Download

1 / 61
630 likes | 990 Views
Computational Gene Finding. Sanja Rogic CS Department UBC. What is Computational Gene Finding?. Given an uncharacterized DNA sequence, find out: Which region codes for a protein? Which DNA strand is used to encode the gene? Which reading frame is used in that strand?

E N D
Computational Gene Finding Sanja Rogic CS Department UBC Computational Gene Finding
What is Computational Gene Finding? Given an uncharacterized DNA sequence, find out: • Which region codes for a protein? • Which DNA strand is used to encode the gene? • Which reading frame is used in that strand? • Where does the gene starts and ends? • Where are the exon-intron boundaries in eukaryotes? • (optionally) Where are the regulatory sequences for that gene? Computational Gene Finding
Prokaryotes: small genomes 0.5 – 10·106bp high coding density (>90%) no introns Gene identification relatively easy, with success rate ~ 99% Problems: overlapping ORFs short genes finding TSS and promoters Eukaryotes: large genomes 107 – 1010 bp low coding density (<50%) intron/exon structure Gene identification a complex problem, gene level accuracy ~50% Problems: many Prokaryotic Vs. Eukaryotic Gene Finding Computational Gene Finding
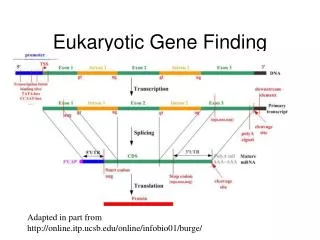
Gene Structure Computational Gene Finding
Gene Finding: Different Approaches • Similarity-based methods (extrinsic) - use similarity to annotated sequences: • proteins • cDNAs • ESTs • Comparative genomics - Aligning genomic sequences from different species • Ab initio gene-finding (intrinsic) • Integrated approaches Computational Gene Finding
Similarity-based methods • Based on sequence conservation due to functional constraints • Use local alignment tools (Smith-Waterman algo, BLAST, FASTA) to search protein, cDNA, and EST databases • Will not identify genes that code for proteins not already in databases (can identify ~50% new genes) • Limits of the regions of similarity not well defined Computational Gene Finding
Comparative Genomics • Based on the assumption that coding sequences are more conserved than non-coding • Two approaches: • intra-genomic (gene families) • inter-genomic (cross-species) • Alignment of homologous regions • Difficult to define limits of higher similarity • Difficult to find optimal evolutionary distance (pattern of conservation differ between loci) Computational Gene Finding
Summary for Extrinsic Approaches Strengths: • Rely on accumulated pre-existing biological data, thus should produce biologically relevant predictions Weaknesses: • Limited to pre-existing biological data • Errors in databases • Difficult to find limits of similarity Computational Gene Finding
Ab initio Gene Finding, Part 1 Input: A DNA string over the alphabet {A,C,G,T} Output: An annotation of the string showing for every nucleotide whether it is coding or non-coding AAAGCATGCATTTAACGAGTGCATCAGGACTCCATACGTAATGCCG Gene finder AAAGC ATGCAT TTA ACG A GT GCATC AG GA CTC CAT ACGTAA TGCCG Computational Gene Finding
Ab initio Gene Finding, Part 2 • Using only sequence information • Identifying only coding exons of protein-coding genes (transcription start site, 5’ and 3’ UTRs are ignored) • Integrates coding statistics with signal detection Computational Gene Finding
Coding Statistics, Part 1 • Unequal usage of codons in the coding regions is a universal feature of the genomes • uneven usage of amino acids in existing proteins • uneven usage of synonymous codons (correlates with the abundance of corresponding tRNAs) • We can use this feature to differentiate between coding and non-coding regions of the genome • Coding statistics - a function that for a given DNA sequence computes a likelihood that the sequence is coding for a protein Computational Gene Finding
Coding Statistics, Part 2 • Many different ones • codon usage • hexamer usage • GC content • compositional bias between codon positions • nucleotide periodicity • … Computational Gene Finding
An Example of Coding Statistics, Part 1 Computational Gene Finding
An Example of Coding Statistics, Part 2 • Let F(c) be the frequency (probability) of codon c in the genes of the species under consideration • Given the sequence of codons C=c1c2…cmand assuming independence between adjacent codons: P(C)=F(c1)F(c2)…F(cm) is probability of finding C, knowing that C codes for protein Example:S=AGGACC c1=AGG c2= ACC P(S) = F(AGG)·F(ACC) = 0.022·0.038= 0.000836 Computational Gene Finding
An Example of Coding Statistics, Part 3 • Let F0(c) be the frequency of codon c in a non-coding sequence. P0 (C)=F0(c1)F0(c2)…F0(cm) is the probability of finding C, knowing that C is non-coding • Assuming the random model of non-coding DNA, F0(c) = 1/64= 0.0156 for all codons P0 (S) = 0.0156 ·0.0156 = 0.000244 • The log-likelihood (LP) ratio for S is: LP(S) = log(0.000836/0.000244) = log(3.43) = 0.53 LP(S) > 0 S is coding Computational Gene Finding
Computing Coding Statistics in Practice • Usually, the value of coding statistics is computed using sliding windows coding profile of the sequence • Larger windows are required to detect a clear signal (50 – 200 bp) Computational Gene Finding
Coding Profile of ß-globin gene Computational Gene Finding
Signal Sensors, Part 1 • Signal – a string of DNA recognized by the cellular machinery Computational Gene Finding
Signal Sensors, Part 2 • Various pattern recognition method are used for identification of these signals: • consensus sequences • weight matrices • weight arrays • decision trees • Hidden Markov Models (HMMs) • neural networks • … Computational Gene Finding
Example of Consensus Sequence • obtained by choosing the most frequent base at each position of the multiple alignment of subsequences of interest TACGAT TATAAT TATAAT GATACT TATGAT TATGTT consensus sequence consensus (IUPAC) Leads to loss of information and can produce many false positive or false negative predictions TATAAT MELON MANGO HONEY SWEET COOKY TATRNT MONEY Computational Gene Finding
Example of (Positional) Weight Matrix • Computed by measuring the frequency of every element of every position of the site (weight) • Score for any putative site is the sum of the matrix values (converted in probabilities) for that sequence (log-likelihood score) • Disadvantages: • cut-off value required • assumes independence between adjacent bases TACGAT TATAAT TATAAT GATACT TATGAT TATGTT Computational Gene Finding
Example of Decision Tree Computational Gene Finding
Markov Models Computational Gene Finding
Ingredients of a Markov Model • Collection of states {S1, S2, …,SN} • State transition probabilities (transition matrix) Aij = P(qt+1 = Si | qt = Sj) • Initial state distribution i = P(q1 = Si) Computational Gene Finding
Ingredients of Our Markov Model • Collection of states {Ssunny, Srainy, Ssnowy} • State transition probabilities (transition matrix) A = • Initial state distribution i = (.7 .25 .05) Computational Gene Finding
Probability of a Sequence of Events P(Ssunny)xP(Srainy | Ssunny)xP(Srainy | Srainy)x P(Srainy | Srainy)xP(Ssnowy | Srainy)xP(Ssnowy | Ssnowy) = 0.7x0.15x0.6x0.6x0.02x0.2 = 0.0001512 Computational Gene Finding
Hidden Markov Models Computational Gene Finding
Ingredients of a HMM • Collection of states: {S1, S2,…,SN} • State transition probabilities (transition matrix) Aij = P(qt+1 = Si | qt = Sj) • Initial state distribution i = P(q1 = Si) • Observations: {O1, O2,…,OM} • Observation probabilities: Bj(k) = P(vt = Ok | qt = Sj) Computational Gene Finding
Ingredients of Our HMM • States: {Ssunny, Srainy, Ssnowy} • State transition probabilities (transition matrix) A = • Initial state distribution i = (.7 .25 .05) • Observations: {O1, O2,…,OM} • Observation probabilities (emission matrix): B = Computational Gene Finding
Probability of a Sequence of Events P(O) = P(Ogloves, Ogloves, Oumbrella,…, Oumbrella) = P(O | Q)P(Q) = P(O | q1,…,q7) = 0.7x0.86x0.32x0.14x0.6 + … all Q q1,…q7 Computational Gene Finding
Typical HMM Problems Annotation Given a model M and an observed string S, what is the most probable path through M generating S Classification Given a model M and an observed string S, what is the total probability of S under M Consensus Given a model M, what is the string having the highest probability under M Training Given a set of strings and a model structure, find transition and emission probabilities assigning high probabilities to the strings Computational Gene Finding
HMMs and Gene Structure • Nucleotides {A,C,G,T} are the observables • Different states generates generate nucleotides at different frequencies A simple HMM for unspliced genes: AAAGCATGCAT TTA ACG AGA GCA CAA GGG CTCTAATGCCG • The sequence of states is an annotation of the generated string – each nucleotide is generated in intergenic, start/stop, coding state Computational Gene Finding
State of the Art in Ab initio Gene Finding • Coding statistics and signal sensors are integrated in overall gene model using • machine learning techniques (HMMs, decision trees, neural networks) • discriminant functions (linear, quadratic) • Use dynamic programming (Viterbi) to find the highest scoring path through the model • Capable of predicting: • genes on both strands simultaneously • partial and multiple genes in a sequence • suboptimal exons Computational Gene Finding
Examples of Gene Finders FGENES – linear DF for content and signal sensors and DP for finding optimal combination of exons GeneMark – HMMs enhanced with ribosomal binding site recognition Genie – neural networks for splicing, HMMs for coding sensors, overall structure modeled by HMM Genscan – WM, WA and decision trees as signal sensors, HMMs for content sensors, overall HMM HMMgene – HMM trained using conditional maximum likelihood Morgan – decision trees for exon classification, also Markov Models MZEF – quadratic DF, predict only internal exons Computational Gene Finding
Genscan Example • Developed by Chris Burge 1997 • One of the most accurate ab initio programs • Uses explicit state duration HMM to model gene structure (different length distributions for exons) • Different model parameters for regions with different GC content Computational Gene Finding
E0 E1 E2 I0 I1 I2 Einit Eterm 3’ UTR 5’ UTR Esngl polyA P forward strand N backward strand polyA P 5’ UTR Esngl 3’ UTR Einit Eterm I0 I1 I2 E0 E1 E2 Computational Gene Finding
Genscan’s Architecture • HMM’s states for exons and introns in three different phases, single exon, 5’ and 3’ UTRs, promoter region and polyA site and intergenic region • Explicit length modeling • HMMs for exons, introns and intergenic regions • WM and WA for acceptor site, branch point, polyA site and promoter region • Decision tree (maximal dependence decomposition) for donor sites Computational Gene Finding
Ab initio Gene Finding is Difficult • Genes are separated by large intergenic regions • Genes are not continuous, but split in a number of (small) coding exons, separated by (larger) non-coding introns • in humans coding sequence comprise only a few percents of the genome and an average of 5% of each gene • Sequence signals that are essential for elucidation of a gene structure are degenerate and highly unspecific • Alternative splicing • Repeat elements (>50% in humans) – some contain coding regions Computational Gene Finding
Problems with Ab initio Gene Finding • No biological evidence • In long genomic sequences many false positive predictions • Prediction accuracy high, but not sufficient Computational Gene Finding
Evaluation of Gene Finding Programs • Calculating accuracy of programs’ predictions • Several evaluation studies: • Burset and Guigó, 1996 (vertebrate sequences) • Pavy et al., 1999 (Arabidopsis thaliana) • Rogic et al., 2001 (mammalian sequences) Computational Gene Finding
FN TN FN TP FN TN TN TP FP REALITY PREDICTION Measures of Prediction Accuracy, Part 1 Nucleotide level accuracy Sensitivity = Specificity = number of correct exons number of actual exons number of correct exons number of predicted exons Computational Gene Finding
Measures of Prediction Accuracy, Part 2 Exon level accuracy MISSING EXON WRONGEXON CORRECTEXON REALITY PREDICTION Computational Gene Finding
Evaluation in Rogic et al., 2001 • We developed a new dataset for this purposes – HMR195 • Characteristics of the sequences: • human – mouse – rat origin • Relatively short DNA sequences from GenBank • one gene per sequence • sequences used for the training of the programs were excluded Computational Gene Finding
More About HMR195 • Filtering: • Canonical start and stop codon • No in-frame stop codons • Canonical splice site dinucleotides AG – GT • Redundancy filtering: similar sequences excluded • Confirming exon locations using mRNA alignment Computational Gene Finding
Evaluation Results Computational Gene Finding
Additional Testing • Accuracy as a function of sequence and prediction characteristics: • GC content • exon length • exon type • exon type and signal • exon probabilities and scores • phylogenetic specificity Computational Gene Finding
Integrated Approaches for Gene Finding • Programs that integrate results of similarity searches with ab initio techniques (GenomeScan, FGENESH+, Procrustes) • Programs that use synteny between organisms (ROSETTA, SLAM) • Integration of programs predicting different elements of a gene (EuGène) • Combining predictions from several gene finding programs (combination of experts) Computational Gene Finding
Combining Programs’ Predictions • Set of methods used and they way they are integrated differs between individual programs • Different programs often predict different elements of an actual gene they could complement each other yielding better prediction Computational Gene Finding
Related Work • This approach was suggested by several authors • Burset and Guigó (1996) • Investigated correlation between 9 gene-finding programs • 99% of exons predicted by all programs were correct • 1% of exons completely missed by all programs • Murakami and Tagaki (1998) • Five methods for combining the prediction by 4 gene-finding programs • Nucleotide level accuracy measures improved by 3-5% in comparison with the best single Computational Gene Finding