Download

1 / 20
200 likes | 370 Views
Text Mining - Übung. Patrick Jähnichen, Antje Schlaf. Ablauf. Übungen finden im zweiwöchigen Rhythmus statt Nächste Termine: 07.11., 28.11., 12.12., 09.01., 30.01. Termine und Themen stehen rechtzeitig auf der ASV Homepage Termin bestehen aus zwei Teilen

E N D
Text Mining - Übung Patrick Jähnichen, Antje Schlaf
Ablauf • Übungen finden im zweiwöchigen Rhythmus statt • Nächste Termine: 07.11., 28.11., 12.12., 09.01., 30.01. • Termine und Themen stehen rechtzeitig auf der ASV Homepage • Termin bestehen aus zwei Teilen • 50 Minuten: Zwei Vorträge von Studierenden • 20 Minuten Vortrag / 5 Minuten Diskussion • Themenvergabe immer für den nächsten Termin • 40 Minuten: Übung • Fragen zur Vorlesung • Wiederholung des Stoffes • Beispielrechnungen Patrick Jähnichen Textmining - Übung
Themen nächste Woche • Büchler, Geßner, Eckart, Heyer: Unsupervised Detection and Visualization of Textual Reuse on Ancient Greek Texts • Brin: Extracting Patterns and Relations from the World Wide Web Patrick Jähnichen Textmining - Übung
Resource • Projekt Deutscher Wortschatz • wortschatz.uni-leipzig.de • Zugriff auf Webservices • Wörter des Tages • Corpora • corpora.informatik.uni-leipzig.de • Zugriff auf Wortstatistiken, Kookkurrenzen, Kookkurrenzgraphen Patrick Jähnichen Textmining - Übung
Tools • nltk (Natural Language Processing Toolkit) • Python Bibliothek • Verschiedene Korpora verfügbar • Informationen unter www.nltk.org • Dokumentation und Beispiele • Mallet (Machine Learning for Language Toolkit) • Java package • Fokus auf Machine Learning Anwendungen • z.B. Dokumentklassifikation, NER, Topicmodelle • Informationen unter mallet.cs.umass.edu Patrick Jähnichen Textmining - Übung
Text Mining • Begriffsdefinition • Bündel von Analyseverfahren, die die algorithmusassistierte Entdeckung von Bedeutungsstrukturen aus un- oder schwachstrukturierten Textdaten ermöglichen soll (Wikipedia) • Was wollen wir wissen/machen/heraus bekommen? • Analyse großer Dokumentkorpora • Extraktion von bekanntem Wissen (also Namen, Daten, Relationen) • Extraktion von unbekanntem Wissen (etwa thematische Einordnung von Dokumenten, Synonym- und Polysemerkennung, Themenfindung) • Taxonomie- / Ontologieextraktion Patrick Jähnichen Textmining - Übung
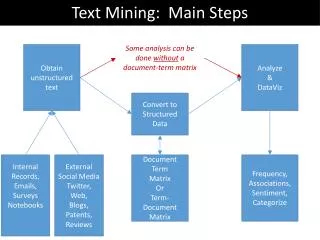
1. Preprocessing: Säubern, LangID, Verweise, ... 2. Filter: Zerlegung, Markup, Metadaten, … Analysis of text Ergebnis-datenbanken 3. Verarbeitung: Dokumente • Indexierung - Muster basierte Verfahren - statistische Verfahren Grundlegendes Vorgehen Patrick Jähnichen Textmining - Übung
Grundlegendes Vorgehen • Preprocessing • Extraktion des eigentlichen Textes • Anlegen von Wörterbüchern • Entfernen von Stopwörtern • Termentfernung (Mindestfrequenz) • Entfernung von Punktuation • Filtering • Extraktion von Metadaten (z.B. Autor des Textes, Erscheinungsort- und Datum, Sprache, etc.) • Stemming/Lemmatisierung (Grundformreduktion) • POS-Tagging Patrick Jähnichen Textmining - Übung
Grundlegendes Vorgehen • Nutzen des extrahierten, gereinigten Textes und der Metadaten zum eigentlichen Textmining • Erstellung von Featurevektoren • Textparameter bestimmen Textmerkmale (aus vorangegangenem Schritt verfügbar) • Textstruktur • Autor • Addressat • Entstehungskontext (Zeit, Ort, Medium) Patrick Jähnichen Textmining - Übung
Featurevektoren für Dokumente • Dokumentlänge • Sprache • Wort N-Gramme und Wortkookkurrenzen • deren Frequenzen • Relative Häufigkeit • Signifikanzen in Verbindung mit Referenzkorpus • Ähnlichkeiten von N-Grammen und Kookkurrenzen • Muster von Wort N-Grammen Patrick Jähnichen Textmining - Übung
Featurevektoren für Einzelwörter • Worthäufigkeit • Wortlänge • (stat. signifikante) Kookkurrenz mit anderen Wörtern • Prä- und Suffixe • POS-Tag • Buchstaben N-Gramme mit Frequenzen • Orthographie Patrick Jähnichen Textmining - Übung
Beispieltext • Ausgangstext • Drei sind einer zu viel: Frankreich war es ein Dorn im Auge, dass im Rat der Europäischen Zentralbank künftig drei Italiener sitzen sollen. Jetzt hat Italiens Premier Berlusconi seinen Landsmann Bini Smaghi aufgefordert, von seinem Posten zurückzutreten - und sich dem Druck des Franzosen Sarkozy gebeugt. • Stopwortentfernung • Frankreich Dorn Auge Rat Europäischen Zentralbank Italiener sitzen Italiens Premier Berlusconi Landsmann Bini Smaghi aufgefordert Posten zurückzutreten Druck Franzosen Sarkozy gebeugt Patrick Jähnichen Textmining - Übung
Beispieltext • POS-Tagging • Frankreich[NN] Dorn[NN] Auge[NN] Rat[NN] Europäischen [ADJ] Zentralbank[NN] Italiener[NN] sitzen[V] Italiens[NN] Premier[NN] Berlusconi[NN] Landsmann[NN] Bini[NN] Smaghi[NN] aufgefordert[V] Posten[NN] zurückzutreten[V] Druck[NN] Franzosen[NN] Sarkozy[NN] gebeugt[V] • einige Wortkookkurrenzen • Wortfenster Länge 2 • Dorn Auge • Franzosen Sarkozy • Premier Berlusconi • Posten zurückzutreten • Wortfenster Länge 3 • Rat (der) Europäischen Zentralbank • Italiens Premier Berlusconi • Landsmann Bini Smaghi • Längere Wortfenster • Druck gebeugt Patrick Jähnichen Textmining - Übung
Verfahren • Stringbasiert • Editierdistanz • Text Reuse • Musterbasiert • Patterns, Bootstrapping • NER, Informations-/Relationsextraktion • Inhaltsbasiert • Latent Semantic Analysis und Topicmodelle • Clustering, Classification • Kookkurrenzbasiert • Hybridverfahren Patrick Jähnichen Textmining - Übung
Named Entity Recognition • Unterverfahren der Informationsextraktion • Fokussierung auf vorgefertigte informationelle Kategorien • Extraktion und korrekte Einordnung von Eigennamen im Text • Nutzung von Einzelwortfeatures • Für jedes Einzelwort soll entschieden werden, ob, und wenn ja, welche Art von Eigenname dies ist. • Kokkurrenz mit anderen Wörtern • z.B. Triggerwörter aus der Vorlesung: GmbH, Stadt, Buch • Orthographie • z.B. Patrick --> Xxxxxxx, IL-2 --> XX-# • Präfixe/Suffixe • Patrick --> <P, <Pa, <Pat, ..., ick>, ck>, k> Patrick Jähnichen Textmining - Übung
Named Entities • Vorname • Nachname • Beruf • Ort • Institution • Daten • Adressen • ... Patrick Jähnichen Textmining - Übung
Named Entity Recognition • Mithilfe von Support Vector Machines • Jedes Objekt (Wort) als Vektor in einem Vektorraum • Anpassung einer Hyperebene im Vektorraum zur Einteilung der Objekte in zwei Klassen (SVM ist ein binärer Klassifikator) • Zur Berechnung der Hyperebene werden nur die ihr am nächsten liegenden Vektoren benötigt --> Stützvektoren (Support Vectors) Patrick Jähnichen Textmining - Übung
Support Vector Machines • Hyperebene nur möglich, wenn Objekte linear trennbar • Trick: Überführung in höherdimensionale Räume, „irgendwann“ ist eine lineare Trennung möglich • In NER One-vs.-All Methode Patrick Jähnichen Textmining - Übung
Support Vector Machines • Vorgehen • Ausgangspunkt ist eine annotierte Liste von Named Entities • d.h. eine Liste von Termen mit Featurevektoren und Kategorisierung • Trainieren einer SVM zur Entscheidung Named Entity <-> „normales“ Substantiv • Für jede Kategorie • Trainieren eine gesonderten SVM zur Entscheidung Kategorie trifft zu <-> trifft nicht zu • One-vs.-All • Kann das Wort in keine Kategorie klassifiziert werden, wird es als allgemein als Named Entity gekennzeichnet Patrick Jähnichen Textmining - Übung
Named Entity Recognition • Musterbasiert mithilfe des Pendelalgorithmus • DEMO Antje Schlaf Patrick Jähnichen Textmining - Übung