Download

1 / 28
280 likes | 385 Views
Allometric Crown Width Equations for Northwest Trees. Nicholas L. Crookston RMRS – Moscow June 2004. Introduction. Goals Data Source Model Form Statistical Model Analysis Results and discussion. Goals.

E N D
Allometric Crown Width Equations for Northwest Trees Nicholas L. Crookston RMRS – Moscow June 2004
Introduction • Goals • Data Source • Model Form • Statistical Model • Analysis • Results and discussion
Goals • To construct biologically and statistically sound models for inventoried tree species. • To provide models of varying complexity to support varying uses. • In FVS, predicted CW is used to estimate canopy cover.
Data Source • First installment of the Oregon and Washington CVS plots. • A grid system of 11,000 plots on public land. • 19 National Forests. • 250,000 observations of CW spread over 34 species.
Plot design • A cluster of 5 subplots centered on a grid point; further subdivided into plots of varying sizes where large trees were tallied on larger plots and small trees on smaller plots. • CW was measured on GSTs: • live trees, age ≥ 5, DBH ≥ 1 inch for softwood species and ≥ 3 inches for hardwood species.
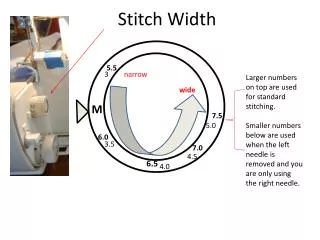
Crown width measurement: • “Measure a horizontal distance across the widest part of the crown, perpendicular to a line extending from the stake position [at plot center] to the tree bole.” • Recorded to the last whole foot.
Model Formulation • CW increases with DBH
Simple model form: • Based on the allometric relationship between CW and DBH. • Basic model fits observed trends.
Statistical model • Observations are not independent, GSTs from the same plot are more alike than trees are in general. • CW measurements are right-skewed; never less than zero but can be quite a bit larger than the mean
Statistical model (continued) • A generalized linear mixed effects model (GLMM) can be used to address the statistical properties. • CW is modeled as Gamma distributed with a log link function.
Statistical model (continued) • Two components of a GLMM are specified. • The systematic component is a linear combination of covariates, ηi =Xi β. • g() is the link function, it transforms the mean onto a scale where the covariates are additive. Source: Schabenberger and Pierce (2002, p. 313)
Statistical model (continued) • In my case, g is log and Xi β is the log transform of the allometric equation. • This is different than linear regression.
Statistical model (continued) • Applying the inverse link, exp(), we get the following: where is the predicted mean CW for tree i.
Statistical model (continued) • Include plot-level random effects. where ith tree on jth plot
Statistical model (continued) • Fitting was done with glmmPQL from R (Venables and Ripley 2002, p. 298). • McCulloch and Searle (2001, p. 283) have said that the development of PQL methods • have had “an air of ad hocery” • modern methods may be “better performing” • “have not been fully tested”
Statistical model (continued) • … McCulloch and Searle (2001, p. 283)… • get better as the conditional distribution of the response variable given the random effects gets closer to normal. • binary data are the worse case • The conditional distribution of the CW data does approach the normal. • The method seems to have worked well.
Statistical model (continued) • Alternatives to GLMM: • Directly fit the nonlinear model using nonlinear mixed effects. • Ignore the plot effects. • Fit the log transformed linear model. • GLMM addressed all the problems in a single step.
Statistical tests • The simple model was always acceptable (based on t-tests and theory). • The complex model was compared to the simple using a likelihood ratio test. This test requires nested models. • Individual terms in the complex model were tested using partial t-tests.
Statistical tests • AIC was also used. For nested models AIC and the likelihood ratio test will lead to the same conclusions, but they are based on different ideas. • An improvement in AIC of about 2 corresponds to a likelihood ratio test at the 0.05 level of significance.
Results • Species specific equations using of DBH are presented for 34 species. • Complex equations are presented for 29 species. • Predictor variables include • crown length (CL), • tree height (Ht), • plot basal area, • elevation, and • geographic location (National Forest).
Results • DBH is the most important predictor of CW • Implications of the complex equation: • CWs increase with DBH and CL but decrease with Ht when DBH and CL are also in the equation. • CWs are smaller at higher elevations (the one exception is western larch).
Results • Implications (continued) • CWs, generally, increase with density for shade tolerant species and decrease with density for some shade intolerant species. • The effect of density on CW was weak perhaps because density also influences other covariates.
Discussion • The allometric equation is better than recently published linear and polynomial equations. • The bias at the extremes of the distribution can be large. • When the equation is used to predict canopy cover, the bias in CW can imply a 10-20 percent bias in canopy cover.
Closing comments • Remember the basics. • I’m not sure the glammPQL was worth the effort, but I really like R. • The manuscript is in review at the online journal Forest Biometry, Modelling and Information Sciences.