET, and ultrasound. Explore fusion algorithms and practical implementation on different devices.

E N D
Medical Image RegistrationA Quick Win Richard Ansorge Richard Ansorge
The problem • CT, MRI, PET and Ultrasound produce 3D volume images • Typically 256 x 256 x 256 = 16,777,216 image voxels. • Combining modalities (intermodality) gives extra information. • Repeated imaging over time same modality, e.g. MRI, (intramodality) equally important. • Have to spatially register the images. Richard Ansorge
Example – brain lesion CT MRI PET Richard Ansorge
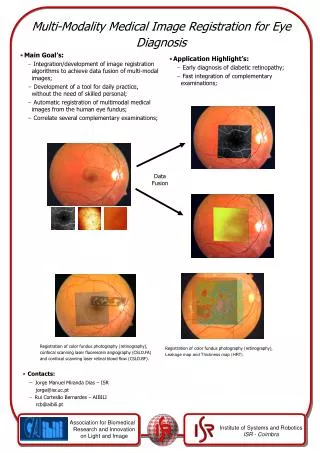
PET-MR Fusion The PET image shows metabolic activity. This complements the MR structural information Richard Ansorge
Registration Algorithm Im A Im A Transform Im B to match Im A Compute Cost Function Im B′ Im B Update transform parameters good fit? No Yes NB Cost function calculation dominates for 3D images and is inherently parallel Done Richard Ansorge
Transformations General affine transform has 12 parameters: Polynomial transformations can be useful for e.g. pin-cushion type distortions: Local, non-linear transformations, e.g using cubic BSplines, increasingly popular, very computationally demanding. Richard Ansorge
We tried this before Richard Ansorge
Now - Desktop PC - Windows XP Needs 400 W power supply Richard Ansorge
Free Software: CUDA & Visual C++ Express Richard Ansorge
Visual C++ SDK in action Richard Ansorge
Visual C++ SDK in action Richard Ansorge
Architecture Richard Ansorge
Current GTX 280 has 240 cores! 9600 GT Device Query Richard Ansorge
Matrix Multiply from SDK NB using 4-byte floats Richard Ansorge
Matrix Multiply (from SDK) Richard Ansorge
Matrix Multiply (from SDK) Richard Ansorge
Matrix Multiply (from SDK) Richard Ansorge
Image Registration CUDA Code Richard Ansorge
#include <cutil_math.h> texture<float, 3, cudaReadModeElementType> tex1; // Target Image in texture __constant__ float c_aff[16]; // 4x4 Affine transform // Function arguments are image dimensions and pointers to output buffer b // and Source Image s. These buffers are in device memory __global__ void d_costfun(int nx,int ny,int nz,float *b,float *s) { int ix = blockIdx.x*blockDim.x + threadIdx.x; // Thread ID matches int iy = blockIdx.y*blockDim.y + threadIdx.y; // Source Image x-y float x = (float)ix; float y = (float)iy; float z = 0.0f; // start with slice zero float4 v = make_float4(x,y,z,1.0f); float4 r0 = make_float4(c_aff[ 0],c_aff[ 1],c_aff[ 2],c_aff[ 3]); float4 r1 = make_float4(c_aff[ 4],c_aff[ 5],c_aff[ 6],c_aff[ 7]); float4 r2 = make_float4(c_aff[ 8],c_aff[ 9],c_aff[10],c_aff[11]); float4 r3 = make_float4(c_aff[12],c_aff[13],c_aff[14],c_aff[15]); // 0,0,0,1? float tx = dot(r0,v); // Matrix Multiply using dot products float ty = dot(r1,v); float tz = dot(r2,v); float source = 0.0f; float target = 0.0f; float cost = 0.0f; uint is = iy*nx+ix; uint istep = nx*ny; for(int iz=0;iz<nz;iz++) { // process all z's in same thread here source = s[is]; target = tex3D(tex1, tx, ty, tz); is += istep; v.z += 1.0f; tx = dot(r0,v); ty = dot(r1,v); tz = dot(r2,v); cost += fabs(source-target); // other costfuns here as required } b[iy*nx+ix]=cost; // store thread sum for host } Richard Ansorge
#include <cutil_math.h> texture<float, 3, cudaReadModeElementType> tex1; // Target Image in texture __constant__ float c_aff[16]; // 4x4 Affine transform // Function arguments are image dimensions and pointers to output buffer b // and Source Image s. These buffers are in device memory __global__ void d_costfun(int nx,int ny,int nz,float *b,float *s) { int ix = blockIdx.x*blockDim.x + threadIdx.x; // Thread ID matches int iy = blockIdx.y*blockDim.y + threadIdx.y; // Source Image x-y float x = (float)ix; float y = (float)iy; float z = 0.0f; // start with slice zero float4 v = make_float4(x,y,z,1.0f); float4 r0 = make_float4(c_aff[ 0],c_aff[ 1],c_aff[ 2],c_aff[ 3]); float4 r1 = make_float4(c_aff[ 4],c_aff[ 5],c_aff[ 6],c_aff[ 7]); float4 r2 = make_float4(c_aff[ 8],c_aff[ 9],c_aff[10],c_aff[11]); float4 r3 = make_float4(c_aff[12],c_aff[13],c_aff[14],c_aff[15]); // 0,0,0,1? float tx = dot(r0,v); // Matrix Multiply using dot products float ty = dot(r1,v); float tz = dot(r2,v); float source = 0.0f; float target = 0.0f; float cost = 0.0f; uint is = iy*nx+ix; uint istep = nx*ny; for(int iz=0;iz<nz;iz++) { // process all z's in same thread here source = s[is]; target = tex3D(tex1, tx, ty, tz); is += istep; v.z += 1.0f; tx = dot(r0,v); ty = dot(r1,v); tz = dot(r2,v); cost += fabs(source-target); // other costfuns here as required } b[iy*nx+ix]=cost; // store thread sum for host } texture<float, 3, cudaReadModeElementType> tex1; __constant__ float c_aff[16]; tex1: moving image, stored as 3D texture c_aff: affine transformation matrix, stored as constants Richard Ansorge
#include <cutil_math.h> texture<float, 3, cudaReadModeElementType> tex1; // Target Image in texture __constant__ float c_aff[16]; // 4x4 Affine transform // Function arguments are image dimensions and pointers to output buffer b // and Source Image s. These buffers are in device memory __global__ void d_costfun(int nx,int ny,int nz,float *b,float *s) { int ix = blockIdx.x*blockDim.x + threadIdx.x; // Thread ID matches int iy = blockIdx.y*blockDim.y + threadIdx.y; // Source Image x-y float x = (float)ix; float y = (float)iy; float z = 0.0f; // start with slice zero float4 v = make_float4(x,y,z,1.0f); float4 r0 = make_float4(c_aff[ 0],c_aff[ 1],c_aff[ 2],c_aff[ 3]); float4 r1 = make_float4(c_aff[ 4],c_aff[ 5],c_aff[ 6],c_aff[ 7]); float4 r2 = make_float4(c_aff[ 8],c_aff[ 9],c_aff[10],c_aff[11]); float4 r3 = make_float4(c_aff[12],c_aff[13],c_aff[14],c_aff[15]); // 0,0,0,1? float tx = dot(r0,v); // Matrix Multiply using dot products float ty = dot(r1,v); float tz = dot(r2,v); float source = 0.0f; float target = 0.0f; float cost = 0.0f; uint is = iy*nx+ix; uint istep = nx*ny; for(int iz=0;iz<nz;iz++) { // process all z's in same thread here source = s[is]; target = tex3D(tex1, tx, ty, tz); is += istep; v.z += 1.0f; tx = dot(r0,v); ty = dot(r1,v); tz = dot(r2,v); cost += fabs(source-target); // other costfuns here as required } b[iy*nx+ix]=cost; // store thread sum for host } // device function declaration __global__ void d_costfun(int nx,int ny,int nz,float *b,float *s) nx, ny & nz: image dimensions (assumed same of both) b: output array for partial sums s: reference image (mislabelled in code) Richard Ansorge
#include <cutil_math.h> texture<float, 3, cudaReadModeElementType> tex1; // Target Image in texture __constant__ float c_aff[16]; // 4x4 Affine transform // Function arguments are image dimensions and pointers to output buffer b // and Source Image s. These buffers are in device memory __global__ void d_costfun(int nx,int ny,int nz,float *b,float *s) { int ix = blockIdx.x*blockDim.x + threadIdx.x; // Thread ID matches int iy = blockIdx.y*blockDim.y + threadIdx.y; // Source Image x-y float x = (float)ix; float y = (float)iy; float z = 0.0f; // start with slice zero float4 v = make_float4(x,y,z,1.0f); float4 r0 = make_float4(c_aff[ 0],c_aff[ 1],c_aff[ 2],c_aff[ 3]); float4 r1 = make_float4(c_aff[ 4],c_aff[ 5],c_aff[ 6],c_aff[ 7]); float4 r2 = make_float4(c_aff[ 8],c_aff[ 9],c_aff[10],c_aff[11]); float4 r3 = make_float4(c_aff[12],c_aff[13],c_aff[14],c_aff[15]); // 0,0,0,1? float tx = dot(r0,v); // Matrix Multiply using dot products float ty = dot(r1,v); float tz = dot(r2,v); float source = 0.0f; float target = 0.0f; float cost = 0.0f; uint is = iy*nx+ix; uint istep = nx*ny; for(int iz=0;iz<nz;iz++) { // process all z's in same thread here source = s[is]; target = tex3D(tex1, tx, ty, tz); is += istep; v.z += 1.0f; tx = dot(r0,v); ty = dot(r1,v); tz = dot(r2,v); cost += fabs(source-target); // other costfuns here as required } b[iy*nx+ix]=cost; // store thread sum for host } int ix = blockIdx.x*blockDim.x + threadIdx.x; // Thread ID matches int iy = blockIdx.y*blockDim.y + threadIdx.y; // Source Image x-y float x = (float)ix; float y = (float)iy; float z = 0.0f; // start with slice zero Which thread am I? (similar to MPI) however one thread for each x-y pixel, 240x256=61440 threads (CF ~128 nodes for MPI) Richard Ansorge
#include <cutil_math.h> texture<float, 3, cudaReadModeElementType> tex1; // Target Image in texture __constant__ float c_aff[16]; // 4x4 Affine transform // Function arguments are image dimensions and pointers to output buffer b // and Source Image s. These buffers are in device memory __global__ void d_costfun(int nx,int ny,int nz,float *b,float *s) { int ix = blockIdx.x*blockDim.x + threadIdx.x; // Thread ID matches int iy = blockIdx.y*blockDim.y + threadIdx.y; // Source Image x-y float x = (float)ix; float y = (float)iy; float z = 0.0f; // start with slice zero float4 v = make_float4(x,y,z,1.0f); float4 r0 = make_float4(c_aff[ 0],c_aff[ 1],c_aff[ 2],c_aff[ 3]); float4 r1 = make_float4(c_aff[ 4],c_aff[ 5],c_aff[ 6],c_aff[ 7]); float4 r2 = make_float4(c_aff[ 8],c_aff[ 9],c_aff[10],c_aff[11]); float4 r3 = make_float4(c_aff[12],c_aff[13],c_aff[14],c_aff[15]); // 0,0,0,1? float tx = dot(r0,v); // Matrix Multiply using dot products float ty = dot(r1,v); float tz = dot(r2,v); float source = 0.0f; float target = 0.0f; float cost = 0.0f; uint is = iy*nx+ix; uint istep = nx*ny; for(int iz=0;iz<nz;iz++) { // process all z's in same thread here source = s[is]; target = tex3D(tex1, tx, ty, tz); is += istep; v.z += 1.0f; tx = dot(r0,v); ty = dot(r1,v); tz = dot(r2,v); cost += fabs(source-target); // other costfuns here as required } b[iy*nx+ix]=cost; // store thread sum for host } float4 v = make_float4(x,y,z,1.0f); float4 r0 = make_float4(c_aff[ 0],c_aff[ 1],c_aff[ 2],c_aff[ 3]); float4 r1 = make_float4(c_aff[ 4],c_aff[ 5],c_aff[ 6],c_aff[ 7]); float4 r2 = make_float4(c_aff[ 8],c_aff[ 9],c_aff[10],c_aff[11]); float4 r3 = make_float4(c_aff[12],c_aff[13],c_aff[14],c_aff[15]); // 0,0,0,1? float tx = dot(r0,v); //Matrix Multiply using dot products float ty = dot(r1,v); float tz = dot(r2,v); float source = 0.0f; float target = 0.0f; float cost = 0.0f; // accumulates cost function contributions v.z=0.0f; // z of first slice is zero (redundant as done above) uint is = iy*nx+ix; // this is index of my voxel in first z-slice uint istep = nx*ny; // stride to index same voxel in subsequent slices Initialisations and first matrix multiply. “v” is 4-vector current voxel x,y,z address “tx,ty,tz” hold corresponding transformed position Richard Ansorge
Z Y X #include <cutil_math.h> texture<float, 3, cudaReadModeElementType> tex1; // Target Image in texture __constant__ float c_aff[16]; // 4x4 Affine transform // Function arguments are image dimensions and pointers to output buffer b // and Source Image s. These buffers are in device memory __global__ void d_costfun(int nx,int ny,int nz,float *b,float *s) { int ix = blockIdx.x*blockDim.x + threadIdx.x; // Thread ID matches int iy = blockIdx.y*blockDim.y + threadIdx.y; // Source Image x-y float x = (float)ix; float y = (float)iy; float z = 0.0f; // start with slice zero float4 v = make_float4(x,y,z,1.0f); float4 r0 = make_float4(c_aff[ 0],c_aff[ 1],c_aff[ 2],c_aff[ 3]); float4 r1 = make_float4(c_aff[ 4],c_aff[ 5],c_aff[ 6],c_aff[ 7]); float4 r2 = make_float4(c_aff[ 8],c_aff[ 9],c_aff[10],c_aff[11]); float4 r3 = make_float4(c_aff[12],c_aff[13],c_aff[14],c_aff[15]); // 0,0,0,1? float tx = dot(r0,v); // Matrix Multiply using dot products float ty = dot(r1,v); float tz = dot(r2,v); float source = 0.0f; float target = 0.0f; float cost = 0.0f; uint is = iy*nx+ix; uint istep = nx*ny; for(int iz=0;iz<nz;iz++) { // process all z's in same thread here source = s[is]; target = tex3D(tex1, tx, ty, tz); is += istep; v.z += 1.0f; tx = dot(r0,v); ty = dot(r1,v); tz = dot(r2,v); cost += fabs(source-target); // other costfuns here as required } b[iy*nx+ix]=cost; // store thread sum for host } for(int iz=0;iz<nz;iz++) { // process all z's in same thread here source = s[is]; target = tex3D(tex1, tx, ty, tz); // NB very FAST trilinear interpolation!! is += istep; v.z += 1.0f; // step to next z slice tx = dot(r0,v); ty = dot(r1,v); tz = dot(r2,v); cost += fabs(source-target); // other costfuns here as required } b[iy*nx+ix]=cost; // store thread sum for host Loop sums contributions for all z values at fixed x,y position. Each tread updates a different element of 2D results array b. Richard Ansorge
Host Code Initialization Fragment ... blockSize.x = blockSize.y = 16; // multiples of 16 a VERY good idea gridSize.x = (w2+15) / blockSize.x; gridSize.y = (h2+15) / blockSize.y; // allocate working buffers, image is W2 x H2 x D2 cudaMalloc((void**)&dbuff,w2*h2*sizeof(float)); // passed as “b” to kernel bufflen = w2*h2; Array1D<float> shbuff = Array1D<float>(bufflen); shbuff.Zero(); hbuff = shbuff.v; cudaMalloc((void**)&dnewbuff,w2*h2*d2*sizeof(float)); //passed as “s” to kernel cudaMemcpy(dnewbuff,vol2,w2*h2*d2*sizeof(float),cudaMemcpyHostToDevice); e = make_float3((float)w2/2.0f,(float)h2/2.0f,(float)d2/2.0f); // fixed rotation origin o = make_float3(0.0f); // translations r = make_float3(0.0f); // rotations s = make_float3(1.0f,1.0f,1.0f); // scale factors t = make_float3(0.0f); // tans of shears ... Richard Ansorge
Calling the Kernel double nr_costfun(Array1D<double> &a) { static Array2D<float> affine = Array2D<float>(4,4); // a holds current transformation double sum = 0.0; make_affine_from_a(nr_fit,affine,a); // convert to 4x4 matrix of floats cudaMemcpyToSymbol(c_aff,affine.v[0],4*4*sizeof(float)); // load constant mem d_costfun<<<gridSize, blockSize>>>(w2,h2,d2,dbuff,dnewbuff); // run kernel CUT_CHECK_ERROR("kernel failed"); // OK? cudaThreadSynchronize(); // make sure all done // copy partial sums from device to host cudaMemcpy(hbuff,dbuff,bufflen*sizeof(float),cudaMemcpyDeviceToHost); for(int iy=0;iy<h2;iy++) for(int ix=0;ix<w2;ix++) sum += hbuff[iy*w2+ix]; // final sum calls++; if(verbose>1){ printf("call %d costfun %12.0f, a:",calls,sum); for(int i=0;i<a.sizex();i++)printf(" %f",a.v[i]); printf("\n"); } return sum; } Richard Ansorge
Example Run (240x256x176 images) C: >airwc airwc v2.5 Usage: AirWc <target> <source> <result> opts(12rtdgsf) C:>airwc sb1 sb2 junk 1f NIFTI Header on File sb1.nii converting short to float 0 0.000000 NIFTI Header on File sb2.nii converting short to float 0 0.000000 Using device 0: GeForce 9600 GT Initial correlation 0.734281 using cost function 1 (abs-difference) using cost function 1 (abs-difference) Amoeba time: 4297, calls 802, cost:127946102 Cuda Total time 4297, Total calls 802 File dofmat.mat written Nifti file junk.nii written, bswop=0 Full Time 6187 timer 0 1890 ms timer 1 0 ms timer 2 3849 ms timer 3 448 ms timer 4 0 ms Total 6.187 secs Final Transformation: 0.944702 -0.184565 0.017164 40.637428 0.301902 0.866726 -0.003767 -38.923237 -0.028792 -0.100618 0.990019 18.120852 0.000000 0.000000 0.000000 1.000000 Final rots and shifts 6.096217 -0.156668 -19.187197 -0.012378 0.072203 0.122495 scales and shears 0.952886 0.912211 0.995497 0.150428 -0.101673 0.009023 Richard Ansorge
Registration with FLIRT 4.1 8.5 Minutes Registration with CUDA 6 Seconds Desktop 3D Registration Richard Ansorge
Comments • This is actually already very useful. Almost interactive (add visualisation) • Further speedups possible • Faster card • Smarter optimiser • Overlap IO and Kernel execution • Tweek CUDA code • Extend to non-linear local registration Richard Ansorge
Figure 1: Schematic of the Larabee many-core architecture: The number of CPU cores and the number and type of co-processors and I/O blocks are implementation-dependent, as are the positions of the CPU and non-CPU blocks on the chip. Intel Larabee? Porting from CUDA to Larabee should be easy Richard Ansorge
Thank you Richard Ansorge