Download

1 / 41
430 likes | 742 Views
Bases de Datos Distribuidas. 1.- Introducción 2.- Ventajas de las Bases de Datos Distribuidas 3.- Desventajas de las Bases de Datos Distribuidas 4.- Funcionalidades adicionales de las BDD 5.- Fragmentación de los datos en BDD 6.- Replicación y asignación de los datos.

E N D
Bases de Datos Distribuidas 1.- Introducción 2.- Ventajas de las Bases de Datos Distribuidas 3.- Desventajas de las Bases de Datos Distribuidas 4.- Funcionalidades adicionales de las BDD 5.- Fragmentación de los datos en BDD 6.- Replicación y asignación de los datos
Bases de Datos Distribuidas 7.- Tipos de sistemas de BDD 8.- Procesamiento de consultas en BDD 9.- Control de concurrencia y recuperación 10.- Recuperación distribuida 11.- Relación entre las BDD y la arquitectura cliente-servidor 12.- Oracle como BDD
Introducción Las BDD surgen de 2 tecnologías en auge: Bases de datos y redes de comunicaciones. A finales de los `80 se empezó a tender hacia la Descentralización y autonomía de procesos. Una BDD está construida sobre una red de comunicaciones, por lo que la información de la BD está repartido entre los diferentes sitios que forman la red. Una BDD es un cjto. de BD interrelacionadas lógicamente, y distribuidas a través de la red de computadoras.
Introducción El SGBDD maneja todas las BDD haciendo que la distribución de los datos sea transparente para el usuario. Tipos de arquitecturas multiprocesador: Memoria compartida: múltiples procesadores que comparten la MP. Disco compartido: múltiples procesadores que comparten almacenamiento secundario pero no la MP.
Introducción Las arquitecturas mencionadas anteriormente comparten datos sin la necesidad de redes de comunicación. Se les conoce como SGBD paralelas, en lugar de SGBDD. Hay otro tipo de arquitectura: arquitectura con nada compartido. En esta arquitectura los procesadores no comparten MP, ni almacenamiento secundario y comparten la información por medio de redes de alta velocidad. En esta arquitectura tiene que haber simetría y homogeneidad en los nodos, por lo que no es una BDD.
Sistema de computación 1 Sistema de computación 2 BD BD CPU CPU MEMORIA MEMORIA CONMUTADOR Sistema de computación n BD CPU MEMORIA Fig. 1. Arquitectura con nada compartido Introducción
BD1 BD2 Central (madrid) Zaragoza Logroño Red de comunicaciones Barcelona SanSebastián Fig. 2.Arquitectura con BD centralizada Introducción
BD1 BD2 Logroño San Sebastián Red de comunicaciones Zaragoza DB5 Madrid Barcelona DB3 DB4 Introducción Fig. 3. Arquitectura verdadera de BDD
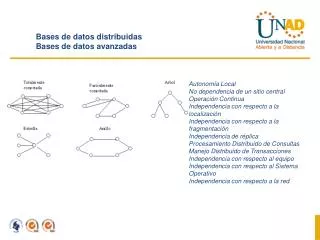
Introducción Las BDD tienes que cumplir las 12 reglas siguientes: a) Autonomía local. b) No dependencia de un sitio central. c) Operación continua. d) Independencia con respecto a la localización. e) Independencia con respecto a la fragmentación. f) Independencia de réplica.
Introducción g) Procesamiento distribuido de consultas. h) Manejo distribuido de transacciones. i) Independencia con respecto al equipo. j) Independencia con respecto al SO. k) Independencia con respecto a la red. l) Independencia con respecto al SGBD.
Ventajas de las BDD a) Gestión de datos distribuidos con diferentes niveles de transparencia: 1.- Transparencia de red o de distribución. 2.- Transparencia de réplica. 3.- Transparencia de fragmentación. b) Incremento de la fiabilidad y disponibilidad. c) Mejora del rendimiento. d) Expansión de la BD más sencilla.
Desventajas de las BDD • Las desventajas frente a las BD monolíticas son: • a) Procesamiento de consultas. • b) Administración del catálogo. • c) Propagación de actualizaciones. • d) Recuperación. • e) Concurrencia
Funciones adicionales de las BDD Un SGBDD además de las funciones de un SGBD tiene que realizar: a) Mantenimiento de la pista de los datos. b) Procesamiento de consultas distribuidas. c) Gestión de transacciones distribuidas. d) Gestión de datos replicados.
Funciones adicionales de las BDD e) Recuperación de las Bases de Datos Distribuidas. f) Seguridad. g) Gestión del catálogo distribuido. Para la realización de las funcionalidades extra, hace falta un “buen” diseño ya que de él depende el rendimiento de nuestras transacciones y consultas.
Fragmentación de los datos Consiste en la división de la información de la BD en partes más pequeñas que se puedan repartir entre los nodos. La decisión de dónde llevar las diferentes partes influirá notoriamente en el rendimiento global de nuestra BDD. En un BD relacional por ej. se puede dividir por relaciones. Existen diferentes formas de fragmentación: a) Fragmentación horizontal: Subdivisión por tuplas de una relación. Con la fragmentación horizontal derivada se utilizan las claves extranjeras.
Fragmentación de los datos b) Fragmentación vertical: subdivisión de la relación por atributos de ésta. En esta fragmentación se conservan todas tuplas de la relación. c) Fragmentación mixta: es una mezcla de los dos tipos anteriores. Se divide la relación en tuplas y se cogen sólo los atributos que nos interesen. El esquema de fragmentación es la definición de un conjunto de fragmentos que incluye todos los atributos y tuplas de la BD El esquema de asignación describe qué fragmentos van a qué sitio de nuestra BDD.
Replicación y asignación de los datos Método eficaz para mejorar la disponibilidad de la información en nuestra BDD. Replicación total: copia completa de la BD en cada sitio. Gran rendimiento en consultas, pero muy malo en actualización e inserción. No replicación: no copias redundantes en ningún sitio de la BDD Amplio abanico de posibilidades. El esquema de replicación es la forma de cómo se van a replicar los datos. Distribución de los datos es el proceso de asignación de los fragmentos a cada nodo de nuestro sistema.
Tipos de sistemas de BDD Grado de homogeneidad: depende del hardware y software de cada nodo de nuestro sistema. Autonomía local: si el sitio local puede trabajar como un sistema autónomo o no. Hay sistemas sin autonomía local (poseen un esquema conceptual) y hay sistemas federados. Los sistemas federados son aquellos que pueden trabajar de forma autónoma. Tienen las siguientes características: a) Diferencias en modelos de datos. b) Diferencias en restricciones. c) Diferencias en los lenguajes de consulta.
Tipos de sistemas de BDD Puede darse heterogeneidad semántica cuando hay diferencia entre en el significado, interpretación o uso de ciertos datos. Para la autonomía de diseño se puede escoger libremente entre una serie de parámetros: a) Universo de discurso desde el que se representan los datos. b) Representación y nombres. c) Entendimiento, significado e interpretación subjetiva de los datos.
Tipos de sistemas de BDD d) Restricciones de política y transacción. e) Derivación de transacciones. La autonomía de comunicación se refiere a la habilidad de un sistema componente de decidir si quiere comunicarse con otro sistema componente o no. La autonomía de ejecución consiste en poder ejecutar operaciones sin la intromisión de operaciones de sistemas externos, y también es la capacidad de decidir el orden de ejecución de las operaciones. La autonomía de asociación es la capacidad de un nodo de decidir si quiere compartir su funcionalidad y recursos con otros sistemas.
Procesamiento de consultas en BDD 1.- Costos de la transferencia de datos en consultas distribuidas Además de los métodos clásicos de optimización hay que tener en cuenta otros factores como la velocidad de la red, por lo que se disminuye el número de transferencias por esta. La semireunión es una operación que da buen resultado para consultas distribuidas. 2.- Consultas por semireunión Consiste en reducir al máximo el número de tuplas de una relación, antes de transferirla por la red.
Procesamiento de consultas en BDD La idea es enviar solo el atributo de reunión, y recogerlo más tarde junto con los atributos que queramos de la otra relación. 3.- Descomposición de actualizaciones y consultas. Debe existir un módulo de descomposición de consultas para poder enviar cada trozo de la consulta al sitio que le corresponda. Una vez recibida la información la fusiona formando el resultado total.
Control de concurrencia y recuperación de BDD Surgen problemas añadidos: a) Manejar múltiples copias de los elementos de datos. b) Fallo de sitios individuales. c) Fallo en enlaces de comunicación. d) Confirmación distribuida. e) Bloqueo mortal distribuido.
Control de concurrencia y recuperación de BDD Concurrencia basada en una copia distinguida. Los bloqueos y desbloqueos se envían al sitio que contiene la copia. Métodos que utilizan la copia distinguida: a) Técnica de sitio primario. b) Sitio primario con sitio de respaldo. c) Técnica de copia primaria. Si se produce una caída del sitio coordinador, el sistema tiene que ser capaz de escoger a otro para que realice la función.
Control de concurrencia y recuperación de BDD Control de concurrencia por votación. No existe copia distinguida. Cada solicitud se envía a todos los sitios de la BDD que incluyan una copia del elemento a bloquear. Si la mayoría de los sitios otorgan el bloqueo a la transacción está informará de su estado al resto de sitios. Si no se otorga el bloqueo, se cancelará la solicitud de la transacción e informará de su estado al resto de sitios.
Recuperación distribuida Multitud de problemas, como por ej. saber si un sitio está caído, ya que: a) puede estar caído. b) puede haber fallado la comunicación de subida c) puede haber fallado la comunicación de bajada Los problemas que surgen pueden generar mucho tráfico en la red. La confirmación distribuida es otro problema: Cuando una transacción está actualizando datos en varios sitios, no puede confirmarse hasta asegurarse de que el efecto de la transacción no se puede perder en ningún sitio.
Relación entre las BDD y la arquitectura cliente-servidor El software se divide en 3 módulos: a) El servidor: Gestiona los datos locales. b) El cliente: Realiza las peticiones a más de un sitio y maneja los interfaces de usuario. c) El software de comunicación: proporciona las primitivas de comunicación.
Oracle como BDD Se divide en cliente (front-end) y servidor (back-end). El cliente ejecuta las peticiones y el servidor ejecuta las sentencias SQL y devuelve los resultados. La arquitectura cli-serv proporciona transparencia de localización. Utiliza el mecanismo de confirmación en dos fases para el control de las transacciones. El proceso background RECO resuelve el resultado de las transacciones distribuidas que se interrumpen con un commit. Para fallos de larga duración Oracle permite al ABD confirmar o deshacer manualmente cualquier transacción en duda.
Oracle como BDD Cada nodo puede ser tanto un cliente, como un servidor, como ambas cosas a la vez. Oracle utiliza el software de red Net8. Las direcciones de red dentro de un sistema distribuido son jerárquicas. Ofrece dos métodos de replicación: a) Básica: Réplicas de sólo lectura. b) Avanzada: Réplicas R/W. Por medio de Oracle Open Gateways se permite el acceso a BD que no sean Oracle, formándose así redes heterogéneas.