Download
1 / 1
10 likes | 101 Views
4 nd INTERNATIONAL SYMPOSIUM ON IMPRECISE PROBABILITIES AND THEIR APPLICATIONS, ISIPTA’05 Carnegie Mellon University, Pittsburgh, USA, July 20-23 2005. EVIDENTIAL MODELING FOR POSE ESTIMATION Fabio Cuzzolin, Computer Science Department, UCLA; Ruggero Frezza, DEI, Universita’ di Padova.

E N D
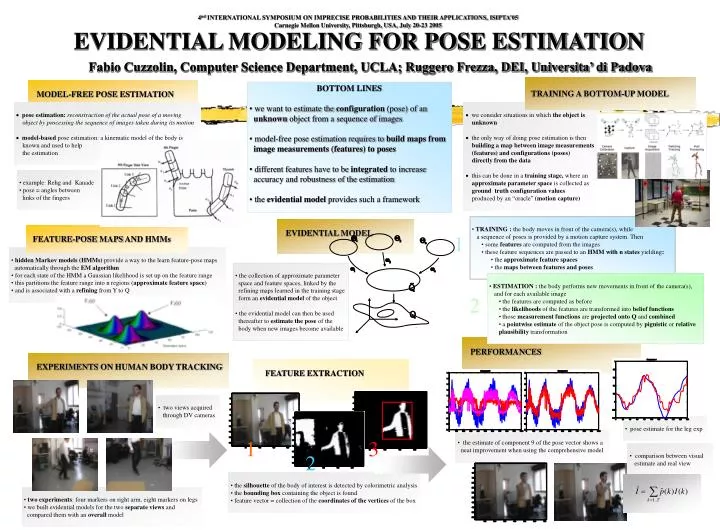
4nd INTERNATIONAL SYMPOSIUM ON IMPRECISE PROBABILITIES AND THEIR APPLICATIONS, ISIPTA’05 Carnegie Mellon University, Pittsburgh, USA, July 20-23 2005 EVIDENTIAL MODELING FOR POSE ESTIMATION Fabio Cuzzolin, Computer Science Department, UCLA; Ruggero Frezza, DEI, Universita’ di Padova TRAINING A BOTTOM-UP MODEL • MODEL-FREE POSE ESTIMATION • BOTTOM LINES • we want to estimate the configuration (pose) of an • unknown object from a sequence of images • model-free pose estimation requires to build maps from • image measurements (features) to poses • different features have to be integrated to increase • accuracy and robustness of the estimation • the evidential model provides such a framework • pose estimation: reconstruction of the actual pose of a moving object by processing the sequence of images taken during its motion • model-based pose estimation: a kinematic model of the body is known and used to help the estimation • we consider situations in which the object is unknown • the only way of doing pose estimation is then building a map between image measurements (features) and configurations (poses) directly from the data • this can be done in a training stage, where an approximate parameter space is collected as ground truth configuration values produced by an “oracle” (motion capture) • example: Rehg and Kanade • pose = angles between • links of the fingers • TRAINING : the body moves in front of the camera(s), while • a sequence of poses is provided by a motion capture system. Then • some features are computed from the images • these feature sequences are passed to an HMM with n states yielding: • the approximate feature spaces • the maps between features and poses • EVIDENTIAL MODEL • FEATURE-POSE MAPS AND HMMs 1 • hidden Markov models (HMMs) provide a way to the learn feature-pose maps • automatically through the EM algorithm • for each state of the HMM a Gaussian likelihood is set up on the feature range • this partitions the feature range into n regions (approximate feature space) • and is associated with a refining from Y to Q • the collection of approximate parameter • space and feature spaces, linked by the • refining maps learned in the training stage • form an evidential model of the object • the evidential model can then be used • thereafter to estimate the pose of the • body when new images become available • ESTIMATION : the body performs new movements in front of the camera(s), • and for each available image • the features are computed as before • the likelihoods of the features are transformedinto belief functions • those measurement functions are projected onto Q and combined • a pointwise estimate of the object pose is computed by pignistic or relative plausibility transformation 2 • PERFORMANCES • EXPERIMENTS ON HUMAN BODY TRACKING • FEATURE EXTRACTION • two views acquired • through DV cameras • pose estimate for the leg exp • the estimate of component 9 of the pose vector shows a • neat improvement when using the comprehensive model 1 3 • comparison between visual • estimate and real view 2 • the silhouette of the body of interest is detected by colorimetric analysis • the bounding box containing the object is found • feature vector = collection of the coordinates of the vertices of the box • two experiments: four markers on right arm, eight markers on legs • we built evidential models for the two separate views and • compared them with an overall model