Download

1 / 35
350 likes | 570 Views
Attractiveness Mapping. Modeling Land Use Preference. Outline. General Concepts in Attractiveness Modeling Refresher on Basic Raster Analysis Technical Implementation Issues. General Concepts & Methods in Attractiveness Modeling. Identify abstract best/worst conditions

E N D
Attractiveness Mapping Modeling Land Use Preference
Outline • General Concepts in Attractiveness Modeling • Refresher on Basic Raster Analysis • Technical Implementation Issues
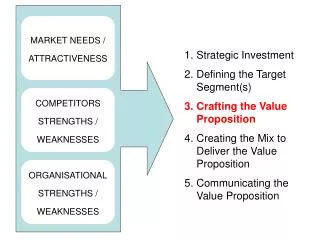
General Concepts & Methods in Attractiveness Modeling • Identify abstract best/worst conditions • Find geographical correlates for key factors • Develop Factor Maps • “Weight and rate” to Generate Single Output
Best Case / Worst Case • Identify abstract best/worst conditions • Important perspectives • Legal • Physical (natural amenities or dis-amenities) • Fiscal • Social services • Roleplay • developers • potential customers • citizens
Finding Geographic Correlates • Often, data you might most want are not available • Example: we have no land cost data layer • Two options • A) Ignore the factor entirely • B) Generate a reasonable spatial approximation • If Option B, how? • Generally, use qualitative and relative (versus quantitative or absolute) factors • E.g. likely land cost = low, medium or highvs. land cost <= $133,456.34/ha • Use proximity when appropriate • All other things being equalNear existing expensive might likely be expensive
Developing Factor Maps • Factor Maps • Express the main decision criteria spatially • Example: distance to nearest school, land price, travel time to employment • Should be in common vocabulary/units/scale • Here, since output is given 1-9 scale, use that • Depth versus Breadth and Spatial Autocorrelation • Better 3-5 spatially un-correlated factors than more • As in statistical regression, better to have few but solid explanatory variables • If sub-factors are needed, organize hierarchically • Example: Good Views = Ocean Views or Mountain Views, Ocean View = …
Raster GIS in ArcGIS A Spatial Analyst refresher
Raster Data Model • Rasters are conceptually similar to pixels • Instead of coding visual appearance as red/green/blue, encode spatial data • Common Types of Rasters • Categorical • e.g. land use code where 1 = urban, 2 = suburban • Continuous and representing measured data • e.g. elevation, where 1 = 1 meter above sea level, 2 = 2 meters, etc. • Continuous and representing preference • e.g “attractiveness to urban development” where 1 = least and 9 = most attractive
Operating on Rasters • Quick and easy for the computer • Generally, a set of raster GIS layers are designed to “line up” • Same overall spatial extent • Same raster grid cell size • Most operations involve simple algebra • Known as “map algebra” (Tomlin) • Just as 1 + 1 = 2 • 111 + 111 = 222111 111 222
Operating on Rasters 2 • “NoData” • critically important concept to understand in raster analysis • *despite* the name, “NoData” in many cases represents areas which the user wishes to treat as transparent, empty or background • Example • In creating raster layers from vector features, the areas on the map between features are coded as “NoData” • In this case, “absent”, “empty” or “background” are more appropriate conceptual meanings • A systematic measurement *was* made and the mapped feature was *not* found
Why Worry About “NoData”? • In ArcGIS map algebra, NoData is a special value • NoData + anything = NoData • Adding two maps in Spatial Analyst • Get only areas which didn’t include NoData in either map • For order-dependent overlay, need “Merge” command • In this case, “NoData” in top layer = transparent • Spread command (for distance calculations) only expands into NoData areas • In this instance, treated as “background”
Spatial Analyst Review • Enable the Extension • Show Toolbar • Adjust Options • Working directory – local writeable • Set Common Extent (bases civitas nova/study area) • Cell Size (25m to start) • Optionally, set mask to study_area_25m as well
Spatial Analyst Basics • Conversions • Reclassification • “Selection” in raster • Aggregation
Vector to Raster • Vector files, including CAD files, can be directly converted into raster • Only selected features are converted • Remember to clear selection first • Useful for converting only features meeting particular criteria (select first, then convert) • A Raster Value Column must be specified • These can be numeric (leading to predictable result) • Can also be text (leading to automatic generation of raster code values based on sequential position) • If you don’t have an appropriate pre-existing column, can simply create one • Example: create integer column named “one” with value calculated to equal “1” for all features
Conversion • Already have spatial geography you want, just need to extract & reformat • Example: • Have existing urban areas mapped from CAD, want all of these as a grid of “most attractive” with value of 1 • Create a new column and calculate an appropriate code value for it • e.g. create new integer column named “attractiveness” • Calculate value of “attractiveness” = 1 • Convert vector to raster using new column
Basic Spatial Relationships • Overlay • Sites inside “rural” zoning • Sites outside of city limits • Proximity • Adjacency • Near • Far
Arithmetic Overlays • Can Use “Raster Calculator” • NoData +-/* Anything = NoData • If NoData causing “dropouts” • Reclass NoData to “0” • Alternatively, can use “isnull()”
Example Map Algebra Overlays • Which urban areas are over 5% slope? • Have urban areas vectors, percent slope from base GIS • Strategy: • isolate desired components into “mask” maps (desired = 1, background = NoData) • Add maps in Map Calculator
Proximity Relationships in Raster GIS • Proximity • Adjacency • hard in raster – usually better to develop appropriate “near” criteria • Near/Far • Can be absolute or relative • Within 100m = near? • For relative, prior analysis can calculate distribution • (Relatively) near primary schools could be based on standard deviations of existing distances to primary schools
Simple Proximity • To start, we’ll use Euclidean Distance • Aka “as the crow flies” • Later, Cost Distance • Requires transit data grooming • Much more time consuming • Points to remember • Euc Distance spreads only into “NoData” cells • Objects are “0” distance from themselves • Buffers in raster usually a 2-step • Distance / Reclass
Technical Implementation Issues • Summarizing existing conditions • Categorical Variables • Continuous Variables • Expressing factors along equal scales • Using reclass or slice • Weighted overlays in ModelBuilder • General operation • Special cases
Summarizing existing conditions • Categorical Variables • Usually can use zonal statistics run on land use mask • Code land use as “1” • Run zonal stats against land use • Careful with “area” column sums – often wrong • Continuous Variables • Table summary stats ok • Can do in interface and record manually • Or can run with output to tables
Expressing factors along equal scales • Generally need to convert arbitrary and mixed units into evaluation units • Dealing with ranges • First, exclude unreasonable values • Then scale range of reasonable values • Flip if necessary (distance to water = good or bad?) • Dealing with absolutes • Usually can use reclassify operation • Example: if being adjacent to airport is a dealbreaker then recode distances to airport within “tooclose” range to “1”
Weighted overlays in ModelBuilder • In raster, could simply add factor maps • Example: • “closeness to school” rated 1..9 • “closeness to work” rated 1..9 • Map Calculator sum • Value 2 = furthest from school and work • Value 18 = closest to both school and work • In between = equally weighted index • Weighted overlay expresses two additional concepts • Some factors are more important than others • Some factors are “dealbreakers”
Weighted Overlay Demo • Imagine a “tourist restaurant” land use • Want to be visible to tourists • Don’t want to pay more than necessary for land • Best / Worst • Relatively low cost but highly visible location • Factor Maps • Factor 1 = Resort & port accessibility • Factor 2 = Land Cost
Tourist Restaurant • Travel time versus Traffic • Travel time • Can be across existing roads network • But since attractiveness models have roads as input, can also accommodate future road changes • Local & global accessibility measures in “road accessibility lines polyline” shape file • Accessibl = local (c. walking distance of 1.6m) • Accessib0 = regional • Values can be treated as an approximation of trips
Tourist Restaurant Accessibility • Subfactor 1: • Concept: Busy street • Metric: Scaled Global accessibility • Implementation: • Use the natural log (ln) to massage highly skewed data distribution of global accessibility • Take 9 equal interval slices • Higher values = busier = more attractive • Busiest sites at intersections, so use focal mean to summarize busyness in 3x3 cell area
Tourist Restaurant Accessibility • Subfactor 2: Travel time to nearest resort • (Not ideal because better might be average distance to all resorts within a theshold) • Implementation • Cost distance • From resorts • Over transit time surface • Base walking time = 4 miles/hour • Walking slope penalty = pcnt_slope^2 • Results ‘manually’ reclassified within MB
General Concepts in Urban Simulation • Basic Modeling Options • Endogenous • Attempt to simulate & predict market functions • Based on “bid-rent” theory and transportation cost • Exogenous • Attempt to predict distribution (but not amount) of given types of development • Form-based Models • Gravity Models • Diffusion-limited Aggregation