Download

1 / 79
800 likes | 978 Views
A New Era in Processor Evolution. Dezső Sima Fall 2007. (Ver. 2.2). Dezső Sima, 2007. Foreword.

E N D
A New Era in Processor Evolution Dezső Sima Fall 2007 (Ver. 2.2) Dezső Sima, 2007
Foreword Beginning with second generation superscalars, the continuous, approximately 10-fold-per-decade increase of processor efficiency leveled off for reasons shown in Chapter I. Designers responded by massively rising clock frequencies at up to a 100-fold-per-decade rate in order to sustain an approximately 100-fold-per-decade performance increase. Such a rapid progress, however inevitably encountered its limits due to declining processor efficiency, increasing dissipation and skew in parallel buses, as shown in this Chapter. As a consequence, a decade long era of processor evolution, characterized by massively rising clock frequencies, ended in the last few years. The new era is heralded by multicore and multithreaded designs, as discussed in Chapters III. and IV.
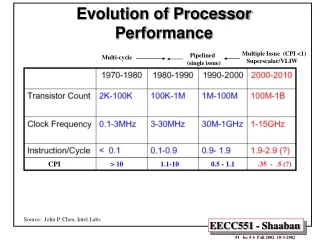
Contents 1. Processor performance 2. Efficiency of processors 3. Addressing the levelling off of processor efficiency 4. Aggressively raising clock frequency 5. The efficiency wall 6. The thermal wall 7. The skew wall 8. EPIC architectures/processors 9. The end of an era in processor evolution
1.1. Introduction (1) Relative performance Absolute performance Number of succesfully executed instructions/sec Relating the execution times of a benchmark program on the tested system to a reference system according to the following interpretation: Number of succesfully executed operations/sec (SIMD) fc: Clock frequency IPC: Instructions/cycle OPI: Operations/cycle E.g.: SPECint92, SPECint_base2000
1.1. Introduction (2) In general purpose applications: where: IPC : issued instructions per cycle η : number of successfully executed/issued instructions (efficiency of the speculative execution)
1.1. Introduction (3) In performance/efficiency studies: Theoretical interpretation: Pa Practical measurement: Pr ?
1.1. Introduction (4) If the following were true: In that case: I: Number of instructions in the application considered
1.1. Introduction (5) However: Figure 1.1.: Runtime ratios of the component programs of SPECint2000 Source: http://www.spec.org
1.1. Introduction (6) When comparing the performance of two systems: This estimation is useable in trend considerations.
1.1. Introduction (7) Comparing the efficiency of two systems:
SPECint92 Levelling off 10000 Prescott (2M) * P4/3200 * * Prescott (1M) * * 5000 P4/3060 Northwood B * * * P4/2400 * P4/2800 * P4/2000 * P4/2200 * P4/1500 * 2000 P4/1700 PIII/600 PIII/1000 1000 * * * PII/400 PIII/500 * PII/450 PII/300 * * 500 Pentium Pro/200 * ~ 100*/10 years Pentium/200 200 * * Pentium/166 * Pentium/133 Pentium/120 * Pentium/100 * 100 Pentium/66 * 486-DX4/100 * 50 486/50 * 486-DX2/66 * 486/33 * 486-DX2/50 20 * * 486/25 10 * 386/33 * 386/20 386/25 * 5 * 386/16 80286/12 2 * 80286/10 * 1 8088/8 * 0.5 8088/5 0.2 * Year 1990 2000 79 81 82 83 84 87 88 89 91 92 93 94 95 96 97 98 99 01 02 03 04 05 1980 85 86 1.2. Evolution of processor performance (1) Figure 1.2: Integer performance growth of Intel’s x86 processors
1.2. Evolution of processor performance (2) Figure 1.3: Integer performance growth (in general - 1) Source: X86-64 Technology White Paper, AMD Inc., Sunnyvale, CA, 2000
1.2. Evolution of processor performance (3) 3. Figure 1.4: Integer performance growth (in general - 2) Source: F. Labonte, www-vlsi.stanford.edu/group/chart/specInf2000.pdf
f SPECint_base2000/ 2. generation c superscalars Levelling off 1 Pentium Pro Pentium II 0.5 * * * * * Pentium III * * * ~10*/10 years Pentium 0.2 * * 486DX 0.1 * * 0.05 386DX 286 * 0.02 0.01 ~ ~ Year 78 83 1990 2000 92 02 1980 81 82 84 87 88 89 91 93 94 95 96 97 98 99 01 85 86 79 2.2. Growth of processor efficiency (1) Figure 2.1: Efficiency of Intel processors
2.2. Growth of processor efficiency (2) Figure 2.2: Growth of processor performance/efficiency (in general) Source: J. Birnbaum, „Architecture at HP: Two decades of Innovation”, Microprocessor Forum, October 14, 1997.
2.3. Contribution of raising processor efficiency to the growth of processor performance (up to the 2nd generation of superscalars) ? A második generációig az órafrekvencia és a hatékonyság növelése egyenlő arányban járultak hozzá a teljesítmény növeléséhez.
2.4. Sources of raising processor efficiency Increasing the word length 8/16 32 bit (286 386DX) Introducing and increasing temporal parallelism 1st and 2nd generation pipeline processors (386DX, 486DX) Introducing and increasing issue parallelism 1st and 2nd generation superscalars (Pentium, Pentium Pro)
2.5. Limit of raising processor efficiency (1) 2nd generationsuperscalars(wide superscalars) Processing width 4 RISC instructions/cycle ~3 CISC instructions/cycle Source: Wall: Limits of ILP, WRL TN-15, Dec. 1990 Figure 2.3: Processing width of 2nd generation (wide) superscalars vs extent of parallelism available in general purpose applications
2.5. Limit of raising processor efficiency (2) Figure 2.4: Growth of processor efficiency (in general)
2.5. Limit of raising processor efficiency (3) In general purpose applications: The width of 2nd generation superscalars already approaches the extent of available parallelism (ILP) Beginning with 2nd generation (wide) superscalarsthe sources of extensively raising processor efficiency became exhausted
Essentially widening the core by introducing EPIC architectures Aggresively raising clock frequency (Sections 4 – 7) (Section 8) Main road of evolution
4.1. Sources of raising clock frequencies (1) Raising clock frequency By scaling down the feature size in the manufacturing process By reducing the logic depth of pipline stages
4.1. Sources of raising clock frequencies (2) Figure 4.1: Evolution of Intel’s process technology Source: D. Bhandarkar: „The Dawn of a New Era”, 11. EMEA, May, 2006.
No of pipeline stages 40 P4 Prescott (~30) 30 * Pentium 4 (~20) Core Duo 20 * Conroe Pentium Pro Athlon-64 (14) (~12) (12) Athlon * Pentium K6 * * (6) 10 (6) (5) * * * Year 1995 2005 2000 1990 4.1. Sources of raising clock frequencies (3) Figure 4.2: Number of pipeline stages in Intel’s and AMD’s processors
4.1. Sources of raising clock frequencies (4) Figure 4.3: Max. logic depth of pipeline stages in processors (in terms of FO4) Source: F. Labonte www-vlsi.stanford.edu/group/chart/CycleFO4.pdf
4.2. Growth rate of clock frequencies (1) Figure 4.4: Growth of clock frequencies in Intel’s x86 line of processors
4.2. Growth rate of clock frequencies (2) Figure 4.5: Growth of clock frequencies (in general)
4.3. Implications of aggressively raising clock frequencies 4.3.1 Overview Ousting of major RISC families (4.3.2) Emerging limits of evolution (4.3.3)
4.3.2. Ousting of major RISC families (2) Figure 4.6: The shift in performance leadership between RISC and x86 lines
Cancelling of most major RISC lines, such as MIPS’s R-Lines, HP’s Alpha and PA lines, PowerPC Consortium’s PowerPC line 4.3.2. Ousting of major RISC families (2) 1995-2000: CISCs overtook the performance leadershipthen it is a more intrinsic task to raise fc from a higher value than from a lower one in the same rate 1997: Intel and HP unveiled IA-64/Merced as the next generation architecture/processor line
4.3.3. Emerging limits of evolution The efficiency wall (Section 5) The thermal wall (Section 6) The skew wall (Section 7)
5.1. Overview Basic reason: speed gap between the processor and the memory (it widens on higher frequencies)
5.1. Overview (2) Main appearances of the speed gap between the processor and the memory: DRAM latencies Memory transfer rates L2 cache latencies Transfer rates of processor buses
5.2. Speed gap between processor and memory (1a) Figure 5.1a: DRAM types
5.2. Speed gap between processor and memory (1b) Figure 5.1b: Latency of DRAM chips
5.2. Speed gap between processor and memory (1c) Figure 5.1c: System-level memory latency in x86-based PCs
5.2. Speed gap between processor and memory (1d) Figure 5.1d: Latency of DRAM chips (in clock cycles)
5.2. Speed gap between processor and memory (2) Figure 5.2: Relative transfer rate of memories (D: dual channel)
5.2. Speed gap between processor and memory (3) Figure 5.3: Latency of L2 caches
5.2. Speed gap between processor and memory (4) Figure 5.4: Relative transfer rates of processor buses
5.3. Efficiency of 3rd generation superscalars (1) 5.5: Efficiency of Intel’s Pentium III and Pentium 4 processors in general purpose applications
5.3. Efficiency of 3rd generation superscalars (2) Figure 5.6: efficiency of AMD’s Athlon, Athlon XP and Athlon 64 processors in general purpose applications
5.3. Efficiency of 3rd generation superscalars (3) Figure 5.7: Main aspects of the memory subsystem affecting core efficiency
5.3. Efficiency of 3rd generation superscalars (4) Figure 5.8: Contrasting the efficiency of Intel’s and AMD’s processors