Download

1 / 17
170 likes | 287 Views
A New Server Selection Strategy for Reliable Server Pooling in Widely Distributed Environments. Table of Contents. What is Reliable Server Pooling? Prototype Demonstration Terminology and Protocols Motivation and Application Scenarios The Challenge on Network Delay on Server Selection

E N D
A New Server Selection Strategyfor Reliable Server Pooling in Widely Distributed Environments
Table of Contents • What is Reliable Server Pooling? • Prototype Demonstration • Terminology and Protocols • Motivation and Application Scenarios • The Challenge on Network Delay on Server Selection • The Least Used with Degradation Policy • Evaluation • Conclusion and Outlook Thomas Dreibholz's Reliable Server Pooling Page http://tdrwww.iem.uni-due.de/dreibholz/rserpool/
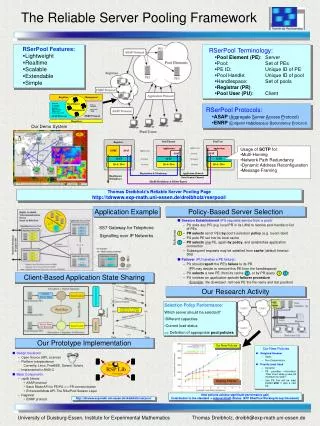
What is „Reliable Server Pooling“?Prototype Demonstration
Reliable Server Pooling (RSerPool) • Terminology: • Pool Element (PE): Server • Pool: Set of PEs • PE ID: ID of a PE in a pool • Pool Handle: Unique pool ID • Handlespace: Set of pools • Pool Registrar (PR) • Pool User (PU): Client • Support for Existing Applications • Proxy Pool User (PPU) • Proxy Pool Element (PPE) • Protocols: • ASAP (Aggregate Server Access Protocol) • ENRP (Endpoint Handlespace Redundancy Protocol)
Server Selection Rules(Pool Policies) • What is a Pool Policy? • A rule for the selection of the PEs • Defined in our IETF Working Group draft (draft-ietf-rserpool-policies-07.txt) • Application of Policies • Registrar: Creates PE list upon request by PU • Pool User: Selection of a PE from the list • Both according to the pool policies (pool-specific!) • Non-Adaptive Policies • Stateless: Random (RAND) • Stateful: Round Robin (RR) (Default policy, must be supported) • Adaptive Policy • Least Used (LU) • Load definition is application-specific! • Round robin among multiple least-loaded PEs
The Challenge of Network Delay on Server Selection • Challenge of Least Used • Load states get out of date, due to • Network latency • Cache • Solution: Least Used with Degradation (LUD) • Policy Information: • Load = Current Load (obvious) • Load Increment = How much is load increased by a new request? • Select PE, which has lowest sum of (Load + Load Increment) • Round robin among equal-valued PEs • Upon selection: • Increment load by load increment • Incrementation only local on selection component (i.e. registrar and PU's cache)! • Upon update: • Load is reset to latest known load state
The Application Model • Server • PE Capacity • Shared among sessions (multi-tasking principle) • Client • Requests are generated • Request Size (effort) • Request Interval (frequency) • Waiting queue for requests • Sequential processing • System Utilization • PU:PE Ratio • Provisioning for certain Target Utilization, e.g. 80%
Performance Metrics • Provider's Perspective “Does my server capacity gain revenue?” Average Utilization of server resources [%] • User's Perspective “How much time is needed to process my requests?” • Avg. Handling Speed [% of average server capacity] • Depends on: • Queuing • Startup • Server
Handling Speed Increasing the Network Delay -A Proof of Concept • Example setup as a proof of concept • Network latency reduces the handling speed ... • ... but with LUD, there is a significant speed benefit compared to LU • More investigations necessary • Workload parameters • Number of registrars • Cache
Utilization Handling Speed LU, Req.Int=10s (critical!) Variation of Workload Parameters:PU:PE Ratio • Small PU:PE ratio is critical (high per-PU workload) • LUD achieves significant performance improvement over LU
Utilization Handling Speed Variation of Workload Parameters:Request Interval • Small request interval is critical (especially for small PU:PE ratio!) • For PU:PE ratio > 1, LUD again achieves a significant improvement
Handling Speed Increasing the Number of Registrars • Handlespace synchronization • Necessary to cope with PR failures • Additional load update latency • Results: • LUD again achieves a significant benefit over LU ... • ... for realistic number of PRs (less than 10)
Handling Speed Using the PU-Side Cache • Cache at the PU: • Stores partial, temporary subset of the handlespace • Reduces number of PR queries • Contents get out of date • Results: • Again, LUD outperforms LU
Conclusion and Outlook • Conclusion • RSerPool is the IETF's upcoming standard for service availability • Network delay leads to out-of-date load states for Least Used policy • Least Used with Degradation (LUD) • Local increment upon selection, until update arrives • Improved system performance, especially for critical workload parameter settings • Future Work • From simulation to reality: • Tests with our prototype implementation in the PlanetLab • First results already available [KiVS2007] • Security analysis and robustness against DoS attacks
Thank You for Your Attention!Any Questions? Visit Our Project Homepage: http://tdrwww.iem.uni-due.de/dreibholz/rserpool/ Thomas Dreibholz, dreibh@iem.uni-due.de To be continued ...
The RSerPool Protocol Stack • Aggregate Server Access Protocol (ASAP) • PR PE: Registration, Deregistration and Monitoring by Home-PR (PR-H) • PR PU: Server Selection, Failure Reports • Endpoint Handlespace Redundancy Protocol (ENRP) • PR PR: Handlespace Synchronisation ASAP is IETF's first Session Layer standard!
Motivation • Motivation of RSerPool: • Unified, application-independent solution for service availability • Not available before => Foundation of the IETF RSerPool Working Group • Application Scenarios for RSerPool: • Main motivation: Telephone Signalling (SS7) over IP • Under discussion by the IETF: • Load Balancing • Voice over IP (VoIP) with SIP • IP Flow Information Export (IPFIX) • ... and many more! • Requirements for RSerPool: • “Lightweight” (low resource requirements, e.g. embedded devices!) • Real-Time (quick failover) • Scalability (e.g. to large (corporate) networks) • Extensibility (e.g. by new server selection rules) • Simple (automatic configuration: “just turn on, and it works!”)