Download

1 / 24
260 likes | 594 Views
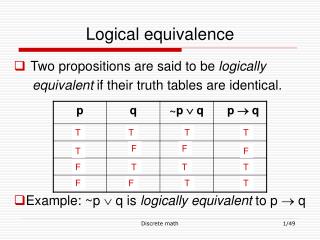
Equivalence Testing. Dig it!. Outline. Intro Two one-sided test approach Alternative: regular CI approach Tryon approach with “ inferential ” confidence intervals. Tests of Equivalence.

E N D
Equivalence Testing Dig it!
Outline • Intro • Two one-sided test approach • Alternative: regular CI approach • Tryon approach with “inferential” confidence intervals
Tests of Equivalence • As has been mentioned, the typical method of NHST applied to looking for differences between groups does not technically allow us to conclude equivalence just because we do not reject null • The observed p-value can only be used as a measure of evidence against the null, not for it • Having a small sample would allow us to the retain the null • Often this conclusion is reached anyway • Stated differently, absence of evidence does not imply evidence of absence • Altman & Bland,1995 • Examples of usage: • generic drug vs. established drug • efficacy of counselling therapies vs. standards
With our regular t-tests, to conclude there is a substantial difference you must observe a difference large enough to conclude it is not due to sampling error The same approach applies with equivalence testing To conclude there is not a substantial difference you must observe a difference small enough to reject that closeness is not due to sampling error from distributions centered on large effects Conceptual approach If the difference between means falls in this range, we would conclude the means belong to equivalent groups.
Two one-sided tests (TOST) • One method is to test the joint null hypothesis that our mean difference is not as large as the upper value of a specified range and not below the lower bound of the specified range of equivalence • H0a: μ1 - μ2> δ OR • H0b1: μ1 - μ2< -δ • By rejecting both of these hypotheses, we can conclude that | μ1 - μ2|< δ, or that our difference falls within the range specified
First we’d have to reject a null regarding a difference in which μ1 - μ2< -δ • Then reject a difference of the opposite kind (same size though)
Two one-sided tests (TOST) • Having rejected both, we can safely conclude the small difference we see does not come from a distribution where the effect size is too big to ignore
Tests of Equivalence • Specify a range? Isn’t that subjective? • Base it on: • Previous research • Practical considerations • Your knowledge of the scale of measurement
Example • Scores from a life satisfaction scale given to groups from two different cultures of interest • First specify range of equivalence δ • Say, any score within 3 points of another • Group 1: M = 75, s = 3.2, N = 20 • Group 2: M = 76, s = 2.4, N = 20
Example • H01: • H02: • By rejecting H01 we conclude the difference is less than 3 • By rejecting H02 we conclude the difference is greater than -3
Fuzzy yet? • Recall that the size difference we are looking for is one that is 3 units. • This would hold whether the first mean was 3 above the second mean or vice versa • Hence we are looking for a difference that lies in the μ1 – μ2 interval (-3,3), but can be said to be unlikely to have fallen in that interval ‘by chance’.
Worked out • H01 is rejected if -t ≤ -tcv, and H02 is rejected if t ≥ tcv • df = 20+20-2 = 38 • Here we reject in both cases (.05 level)1 and conclude statistical equivalence
The CI Approach • Another (and perhaps easier) method is to specify a range of values that would constitute equivalency among groups • -δ to δ • Determine the appropriate confidence interval for the mean difference between the groups • See if the CI for the difference between means falls entirely within the range of equivalency1 • If either lower or upper end falls beyond do not claim equivalent • This is equivalent to the TOST outcome
Using Inferential Confidence Intervals • Decide on a ranged estimate that reflects your estimation of equivalence (δ) • In other words, if my ranged estimate is smaller than this, I will conclude equivalence • Establish inferential CIs for each variable’s mean • Create a new range that includes the lower bound from the smaller mean, and the upper bound from the larger mean • Represents the maximum probable difference • See if this CI range (Rg) is smaller than the specified maximum amount of difference allowed to still claim equivalence (δ)
Previous example • Scores on the life satisfaction scale • First specify range of equivalence δ • Say, any score within 3 points of another • Group 1: M = 75, s = 3.2, N = 20 • Group 2: M = 76, s = 2.4, N = 20 • ICI95 Section 1 = 73.95 to 76.06 • ICI95 Section 2 = 75.21 to 76.79 • Rg = 76.79 - 73.95 = 2.84
Example • The range observed by our ICIs is not larger than the equivalence range (δ) • Conclude the two classes scored similarly.1
Another Example • Anxiety measures are taken from two groups of clients who’d been exposed to different types of therapies (A & B) • We’ll say the scale goes from 0 to 100 • First establish your range of equivalence
Results • Equivalent?
Which method? • Tryon’s proposal using ICIs is perhaps preferable in that: • NHST is implicit rather than explicit • Retains respective group information • Covers both tests of difference and equivalence simultaneously • Allows for easy communication of either outcome • Provides for a third outcome • Statistical indeterminancy • Say what??
Indeterminancy • Neither statistically different or equivalent • Or perhaps both • With equivalence tests one may not be able to come to a solid conclusion • Judgment must be suspended as there is no evidence for or against any hypothesis • May help in warding off interpretation of ‘marginally significant’ findings as trends
Figure from Jones et al (BMJ 1996) showing relationship between equivalence and confidence intervals. This is from the first approach.
Note on sample size • It was mentioned how we couldn’t conclude equivalence from a difference test because small samples could easily be used to show nonsignificance • Power is not necessarily the same for tests of equivalence and difference • However the idea is the same, in that with larger samples we will be more likely to conclude equivalence
Summary • Confidence intervals are an important component statistical analysis and should always be reported • Non-significance on a test of difference does not allow us to assume equivalence • Methods exist to test the group equivalency, and should be implemented whenever that is the true goal of the research question • Furthermore, using these methods force you to think about what a meaningful difference is before you even start