Download

1 / 51
520 likes | 657 Views
ALU Architecture and ISA Extensions. Lecture notes from MKP, H. H. Lee and S. Yalamanchili. Reading. Sections 3.2, 3.3-3.5 (only those elements covered in class), and 3.6 Appendix C.5, B.10. Overview. Instruction Set Architectures have a purpose Applications dictate what we need

E N D
ALU Architecture and ISA Extensions Lecture notes from MKP, H. H. Lee and S. Yalamanchili
Reading • Sections 3.2, 3.3-3.5 (only those elements covered in class), and 3.6 • Appendix C.5, B.10
Overview • Instruction Set Architectures have a purpose • Applications dictate what we need • We only have a fixed number of bits • Impact on accuracy • More is not better • We cannot afford everything we want • Basic ALU Design • Addition/subtraction, multiplication, division
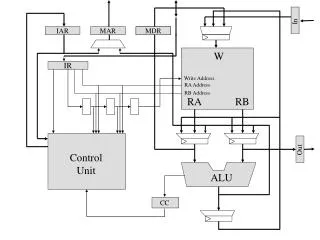
Reminder: ISA byte addressed memory Register File (Programmer Visible State) Who sees what? Memory Interface stack 0x00 0x01 0x02 0x03 Processor Internal Buses 0x1F Dynamic Data Data segment (static) Text Segment Programmer Invisible State Reserved 0xFFFFFFFF Program Counter Instruction register Arithmetic Logic Unit (ALU) Memory Map Kernel registers
Arithmetic for Computers • Operations on integers • Addition and subtraction • Multiplication and division • Dealing with overflow • Operation on floating-point real numbers • Representation and operations • Let us first look at integers
Integer Addition(3.2) • Example: 7 + 6 • Overflow if result out of range • Adding +ve and –ve operands, no overflow • Adding two +ve operands • Overflow if result sign is 1 • Adding two –ve operands • Overflow if result sign is 0
Integer Subtraction • Add negation of second operand • Example: 7 – 6 = 7 + (–6) +7: 0000 0000 … 0000 0111–6: 1111 1111 … 1111 1010+1: 0000 0000 … 0000 0001 • Overflow if result out of range • Subtracting two +ve or two –ve operands, no overflow • Subtracting +ve from –ve operand • Overflow if result sign is 0 • Subtracting –ve from +ve operand • Overflow if result sign is 1 2’s complement representation
ISA Impact • Some languages (e.g., C) ignore overflow • Use MIPS addu, addui, subu instructions • Other languages (e.g., Ada, Fortran) require raising an exception • Use MIPS add, addi, subinstructions • On overflow, invoke exception handler • Save PC in exception program counter (EPC) register • Jump to predefined handler address • mfc0 (move from coprocessor register) instruction can retrieve EPC value, to return after corrective action (more later) • ALU Design leads to many solutions. We look at one simple example
operation op a b res result Integer ALU (arithmetic logic unit)(C.5) • Build a 1 bit ALU, and use 32 of them (bit-slice) a b
Single Bit ALU Implements only AND and OR operations Operation 0 Result A 1 B
Adding Functionality • We can add additional operators (to a point) • How about addition? • Review full adders from digital design cout = ab + acin + bcin sum = a b cin
C a r r y I n O p e r a t i o n a 0 C a r r y I n R e s u l t 0 A L U 0 b 0 C a r r y O u t a 1 C a r r y I n R e s u l t 1 A L U 1 B i n v e r t b 1 C a r r y O u t a 2 C a r r y I n R e s u l t 2 A L U 2 b 2 C a r r y O u t a 3 1 C a r r y I n R e s u l t 3 1 A L U 3 1 b 3 1 Subtraction (a – b) ? • Two's complement approach: just negate b and add 1. • How do we negate? • A clever solution: sub
Tailoring the ALU to the MIPS • Need to support the set-on-less-than instruction(slt) • remember: slt is an arithmetic instruction • produces a 1 if rs< rtand 0 otherwise • use subtraction: (a-b) < 0 implies a < b • Need to support test for equality (beq $t5, $t6, $t7) • use subtraction: (a-b) = 0 implies a = b
B i n v e r t O p e r a t i o n C a r r y I n a 0 1 R e s u l t b 0 2 1 L e s s 3 C a r r y O u t What Result31 is when (a-b)<0? Unsigned vs. signed support
Test for equality • Notice control lines:000 = and001 = or010 = add110 = subtract111 = slt • Note: zero is a 1 when the result is zero! Note test for overflow!
ISA View • Register-to-Register data path • We want this to be as fast as possible CPU/Core $0 $1 $31 ALU
1000 × 1001 1000 0000 0000 1000 1001000 Multiplication • Long multiplication multiplicand multiplier product Length of product is the sum of operand lengths
A Multiplier • Uses multiple adders • Cost/performance tradeoff • Can be pipelined • Several multiplication performed in parallel
MIPS Multiplication • Two 32-bit registers for product • HI: most-significant 32 bits • LO: least-significant 32-bits • Instructions • multrs, rt / multurs, rt • 64-bit product in HI/LO • mfhird / mflord • Move from HI/LO to rd • Can test HI value to see if product overflows 32 bits • mulrd, rs, rt • Least-significant 32 bits of product –> rd Study Exercise: Check out signed and unsigned multiplication with QtSPIM
Division(3.4) • Check for 0 divisor • Long division approach • If divisor ≤ dividend bits • 1 bit in quotient, subtract • Otherwise • 0 bit in quotient, bring down next dividend bit • Restoring division • Do the subtract, and if remainder goes < 0, add divisor back • Signed division • Divide using absolute values • Adjust sign of quotient and remainder as required quotient dividend 1001 1000 1001010 -1000 10 101 1010 -1000 10 divisor remainder n-bit operands yield n-bitquotient and remainder
Faster Division • Can’t use parallel hardware as in multiplier • Subtraction is conditional on sign of remainder • Faster dividers (e.g. SRT division) generate multiple quotient bits per step • Still require multiple steps • Customized implementations for high performance, e.g., supercomputers
MIPS Division • Use HI/LO registers for result • HI: 32-bit remainder • LO: 32-bit quotient • Instructions • div rs, rt / divurs, rt • No overflow or divide-by-0 checking • Software must perform checks if required • Use mfhi, mflo to access result Study Exercise: Check out signed and unsigned division with QtSPIM
ISA View • Additional function units and registers (Hi/Lo) • Additional instructions to move data to/from these registers • mfhi, mflo • What other instructions would you add? CPU/Core $0 $1 $31 ALU Multiply Divide Hi Lo
Floating Point(3.5, 3.6) • Representation for non-integral numbers • Including very small and very large numbers • Like scientific notation • –2.34 × 1056 • +0.002 × 10–4 • +987.02 × 109 • In binary • ±1.xxxxxxx2 × 2yyyy • Types float and double in C normalized not normalized
IEEE 754 Floating-point Representation Single Precision (32-bit) 31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 S exponent significand 23 bits 1bit 8 bits (–1)sign x (1+fraction) x 2exponent-127 Double Precision (64-bit) 63 62 61 60 59 58 57 56 55 54 53 52 51 50 49 48 47 46 45 44 43 42 41 40 39 38 37 36 35 34 33 32 S exponent significand 20 bits 11 bits 1bit significand(continued) 32 bits (–1)sign x (1+fraction) x 2exponent-1023
Floating Point Standard • Defined by IEEE Std 754-1985 • Developed in response to divergence of representations • Portability issues for scientific code • Now almost universally adopted • Two representations • Single precision (32-bit) • Double precision (64-bit)
FP Adder Hardware • Much more complex than integer adder • Doing it in one clock cycle would take too long • Much longer than integer operations • Slower clock would penalize all instructions • FP adder usually takes several cycles • Can be pipelined Example: FP Addition
FP Adder Hardware Step 1 Step 2 Step 3 Step 4
FP Arithmetic Hardware • FP multiplier is of similar complexity to FP adder • But uses a multiplier for significands instead of an adder • FP arithmetic hardware usually does • Addition, subtraction, multiplication, division, reciprocal, square-root • FP integer conversion • Operations usually takes several cycles • Can be pipelined
ISA Impact • FP hardware is coprocessor 1 • Adjunct processor that extends the ISA • Separate FP registers • 32 single-precision: $f0, $f1, … $f31 • Paired for double-precision: $f0/$f1, $f2/$f3, … • Release 2 of MIPs ISA supports 32 × 64-bit FP reg’s • FP instructions operate only on FP registers • Programs generally do not perform integer ops on FP data, or vice versa • More registers with minimal code-size impact
ISA View: The Co-Processor Co-Processor 1 CPU/Core • Floating point operations access a separate set of 32-bit registers • Pairs of 32-bit registers are used for double precision $0 $0 $1 $1 $31 $31 ALU Multiply Divide FP ALU Hi Lo Co-Processor 0 Causes BadVaddr later EPC Status
ISA View • Distinct instructions operate on the floating point registers (pg. B-73) • Arithmetic instructions • add.dfd, fs, ft, and add.sfd, fs, ft • Data movement to/from floating point coprocessors • mcf1 rt, fsand mtc1 rd, fs • Note that the ISA design implementation is extensible via co-processors • FP load and store instructions • lwc1, ldc1, swc1, sdc1 • e.g., ldc1 $f8, 32($sp) double precision single precision Example: DP Mean
Associativity • Floating point arithmetic is not commutative • Parallel programs may interleave operations in unexpected orders • Assumptions of associativity may fail • Need to validate parallel programs under varying degrees of parallelism
Performance Issues • Latency of instructions • Integer instructions can take a single cycle • Floating point instructions can take multiple cycles • Some (FP Divide) can take hundreds of cycles • What about energy (we will get to that shortly) • What other instructions would you like in hardware? • Would some applications change your mind? • How do you decide whether to add new instructions?
Multimedia • Lower dynamic range and precision requirements • Do not need 32-bits! • Inherent parallelism in the operations
Vector Computation • Operate on multiple data elements (vectors) at a time • Flexible definition/use of registers • Registers hold integers, floats (SP), doubles DP) 128-bit Register 1x128 bit integer 2x64-bit double precision 4 x 32-bit single precision 8x16 short integers
Processing Vectors • When is this more efficient? Memory vector registers • When is this not efficient? • Think of 3D graphics, linear algebra and media processing
Case Study: Intel Streaming SIMD Extensions • 8, 128-bit XMM registers • X86-64 adds 8 more registers XMM8-XMM15 • 8, 16, 32, 64 bit integers (SSE2) • 32-bit (SP) and 64-bit (DP) floating point • Signed/unsigned integer operations • IEEE 754 floating point support • Reading Assignment: • http://en.wikipedia.org/wiki/Streaming_SIMD_Extensions • http://neilkemp.us/src/sse_tutorial/sse_tutorial.html#I
Instruction Categories • Floating point instructions • Arithmetic, movement • Comparison, shuffling • Type conversion, bit level • Integer • Other • e.g., cache management • ISA extensions! • Advanced Vector Extensions (AVX) • Successor to SSE register memory register
Arithmetic View • Graphics and media processing operates on vectors of 8-bit and 16-bit data • Use 64-bit adder, with partitioned carry chain • Operate on 8×8-bit, 4×16-bit, or 2×32-bit vectors • SIMD (single-instruction, multiple-data) • Saturating operations • On overflow, result is largest representable value • c.f. 2s-complement modulo arithmetic • E.g., clipping in audio, saturation in video 4x16-bit 2x32-bit
SSE Example // A 16byte = 128bit vector structstruct Vector4{ float x, y, z, w; }; // Add two constant vectors and return the resulting vectorVector4 SSE_Add ( const Vector4 &Op_A, const Vector4 &Op_B ){ Vector4 Ret_Vector; __asm { MOV EAX Op_A // Load pointers into CPU regs MOV EBX, Op_B MOVUPS XMM0, [EAX] // Move unaligned vectors to SSE regs MOVUPS XMM1, [EBX] ADDPS XMM0, XMM1 // Add vector elements MOVUPS [Ret_Vector], XMM0 // Save the return vector } return Ret_Vector;} From http://neilkemp.us/src/sse_tutorial/sse_tutorial.html#I
Characterizing Parallelism • Characterization due to M. Flynn* Today serial computing cores (von Neumann model) Data Streams Single instruction multiple data stream computing, e.g., SSE SISD SIMD Instruction Streams MISD MIMD Today’s Multicore *M. Flynn, (September 1972). "Some Computer Organizations and Their Effectiveness". IEEE Transactions on Computers,C–21 (9): 948–960t
Parallelism Categories From http://en.wikipedia.org/wiki/Flynn%27s_taxonomy
Data Parallel vs. Traditional Vector Vector Architecture Vector Register A Vector Register C Vector Register B pipelined functional unit Data Parallel Architecture registers Process each square in parallel – data parallel computation
ISA View SIMD Registers CPU/Core • Separate core data path • Can be viewed as a co-processor with a distinct set of instructions $0 XMM0 $1 XMM1 $31 XMM15 ALU Multiply Divide VectorALU Hi Lo
Domain Impact on the ISA: Example Scientific Computing EmbeddedSystems • Floats • Double precision • Massive data • Power constrained • Integers • Lower precision • Streaming data • Security support • Energy constrained
Summary • ISAs support operations required of application domains • Note the differences between embedded and supercomputers! • Signed, unsigned, FP, SIMD, etc. • Bounded precision effects • Software must be careful how hardware used e.g., associativity • Need standards to promote portability • Avoid “kitchen sink” designs • There is no free lunch • Impact on speed and energy we will get to this later
Study Guide • Perform 2’s complement addition and subtraction (review) • Add a few more instructions to the simple ALU • Add an XOR instruction • Add an instruction that returns the max of its inputs • Make sure all control signals are accounted for • Convert real numbers to single precision floating point (review) and extract the value from an encoded single precision number (review) • Execute the SPIM programs (class website) that use floating point numbers. Study the memory/register contents via single step execution
Study Guide (cont.) • Write a few simple SPIM programs for • Multiplication/division of signed and unsigned numbers • Use numbers that produce >32-bit results • Move to/from HI and LO registers ( find the instructions for doing so) • Addition/subtraction of floating point numbers • Try to write a simple SPIM program that demonstrates that floating point operations are not associative (this takes some thought and review of the range of floating point numbers) • Look up additional SIMD instruction sets and compare • AMD NEON, Altivec, AMD 3D Now