Download

1 / 37
390 likes | 722 Views
SIMILARITY OF WEIGHTED DIRECTED ACYCLIC GRAPHS. Presented By: Jing Jin Supervisors: Dr. Virendra C. Bhavsar and Dr. Harold Boley Aug. 31, 2006. Outline. Introduction Schema Matching E-Business & Multi-agent System Tree and Graph Similarity Techniques The wDAG Similarity Algorithm

E N D
SIMILARITY OF WEIGHTED DIRECTED ACYCLIC GRAPHS Presented By: Jing Jin Supervisors: Dr. Virendra C. Bhavsar and Dr. Harold Boley Aug. 31, 2006
Outline • Introduction • Schema Matching • E-Business & Multi-agent System • Tree and Graph Similarity Techniques • The wDAG Similarity Algorithm • wDAG Representation • The Flow Chart • Main Functions • The Data Structure for Reusing Computation Results • Illustrative Example • Comparison of Typical Schema Matching Algorithms • Computational Results • Conclusion • Future Work • References
IntroductionSchema Matching Fig. 1 The match operation [30] • Schema matching is a fundamental problem in many application domains, such as e-Business, semantic web, data integration and semantic query processing.
IntroductionE-Business & Multi-agent System • The wide acceptance of advanced technologies from the semantic web and web services in e-Business. • A multi-agent system can provide a virtual marketplace for seller and buyer agents to conduct e-Business activities, where the match-making between them is a crucial step.
IntroductionTree and Graph Similarity Techniques • Much research has been done on tree [5, 21, 27, 32, 37, 39, 40] and graph [22, 23, 36, 41] similarity techniques. • The weighted tree similarity algorithm [5] Fig. 2 An example of two weighted trees describing second hand car information
IntroductionTree and Graph Similarity Techniques (cont’d) • The tree edit distance algorithm [21, 27, 39] Fig. 3 A tree edit distance example
Similarity flooding [23] IntroductionTree and Graph Similarity Techniques (cont’d) Fig. 4 The sequence of steps to determine the correspondences between tables and columns in S1 and S2
CUPID [22] IntroductionReusing Schema and Mapping Information Fig. 5 An example of lazy schema tree expansion
COMA [11, 31] IntroductionReusing Schema and Mapping Information (cont’d) Fig. 6 An example of reusing previous similarity value in COMA
Fig. 4 The weighted tree from Fig. 3 folded into a wDAG representation
The wDAG Similarity Algorithm wDAG Representation Fig. 5 wDAG serialization in weighted OO RuleML
The wDAG Similarity AlgorithmThe Flow Chart Fig. 6 The flow chart of the wDAG similarity algorithm
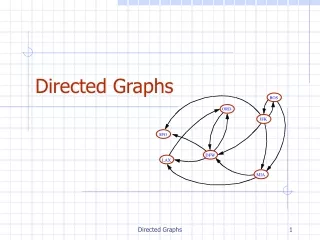
The wDAG Similarity AlgorithmMain Functions Fig. 7 The comparison between wDAGs A and B
The wDAG Similarity AlgorithmMain Functions:wDAGsim(g, g’) The equation embedded in the main function wDAGsim(g, g’) that computes the similarity of two (sub)wDAGs is shown below.
The wDAG Similarity AlgorithmMain Functions:wDAGplicity(g) The equation embedded in the wDAGplicity(g) that computes the simplicity of the missing wDAG is shown below. where, DI: depth degradation index, 0 < DI 1.0 DF: depth degradation factor, 0 < DF 0.5 m: breadth of the wDAG g that is not a leaf. DI= 1.0 DF =0.5
The wDAG Similarity AlgorithmThe Data Structure for Reusing Computation Results • Two-dimensional Matrix • Adjacency Lists
The Data Structure for Reusing Computation ResultsTwo-dimensional Matrix • The matrix would be a sparse one which contains many NULL values. Table 1 The two-dimensional matrix corresponding to the wDAGs in Fig. 7 Table 3 Single-dimensional array of wDAG B Table 2 Single-dimensional array of wDAG A
The Data Structure for Reusing Computation ResultsAdjacency Lists Fig. 8 The structure of adjacency lists Fig. 9 The corresponding adjacency lists of the example in in Fig. 7
Table 4: Comparison of Typical Schema Matching Algorithms (cont’d)
Table 4: Comparison of Typical Schema Matching Algorithms (cont’d)
Example Set 2 Example 1 Example 2
Example Set 2 (cont’d) Example 2 Example 3
Example Set 2 (cont’d) Example 4 Example 5
Remarks • The size of OO RuleML source file of wDAG is smaller than that of weighted tree because wDAG eliminates the duplicate copies of shared substructures. And the time complexity of the wDAG algorithm is much lower than that of the weighted tree algorithm.
Conclusion • Mechanisms of schema matching approaches have been reviewed, and relevant tree and graph similarity techniques have been studied. • A wDAG similarity algorithm for the match-making in e-Business environments have been proposed. If two wDAGs are intuitively more similar, our similarity value is higher, otherwise, it is lower. • The intermediate similarity and simplicity values of shared sub-wDAGs can be reused efficiently through the adjacency lists structure. • The applicability and efficiency of the weighted tree similarity algorithm have been improved. • To our knowledge, in the field of match-making in e-Business environments, wDAG representations and their similarity measures have not been studied before.
Future Work • The test data is currently developed manually. A tool should be developed to provide a graphical user interface for users to define such data, like the Teclantic application of the AgentMatcher group (http://teclantic.ca/). • Improvements should be made on the simplicity function. One way is to replace the arithmetic mean by the geometric mean, as currently explored by the AgentMatcher group. • The proposed algorithm outputs the similarity between two wDAGs. The similarity values for multiple wDAGs should be ranked by some sorting algorithm, like bubble sort, just as the AgentMatcher group has already implemented ranking for tree similarity.
References • Allali, J. and Sagot, M.F., A New Distance for High Level RNA Secondary Structure Comparison, IEEE/ACM Transactions on Computational Biology and Bioinformatics, Vol. 2, No. 1, pp. 3-14, 2005. • Batini, C., Lenzerini, M. and Navathe, S.B., A comparative analysis of methodologies for database schema integration, ACM Comput Surv, 18(4), pp. 323–364, 1986. • Bergamaschi, S., Castano, S. and Vincini, M., Semantic integration of semistructured and structured data sources, ACM SIGMOD Record, 28(1), pp. 54–59, 1999. • Berners-Lee, T., Hendler, J. and Lassila, O., The semantic web, Sci. Am, 284(5), pp. 34–43, 2001. • Bhavsar, V.C., Boley, H. and Yang, L., A Weighted-Tree Similarity Algorithm for Multi-Agent Systems in e-Business Environments, Computational Intelligence, 20(4), pp.584-602, 2004. • Boley, H., Bhavsar, V.C., Hirtle, D., Singh, A., Sun, Z. and Yang, L., A match-making system for learners and learning Objects, Learning & Leading with Technology, International Society for Technology in Education, Eugene, OR, 2(3), pp. 171–178, 2005. • Boley, H., Object-Oriented RuleML: User-level roles, URI-grounded clauses and order-sorted terms, Springer-Verlag, Heidelberg, LNCS-2876, pp. 1-16, 2003. • Bouquet, P., Serafini, L. and Zanobini, S., Semantic coordination: A new approach and an application. Proceedings of the International Semantic Web Conference (ISWC), pages 130–145, 2003. • Castano, S., Antonellis, D.V. and Vimercati, S., Global viewing of heterogeneous data sources, IEEE Trans Data Knowl Eng, 13(2), pp. 277–297, 2001. • Deo, N., Graph Theory with Applications to Engineering and Computer Science, Prentice Hall of India Private Limited, twelfth printing, April 1997. • Do, H.H. and Rahm, E., COMA – A system for flexible combination of schema matching approaches, Proceedings of 28th International Conference on Very Large Databases (VLDB), Hong Kong, pp. 610-621, 2002. • Do, H.H., Melnik, S. and Rahm, E., Comparison of Schema Matching Evaluations, Web, Web-Services, and Database Systems, pp. 221-237, 2002. • Doan, A.H., Domingos, P. and Levy, A., Learning source descriptions for data integration, Proc. WebDB Workshop, pp. 81–92, 2000. • Elmagarmid, A.K. and Pu, C., Guest editors’ introduction to the special issue on heterogeneous databases, ACM Comput Surv, 22(3), pp. 175–178, 1990. • Giunchiglia, F. and Zaihrayeu, I., Making peer databases interact - a vision for an architecture supporting data coordination. Proceedings of the International workshop on Cooperative Information Agents (CIA), pages 18–35, 2002. • JDOM [homepage of JDOM] [on line] available at:http://www.jdom.org [accessed 2006-3-1] • Jin, J., Sarker, B.K., Bhavsar, V.C., Boley, H. and Yang, L., Towards a Weighted-Tree Similarity Algorithm for RNA Secondary Structure Comparison, Proceedings of the 8th International Conference on High Performance Computing in Asia Pacific Region (HPC-Asia 2005), IEEE Computer Society, ISBN 0-7695-2486-9, pp. 639-644, Nov 30-December 3, 2005. • Kifer, M., Lausen, G., Kifer, M. and Wu, J., Logical Foundations of Object-Oriented and Frame-Based Languages, JACM, Vol.43, No.2, 741-843, 1995. • Lassila, O. and Swick, R.R., Resource Description Framework (RDF) Model and Syntax Specification, Recommendation REC-rdf-syntax-19990222, W3C, February 1999. • Li, W. and Clifton, C., Semantic integration in heterogeneous databases using neural networks, Proc. 20th Int. Conf On Very Large Data Bases, pp. 1–12, 1994.
References (cont’d) • Lu, S., A Tree-to-Tree Distance and Its Application to Cluster Analysis, IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. PAMI-1, No.2, April 1979. • Madhavan, J., Bernstein, P. and Rahm, E., Generic schema matching using Cupid, Proceedings of 27th International Conf. on Very Large Data Bases (VLDB’01), Rome, Italy , pp. 49-58, 2001. • Melnik, S., Molina, H.G. and Rahm, E., Similarity flooding: A versatile graph matching algorithm, Proceedings of Eighteenth International Conference on Data Engineering, San Jose, California, pp. 117-128, February 2002. • Miller, R., Ioannidis, Y.E. and Ramakrishnan, R., Schema equivalence in heterogeneous systems: bridging theory and practice, Inf. Syst. 19(1):3–31, 1994. • Milo, T. and Zohar, S., Using schema matching to simplify heterogeneous data translation, Proc. 24th Int. Conf On Very Large Data Bases, pp. 122–133, 1998. • Mitra, P., Wiederhold, G. and Jannink, J., Semiautomatic integration of knowledge sources, Proc. of the 2nd Int. Conf. On Information FUSION'99, Sunnyvale, USA, 1999. • Noetzel, A.S. and Selkow, S.M., An analysis of the general tree-editing problem, In D. Sankoff and J.B. Kruskal, editors, Time Warps, String Edits, and Macromolecules: The Theory and Practice of Sequence Comparison, pages 237-252, Addison-Wesley, Reading, MA, 1983. • Palopoli, L., Sacca, D. and Ursino, D., Semi-automatic, semantic discovery of properties from database schemas. Proc Int. Database Engineering and Applications Symp. (IDEAS), IEEE Comput, pp. 244–253, 1998. • Parent, C. and Spaccapietra, S., Issues and approaches of database integration, CACM, 41(5), pp. 166–178, 1998. • Rahm, E. and Bernstein, P., A Survey of Approaches to Automatic Schema Matching, VLDB Journal, 10(4), pp. 334-350, Dec. 2001. • Rahm, E., Do, H.H., Maßmann, S., Matching Large XML Schemas, SIGMOD Record 33(4), pp. 26-31, 2004. • Shasha, D., Wang, J. and Zhang, K., Treediff: Approximate Tree Matcher for Ordered Trees, http://www.cs.nyu.edu/cs/faculty/shasha/papers/tree.html, October 25, 2001. • Sheth, A.P. and Larson, J.A., Federated database systems for managing distributed, heterogeneous, and autonomous databases, ACM Comput Surv, 22(3), pp. 183–236, 1990. • Shvaiko, P. and Euzenat, J., A Survey of Schema-based Matching Approaches. Journal on Data Semantics (JoDS), IV, LNCS 3730, pp. 146-171, 2005. • Wagner, R.A. and Fischer, M.J., The string-to-string correction problem, J. ACM, Vol. 21, No. 1, pp. 168-173, 1974. • Wang, J.T.L., Zhang, K. and Chirn, G.W., Algorithms for Approximate Graph Matching, Inf. Sci., 82(1-2), pp. 45-74, 1995. • Yang, L., Sarker, B.K., Bhavsar, V.C. and Boley, H., A Weighted-Tree Simplicity Algorithm for Similarity Matching of Partial Product Descriptions, Proceedings of ISCA 14th International Conference on Intelligent and Adaptive Systems and Software Engineering, Toronto, pp. 55-60, 2005. • Yang, L., Sarker, B.K., Bhavsar, V.C. and Boley, H., Range Similarity Measures between Buyers and Sellers in e-Marketplaces, Proceedings of the Second Indian International Conference on Artificial Intelligence, Pune, pp. 2559-2572, Dec 20-22, 2005. • Zhang, K. and Shasha, D., Simple fast algorithms for the editing distance between trees and related problems, SIAM J. Comput, Vol.18, No.6, pp.1245–1262, 1989. • Zhang, K., Shasha, D. and Wang, J.T.L., Approximate Tree Matching in the Presence of Variable Length Don’t Cares, J. of Algorithms, Vol. 16, No. 1, pp. 33-66, 1994. • Zhang, K., Wang, J.T.L. and Shasha, D., On the Editing Distance between Undirected Acyclic Graphs and Related Problems, Combinatorial Pattern Matching (CPM), pp. 395-407, 1995.
Thank you! Mercy! 谢谢!