Download
1 / 20
200 likes | 367 Views
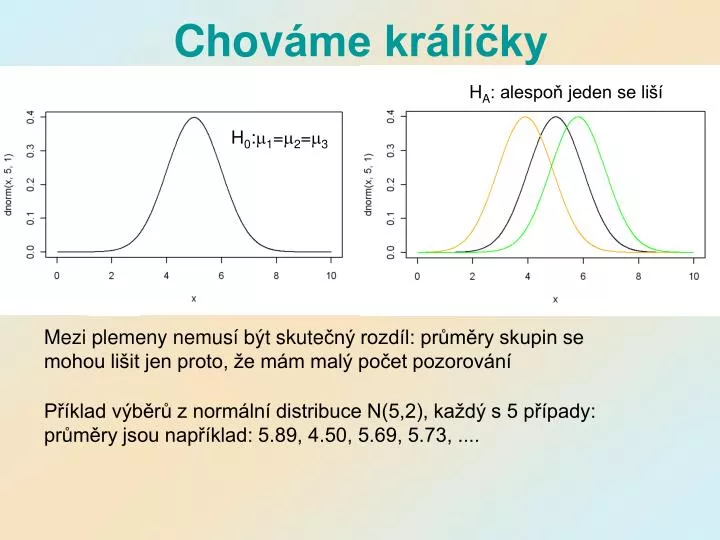
Chov áme králíčky. H A : alespoň jeden se liší. H 0 : m 1 = m 2 = m 3. Liší se tato tři králičí plemena hmotností?. 3, 3, 4, 5, 5. 4, 4, 6, 5, 6. 7, 5, 6, 5, 7. Mezi plemeny nemusí být s kute čný rozdíl: průměry skupin se mohou lišit jen proto, že mám malý počet pozorování.

E N D
Chováme králíčky HA: alespoň jeden se liší H0:m1=m2=m3 Liší se tato tři králičí plemena hmotností? 3, 3, 4, 5, 5 4, 4, 6, 5, 6 7, 5, 6, 5, 7 Mezi plemeny nemusí být skutečný rozdíl: průměry skupin se mohou lišit jen proto, že mám malý počet pozorování Příklad výběrů z normální distribuce N(5,2), každý s 5 případy: průměry jsou například: 5.89, 4.50, 5.69, 5.73, ....
Zas ti králíci ... SStot= Celková suma čtverců Total sum of squares SStot rozptyl kolem společného průměru Skupinová (modelová) suma čtverců Among-group sum of squares SSG rozptyl hodnot předpovídaných plemenem kolem celkového průměru Residuální suma čtverců Error sum of squares SSe rozptyl hodnot kolem průměrů předpovídaných plemenem SStot= (3-5)2+(3-5)2+(4-5)2+(5-5)2+ (5-5)2+(4-5)2+(4-5)2+...+(7-5)2= 22 SSG= (4-5)2+(4-5)2+(4-5)2+(4-5)2+ (4-5)2+(5-5)2+(5-5)2+...+(6-5)2= 10 SSe= (3-4)2+(3-4)2+(4-4)2+(5-4)2+ (5-4)2+(4-5)2+(4-5)2+...+(7-6)2= 12 SSG+ SSe Jaký počet nezávislých informací jsme použili? DFtot=počet pozorování – 1 (pro celkový průměr)= 14 DFG=počet skup. průměrů – 1 (pro celkový průměr)= 2 DFe=počet pozorování – počet nezávislých průměrů= 12 MStotjecelková variance = 22/14 = 1.5714 MSGjeobjasněná variance = 10/2 = 5.0 MSejeneobjasněná variance = 12/12 = 1.0
A pořád ještě králíci ... MSG a MSe odhadují mezi-skupinovou a vnitro-skupinovou variabilitu na srovnatelné škále Pokud platí nulová hypotéza, měly by být obě variability zhruba stejné – jejich poměr lze popsat F distribucí, se dvěma parametry: DFG a DFe V našem příkladě F = 5.0 / 1.0 = 5.0 Pravděpodnost, že takto velkou nebo větší hodnotu „si vytáhnu“ z F2,12 distribuce je asi 0.0263 Zamítám tedy H0 ve prospěch HA s p=0.0263
ANOVA • Použitá metoda je nejjednodušším typem analýzy variance (Analysis of variance= ANOVA) • Tento typ se nazývá analýza variance jednoduchého třídění (= jednocestná ANOVA)one-way ANOVA • případně single-factor ANOVA
Model pro one-way ANOVA • Nulovou hypotézu pro případ jednocestné analýzy variance se 3 skupinami jsme popsali takto: H0: m1 = m2 = m3 • Nebo vytvoříme model, popisující naše data v případě, že platí alternativní hypotéza HA: Xij = m +ai + eij H0: a1 = a2 = a3= 0 Společná střední hodnota “posunutí” průměru i-téskupiny proti společnému průměru m náhodná variabilita N(0, σ2)nezávislá na α
Shoda variancí Test shody variancí mezi skupinami: Bartlettův test
Liší se všechna plemena? • Zamítnutí H0 může znamenat: m1 = m2≠ m3 m1≠m2 = m3 m1≠m2≠m3 • Jak zjistím, co z toho je správně? • Problém – opakované použití stejných údajů: rychlý růst chyby I. typu • Mnohonásobná porovnání (multiple comparisons = post-hoc compar.)
Tukey-ho test • Používáme testovou statistiku q podobnou statistice z dvouvýběrového T-testu • Standardní chyba rozdílu průměrů je: • Smysl podobný jako u T statistiky, ale q nemá T distribuci!
Tukey v programu Statistica Výstup může vypadat různě:
Proč nesrovnávat po dvojicích a nepoužít řadu t-testů? PlemenoC Plemeno B Plemeno A
Pokud máme k skupin (a srovnáváme k průměrů) • Provádíme k(k-1)/2 testů Pravděpodobnost chyby I. druhu je α v každém z nich • Šance, že uděláme alespoň jednu chybu prvního druhu roste s počtem porovnávaných průměrů
Dunnetův test • Pojem kontrola (control treatment) • Dunnetův test používáme v případě, že chceme porovnávat jednotlivé hladiny faktoru jen proti kontrole • V programu Statistica provedeme takto:
Pokud mám dvě skupiny,mám užít ANOVA nebo t-test ? Je to jedno, P vyjde v obou případech zcela shodné Hodnota F statistiky z ANOVA bude druhou mocninou hodnotyT z t-testu
Síla testu • Roste s počtem pozorování ve skupině • Roste s vyvážeností skupin(balanced design) • Klesá s rostoucím počtem skupin (nesnažte se porovnávat všechno možné při malém počtupozorování ve skupině!)
Narušení předpokladů –robustnost testu • Robustnost k narušení normality stoupás počtem pozorování ve skupině • Robustnost k narušení homogenity variancí výrazně klesá při nevyvážených počtech ve skupinách
Pevné a náhodné efekty • Králičí příklad představoval problém, ve kterém faktor (nezávislá proměnná) plemeno obsahoval hladiny, které nás konkrétně zajímaly – podobně hnojené vs. nehnojené plochy, srovnání vlivu několika druhů léků. Plemeno, hnojení, druh léku jsou faktory s pevným efektem (fixed effect factor) • V jiných situacích: porovnáváme variabilitu hodnot mezi kategoriemi vs. uvnitř kategorií: liší se hmotnost plodů mezi mateřskými rostlinami, tj. existuje systematický vliv rostliny? Konkrétní rostlina mne nezajímá, faktor rostlina odpovídá tzv. náhodnému efektu (random effect factor) • ANOVA s náhodnými efekty se označuje také jako model II ANOVA (x model I – s pevnými efekty). Mixed-effect ANOVA • V případě faktorů s náhodným efektem nemá smysl testovat rozdíly mezi konkrétními hladinami faktoru (nemá smysl dělat multiple comparisons)
Kruskal – Wallisův test • Neparametrický test – zobecnění Mann – Whitneyova testu pro tři a více (k) skupin • Původní hodnoty se nahradí pro každé pozorování hodnotou jeho pořadí • Ze součtu pořadí ve skupinách se pak spočítá testová statistika H, která by měla za platnosti H0 pocházet z c2 distribuce s k-1 stupni volnosti • Problém shodných hodnot (ties)
Kruskal – Wallisův test: příklad • Porovnáváme četnost určitého druhu hmyzu ve třech vegetačních patrech. • Původní data nahradíme pořadím






















