Download
1 / 51
510 likes | 751 Views
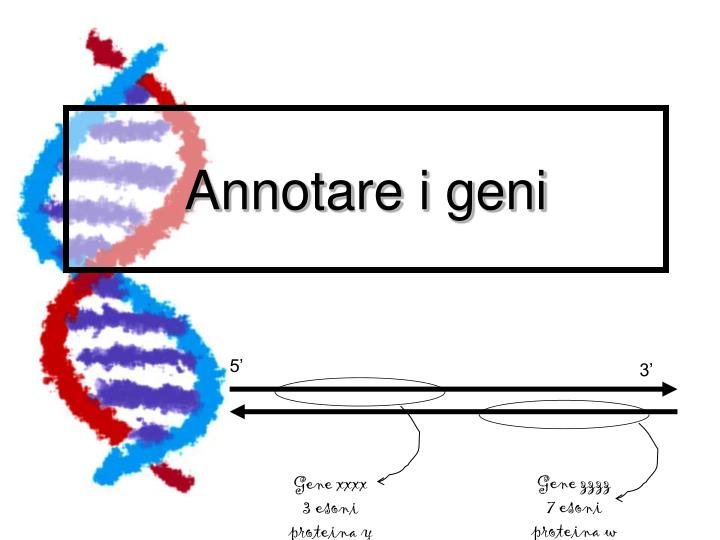
Annotare i geni. 5’. 3’. Gene zzzz 7 esoni proteina w. Gene xxxx 3 esoni proteina y. Il primo passo. Abbiamo la sequenza completa del DNA di un organismo: Quanti geni contiene in tutto? Dove sono localizzati i geni?

E N D
Annotare i geni 5’ 3’ Gene zzzz 7 esoni proteina w Gene xxxx 3 esoni proteina y
Il primo passo... • Abbiamo la sequenza completa del DNA di un organismo: • Quanti geni contiene in tutto? • Dove sono localizzati i geni? • A cosa serve ciascun gene (ovvero, qual è la funzione della proteina codificata, ammesso che effettivamente codifichi per una proteina)? • Quali sono gli splicing alternativi più comuni di ciascun gene?
“Annotare” i geni • Dato un genoma, servono altri due elementi: • mRNA e proteina • Tre indizi fanno una prova: • Conosciamo la proteina (la abbiamo “vista” e sequenziata)? • Conosciamo il trascritto che codifica per la proteina (lo abbiamo sequenziato)? • Conosciamo il gene che produce il trascritto (abbiamo sequenziato la regione corrispondente del genoma)?
Leggere le sequenze • Ovviamente, è possibile determinare anche la sequenza di un trascritto (mRNA), e, con diverse tecniche, anche quella di una proteina • Quindi, se conosco la sequenza di un mRNA, posso localizzare lungo la sequenza genomica la regione che lo produce (e - a tratti - uguale al trascritto!) • Se conosco anche la sequenza della proteina codificata, allora ho completato la annotazione del gene
Leggere le sequenze • Attenzione, però: mentre il DNA è “statico”, e quindi la sua sequenza è presente nella stessa forma in tutte le cellule, lo stesso non vale per gli RNA: • NON tutti i geni sono trascritti in tutte le cellule • A seconda di • Stadio di sviluppo • Tipo di tessuto/cellula • Stimoli esterni Possono variare i geni trascritti e i relativi splicing alternativi • Morale: mentre abbiamo sequenze di genomi completi, non siamo ancora sicuri di avere trascrittomi (e proteomi) completi anche per gli organismi più studiati!
Annotare i geni DNA (doppio filamento) mRNA
Annotare i geni • Quindi, se abbiamo la sequenza del DNA di un organismo possiamo: • Prendere le sequenze di tutti i trascritti che conosciamo • Cercare regioni su uno dei due filamenti che sono uguali al trascritto “a pezzi” • Queste regioni sono... i “geni”!
Un gene, schematicamente 3’ 5’ 3’ 5’ Il trascritto (mRNA) è costituito dalla giunzione dei tratti corrispondenti ai rettangoli (esoni), per i quali si trova una corrispondenza ESATTA su uno dei due filamenti del DNA Sul DNA, gli esoni sono inframmezzati da parti di sequenza che non sono contenuti nell’mRNA, gli introni Le frecce indicano di quale dei due filamenti il trascritto è una copia esatta Gli introni sono sul DNA ma non nel trascritto
Un gene, schematicamente 3’ 5’ 3’ 5’ Il trascritto (mRNA) è costituito dalla giunzione dei tratti corrispondenti ai rettangoli (esoni), per i quali si trova una corrispondenza ESATTA su uno dei due filamenti del DNA Sul DNA, gli esoni sono inframmezzati da parti di sequenza che non sono contenuti nell’mRNA, gli introni Le frecce indicano di quale dei due filamenti il trascritto è una copia esatta Gli introni sono sul DNA ma non nel trascritto
Un gene in un computer Tre esoni: il gene è localizzato sul filamento “antisenso” (quello sotto), detto anche “negativo” (il gene si annota sul filamento che contiene la copia esatta dell’mRNA)
I “Browser” genomici • Come dice il nome stesso, sono strumenti che permettono ai ricercatori di “navigare” all’interno dei genomi di cui si conosce la sequenza, visualizzando tutte le annotazioni che sono disponibili • Sono accessibili via internet: • genome.ucsc.edu (University of California Santa Cruz - sito di riserva - secondo sito di riserva) • www.ensembl.org (sviluppato da EMBL-EBI e dal Sanger Center)
Le Coordinate Genomiche • In ogni sequenza nota, gli elementi che la compongono sono numerati da 1 fino all’ultimo • Sia le sequenze nucleotidiche che quelle aminoacidiche sono orientate • I nucleotidi si leggono da 5’ a 3’ • Gli amminoacidi si leggono da N (terminale) a C (terminale) • Quindi, anche tutti i cromosomi di una specie sono numerati da 1 in poi • Ciascun paio di basi in un genoma è definito da due coordinate: • Numero di cromosoma • Posizione all’interno del cromosoma • I browser mostrano uno dei due filamenti del DNA, ed (implicitamente) anche l’altro
Cliccando uno dei due link si accede al browser
Scelgo il gruppo Scelgo la specie “versione” tratto da visualizzare VIA!
“pulsanti” per muoversi lungo il cromosoma “pulsanti” per avvicinare (zoom in) o allontanare (zoom out) la visuale
“RefSeq” - trascritti “rappresentativi del gene (all’epoca di un gene-un trascritto) UCSC Known Gene - idem, ma annotati dai curatori del sito In più di 300000 paia di basi Un solo gene, con tanti piccoli esoni ed intoni molto più ampi
Ricerca per coordinate • Tornate alla pagina iniziale, e mantendendo le stesse selezioni di prima, provate ad inserire queste coordinate: chr7:155,288,319-155,297,728 (potete copiare ed incollare)
Si viene portati alla regione genomica corrispondente. Tutti i trascritti “mappati” sul genoma sono cliccabili: cliccandoci sopra è possibile cambiare la modalità di visualizzazione e/o accedere a tutte le informazioni disponibili sul gene in questione Se provate a cliccare sulla “riga” nera sotto “Human mRNA from GenBank”....
.... si scopre che ci sono tanti trascritti che provengono da questa regione, non solo uno... e in particolare i diversi trascritti “condividono” alcuni esoni, altri no splicing “alternativi”
Ricerca per parole chiave • Procedendo come si è visto, è possibile esplorare i diversi genomi disponibili • Ma: è possibile utilizzare la casella “coordinate” per effettuare una ricerca per parole chiave • Ad esempio, si può cercare un gene, dato il nome
Lunga lista di risultati, tipo “google”... ma se guardiamo con attenzione c’è un gene che si “chiama” shh sia nella lista “known” che nella lista RefSeq. Cliccando sul link corrispondente...
Annotare bioinformaticamente i geni • Il genome browser permette anche di trovare la corrispondenza trascritto regione genomica come si era visto in precedenza • Nella barra blu in cima alla pagina, cliccate su “Blat”
“BLAT” Selezionate il genoma che vi interessa Incollate la sequenza da cercare
“Blat” • Provate a copiare e incollare la sequenza 1 che trovate alla pagina del corso
Come si può vedere, la vostra sequenza “mappa” in diverse regioni del genoma, su diversi cromosomi; per ogni risultato l’interfaccia vi indica da dove a dove è stata trovata corrispondenza per il trascritto (START-END) Quello che ci interessa, per ora, è il “match” che copre tutto il trascritto, con identità del 100%, ovvero il primo risultato. Cliccando sul link “browser” corrispondente, si viene mandati...
“Blat” • E’ possibile inserire nella casella di ricerca anche la sequenza di una proteina (sequenza 2 della pagina) • L’interfaccia cercherà una regione genomica che - spezzettata in esoni ed introni - tradotta tripletta per tripletta codifica per la proteina che avete sottomesso
Come si può vedere, in questo caso la proteina è andata a “cadere” in una regione dove è già annotato un gene, con il trascritto corrispondente. Però, stavolta, la regione “coperta” dalla proteina è più corta di quella coperta dal trascritto... come mai? E... come mai sono state trovate altre due regioni in cui, almeno parzialmente, è stata trovata corrispondenza per la proteina? Cliccando sul link in corrispondenza del secondo risultato..
In questo caso, siamo andati a finire in una regione (e su un cromosoma!) completamente differente... eppure nella regione è annotato un gene, che tradotto a triplette codifica per qualcosa di simile alla nostra proteina di partenza, e le regioni corrispondenti cadono proprio sugli esoni del gene…
“BLAT” • Terzo esperimento: sempre partendo dalla proteina, nell’interfaccia di “BLAT” selezioniamo il genoma del topo • Cosa succederà, confrontando una proteina umana “contro” il genoma del topo?
Compaiono ben 6 (!) regioni di corrispondenza... notate in particolare che le prime tre coprono regioni abbastanza ampie della proteina, con un’alta percentuale di identità. Cliccando su “browser” in corrispondenza del primo risultato...
... andiamo a cadere proprio in corrispondenza di un gene di topo... la proteina sembra anche coprire tutto il trascritto! Quindi, apparentemente, nel genoma del topo c’è un gene che codifica per una proteina che “assomiglia” a quella dell’uomo? Andiamo a riprendere il primo risultato dell’uomo
TOPO UOMO I due geni sono localizzati su due cromosomi diversi (topo - 5, uomo 7)... ma: Hanno tutti e due 3 esoni ... e qualcuno ha dato lo stesso nome (Shh) sia al gene dell’uomo che a quello del topo...
“BLAT” • Ora effettuiamo il procedimento inverso: a partire dalla proteina del gene SHH di topo, andiamo a mapparla sul genoma umano • Selezionate “Blat”, e “Human” come organismo
.... si ritorna al gene chiamato “shh” dell’uomo! Provando a ritornare indietro, selezionando stavolta il secondo risultato..
... ritroviamo l’IHH, che era stato il secondo “match” di quando avevamo utilizzato la proteina dell’uomo contro il genoma dell’uomo... .... morale.....
Partendo da….. SHH UOMO SHH TOPO SHH UOMO SHH TOPO IHH UOMO IHH TOPO DHH UOMO DHH TOPO Trovo…..
... e gli altri animali? • Proviamo, sempre con BLAT, a selezionare una specie evolutivamente più lontana, utilizzando la proteina dell’uomo.. • .... proviamo con la Drosophila!
In questo caso, la regione che corrisponde alla nostra proteina è molto più piccola, ed è più piccolo anche il frammento di proteina che riusciamo a fare corrispondere... Eppure, c’è una corrispondenza con un gene della Drosophila, che cade esattamente su un esone (e, non a caso, il gene si chiama “hh”....)
L’evoluzione al lavoro Oggi milioni di anni fa HH Drosophila SHH DHH uomo IHH HH Duplicazione SHH DHH topo IHH Duplicazione Ad ogni duplicazione compare un nuovo “HH” Speciazione uomo/topo
I geni omologhi • A questo punto, si può ipotizzare che i vari geni “simili” tra loro che troviamo nelle diverse specie, lo siano perché “parenti”, ovvero discendenti dallo stesso/i gene/i in specie antenate (speciazione) o nella stessa specie (duplicazione) • Due sequenze (sia DNA, sia RNA, sia proteine) per cui possiamo fare questa ipotesi – basandoci sulla loro similarità – sono dette sequenze omologhe • Quindi l’SHH dell’uomo è omologo dell’SHH di topo e dell’HH della Drosophila • Ma anche l’IHH dell’uomo è omologo di SHH dell’uomo, in quanto duplicati dello stesso gene di partenza
Omologhi: ortologhi e paraloghi • Per complicare un po’ la nomenclatura: due sequenze omologhe sono dette • Ortologhe, se sono in specie diverse • Paraloghe, se sono nella stessa specie • Esempio: SHH topo è ortologo a SHH dell’uomo; DHH uomo è ortologo a DHH del topo e paralogo a IHH e SHH dell’uomo • Sulla base della similarità riusciamo anche a ipotizzare se si sia verificata prima una duplicazione o una speciazione
Omologhi e paraloghi • SHH uomo è più simile a SHH topo che a IHH e DHH uomo • Quindi, gli eventi di duplicazione sono più lontani nel tempo rispetto all’evento di speciazione uomo/topo • Ma: considerando ad esempio i geni dell’uomo, quanto è comune trovare ortologhi in altre specie? L’uomo ha dei geni “propri”?
I geni dell’uomo e di altre specie • Per la quasi totalità dei geni dell’uomo si trova un ortologo negli altri mammiferi (inclusi quelli tessuto-specifici, che “caratterizzano” particolari tipi di cellula) • Per la quasi totalità dei geni dell’uomo si trovano ortologhi in altri vertebrati (ci possono essere più o meno duplicati nelle diverse specie) • Per buona parte dei geni dell’uomo si trovano ortologhi in altre specie animali (inclusi, ad esempio, gli invertebrati come gli insetti) • Per i geni “di base” responsabili del “funzionamento” delle diverse cellule si riescono a trovare ortologhi negli eucarioti più semplici (unicellulari come il lievito), o addirittura nei procarioti come i batteri
Usare i geni ortologhi • Oltre che per studi evolutivi, l’ortologia di geni in specie diverse può servire anche allo studio di uno o più geni • Se non conosco la funzione di un gene umano, posso cercarne l’ortologo in topo e studiarlo lì (più “pratico” sperimentalmente) • Annotazione: se ho un gene “mancante” in una specie, posso cercare di localizzarlo basandomi su geni di altre specie • Ovvero, posso cercare di annotare un gene in mancanza di “indizi” (trascritto e/o proteina) basandomi sulle sequenze di altre specie se c’è una data proteina in topo mi posso aspettare che – da qualche parte – nel genoma dell’uomo ci sia un gene che codifica per qualcosa di simile
Annotare i geni con pochi indizi • Manca la proteina: • Posso utilizzare appositi programmi che predicono le possibili traduzioni di un trascritto in proteina • Verifico se in specie vicine a quella che sto studiando sono annotate (possibilmente, sperimentalmente) proteine simili a quella che ho predetto
Annotare i geni con pochi indizi • Manca il trascritto • Così come abbiamo fatto con la proteina di SHH, è possibile cercare nel genoma regioni che tradotte (e concatenate) producono la proteina stessa • E se mancano sia il trascritto che la proteina?