Download

1 / 17
170 likes | 272 Views
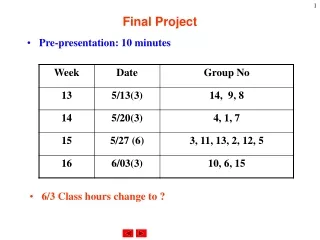
Final project 1. 生科二 19709036 謝朝茂 生科二 19709033 朱利亞. 想法. 產生亂數資料 就亂數資料分群 ( 分 n 群 ) 隨機找 n 個點為中心點 算每個點到個中心點的距離 距離最短的歸那一群 分群後求各群平均值為新的中心點 不斷重複這樣的步驟直到中心點不在變動. method. 開檔產生亂數點.

E N D
Final project 1 生科二 19709036 謝朝茂 生科二 19709033 朱利亞
想法 • 產生亂數資料 • 就亂數資料分群(分n群) • 隨機找n個點為中心點 • 算每個點到個中心點的距離 • 距離最短的歸那一群 • 分群後求各群平均值為新的中心點 • 不斷重複這樣的步驟直到中心點不在變動
開檔產生亂數點 • open(RA, “>C:/Users/Leeyachu/Desktop/go_to_hail/result/randomnumber.txt”) || die “error”;#開檔寫入亂數點print “ 欲產生資料數?:\n”;$NM=<STDIN>;chomp($NM);for($i=0;$i<$NM;$i++){ $p[$i][0]= rand(1000);#產生亂數x值 $p[$i][1]= rand(1000);#產生亂數y值print RA "$p[$i][0] $p[$i][1]\n";}close RA;}
隨機產生中心點 • 輸入欲分幾群($GROUP) • “C:/Users/Leeyachu/Desktop/go_to_hail/result/randomnumber.txt”) || die “error:”;while(<RAN>){@list = split(/\s+/, $_);$p[$NM][0]=$list[0];#讀入亂數點x值$p[$NM][1]=$list[1];#讀入亂數點y值$ra = rand(100)/55;#隨機產生數字if($ra>1.5 and $ran<$GROUP){$point[$ran][0]=$p[$NM][0]; #亂數中心點x值$point[$ran][1]=$p[$NM][1];#亂數中心點y值$ran++;}$NM++;}
分群 • 算距離 • sub group{for($ii=0;$ii<$GROUP;$ii++){$D[$ii]=(($p[$_[0]][0]-$point[$ii][0])**2 + ($p[$_[0]][1]-$point[$ii][1])**2)**0.5;} 註: 設A(x1,y1),B(x2,y2)為平面上相異兩點,則A,B兩點間的距離 =
分群(Subroutine) • 點與中心點的距離的最小值為依據,分成n群。 • for($GP=0; $GP<$GROUP; $GP++){ for($GP1=0; $GP1<$GROUP; $GP1++) { if($D[$GP]<$D[$GP1]){ $GPN++; } } if($GPN==$GROUP-1){ $G[$_[0]]=$GP;#資料點隸屬的群數 $GTX[$GP]=$GTX[$GP]+$p[$_[0]][0];#各群的X值總和(用來算平均值) $GTY[$GP]=$GTY[$GP]+$p[$_[0]][1];#各群的Y值總和(用來算平均值) $GN[$GP]++; } $GPN=0; }return $G[$_[0]];#資料點隸屬的群數}
分群(印出分群資料) • $loop_number=0;while($loop < $NM){$loop_number++;#out put出的資料筆數open(DATA, “>C:/Users/Leeyachu/Desktop/go_to_hail/result/$loop_number.txt”) || die “error:”; open(FILENAME, “>>C:/Users/Leeyachu/Desktop/go_to_hail/result/filename.txt”) || die “error:”;print FILENAME “$loop_number ”; #紀錄輸出檔名$loop=0;for($TEST=0;$TEST<$NM;$TEST++){$a= group($TEST);$a_array[$TEST]=$a;print DATA “$p[$TEST][0] $p[$TEST][1] $a\n”;}#印出亂數點和所屬群數
分群(印出分群資料) • for($new_p=0;$new_p<$GROUP;$new_p++){if($GN[$new_p]==0){$GN[$new_p]=1;}$point[$new_p][0]=$GTX[$new_p]/$GN[$new_p];$point[$new_p][1]=$GTY[$new_p]/$GN[$new_p];print DATA “$point[$new_p][0] $point[$new_p][1] $GROUP\n”;}#印出新的中心點for($TEST1=0;$TEST1<$NM;$TEST1++){$new_group= group($TEST1); if($new_group == $a_array[$TEST1]){ $loop++;}#設定運算何時停止}close DATA;}
畫圖(import 資料) • open(FILENAME, "C:/Users/Leeyachu/Desktop/go_to_hail/result/filename.txt") || die "error:";my $filename = <FILENAME>;my @name = split(/ /, $filename);my $file = 0;for($file=0;$file <= $#name;$file++){open IN, "$name[$file].txt";my (@datax, @datay, @groups);while (<IN>){ my @list = split(/\s+/, $_); push(@datax, $list[0]); push(@datay, $list[1]); push(@groups, $list[2]);} • Out put 分群圖檔
觀察中心點的移動 • 中心點為黃色點(Group 5) • 中心點在每一次計算之後會移動位置 • 中心點不再移動時分群就停止 • 結果得到最佳的分群
討論 • 不改變分群,改變中心點的起始位置 (見final project (改中心點)) • 改變分群 (見final project (改分群)) • 觀察上述兩步對分群步驟的影響
結論(Part 1) • 改變起始中心點的位置,會影響分群要進行多少步。 • 第一次分群只需要3步 • 第二次分群需要6步
結論(Part 2) • 改變分群數,會影響分群要進行多少步。 • 分四群,需要進行五步 • 分六群,需要進行四步
Reference • www2.tchcvs.tc.edu.tw/.../math_teach_power%20point.ppt • http://perl.about.com/od/packagesmodules/qt/perlgdsimple.htm • http://en.wikipedia.org/wiki/K-means_clustering