Download
1 / 33
330 likes | 354 Views
Join our Introductory Webinar to learn about European Nucleotide Archive (ENA) and its data coordination, discoveries, data model, and metadata perspective. Discover new polyomaviruses, data organization, and the importance of metadata in genomics research.

E N D
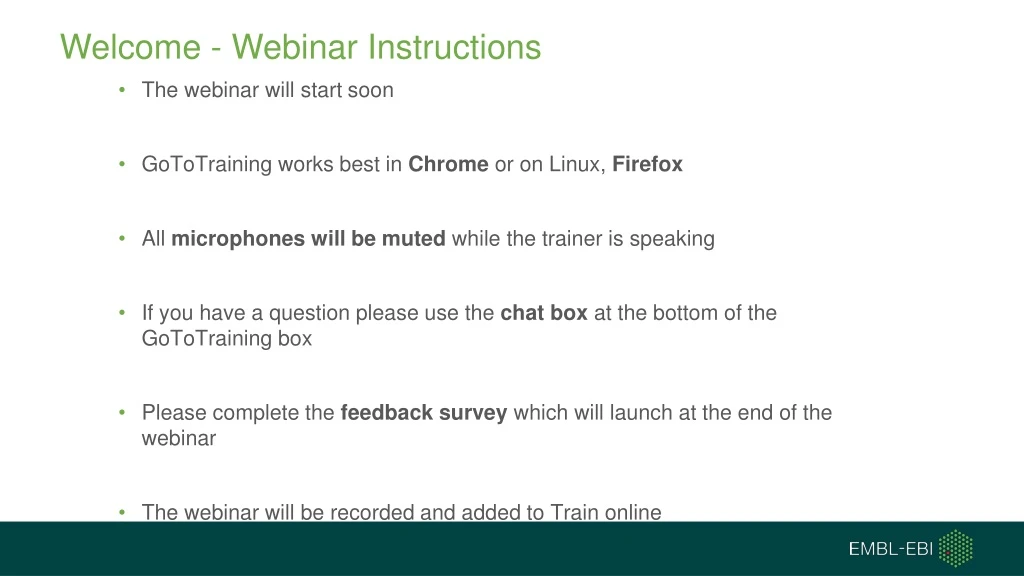
Welcome - Webinar Instructions • The webinar will start soon • GoToTraining works best in Chrome or on Linux, Firefox • All microphones will be muted while the trainer is speaking • If you have a question please use the chat box at the bottom of the GoToTraining box • Please complete the feedback survey which will launch at the end of the webinar • The webinar will be recorded and added to Train online
The European Nucleotide Archive An Introductory Webinar Sam Holt datasubs@ebi.ac.uk
Contents • What ENA Does and Why • Data and Metadata Model • Finding and Retrieving Data • How and Why to Submit Your Data
What ENA Does and Why • ENA provides a comprehensive record of the world’s nucleotide data • Both DNA and RNA • Supports a rich set of tools for submitting and retrieving data • European node of INSDC • Inextricably linked with other EMBL-EBI resources
Data Coordination BlobToolKit Oxford Nanopore MARC ReadUntil
ENA: New Discoveries From Old Data • Poloymavirus – “many tumours” • Well known in mice and primates, including humans • Taxonomic classification for a viral family can guide research to faster understand new member viruses • But previously, few polyomaviruses were known Cryo-EM structure of BK polyomavirus, PDBj
ENA: New Discoveries From Old Data • Buck et al. report discovery of new polyomaviruses in fish, cows, and sheep • Sequence searches against INSDC data identified likely new species in the genomes of: • 3 vertebrate species • 5 spider species • 2 insect species • A near-complete polyomavirus in the genome of the Baja Californian bark scorpion • Evidence that polyomavirus existed in the last common arthropod-vertebrate ancestor Bark scorpionPhoto credit: Joel Sartore
Data Model How We Are Organised
The Data Model: How We Are Organised • ENA stores huge amounts of data … from many users … with samples from many taxa … who use many different techniques … and sequence on many different platforms • But we need to store and display data in a consistent manner • A robust data model is the first step in achieving this
The Data Model: How We Are Organised • All Sequence Data is organised into one of three data tiers: • Reads: the raw output of a sequencing machine • Assemblies: the result of overlapping reads to produce structures which represent real biological molecules such as chromosomes, or sections thereof • Annotations: interpretations of biological function, projected onto an assembly at a coordinate-defined location
The Data Model: How We Are Organised • A FASTQ file is an example of data from the Read tier: • But is it interesting?
The Metadata Model A Squid’s Perspective
The Metadata Model • Data without any context has no value • Metadata tells us how sequence data was produced • Makes it possible to compare datasets: “I want to see data from bacteria … … in the Atlantic Ocean … … sampled between 50-100m … … between April and July … … compared with the same from the Indian Ocean”
The Metadata Model: A Squid’s Perspective Each Spring, the Japanese firefly squid ‘Hotaru-ika’ provides a spectacular show of bioluminescence as hordes come to spawn in Toyama Bay. Bioluminescent organs across the body, but especially in the arm tips, produce this effect using protein crystals. Giminezet al. wanted to study this protein to learn how it works, and look for known homologues. Gimenez et al., Scientific Reports 6 (2016), doi:10.1038/srep27638
The Metadata Model: A Squid’s Perspective The researchers took samples of the organs for study.Samples came from arm tips and mantles.Multiple individuals were sampled, and the details of each sample were logged in the database.
The Metadata Model: A Squid’s Perspective Study Sample Tissue: Arm Tip Indiv.: Squid 1 Sample Tissue: Mantle Indiv.: Squid 1 Sample Tissue: Arm Tip Indiv.: Squid 2 Sample Tissue: Mantle Indiv.: Squid 2 Sample Tissue: Arm Tip Indiv.: Squid 3 Sample Tissue: Arm Tip Indiv.: Squid 4
The Metadata Model: A Squid’s Perspective mRNA was extracted from each of the samples. cDNA was made from this, and sequenced on an Illumina HiSeq 2000.
The Metadata Model: A Squid’s Perspective Study Sample Tissue: Arm Tip Indiv.: Squid 1 Experiment Lib Name: indiv. 1, arm RNA Seq Paired-End Illumina HiSeq 2000 Experiment Lib Name: indiv. 1, mantle RNA Seq Paired-End Illumina HiSeq 2000 Sample Tissue: Mantle Indiv.: Squid 1 Experiment Lib Name: indiv. 2, arm RNA Seq Paired-End Illumina HiSeq 2000 Sample Tissue: Arm Tip Indiv.: Squid 2 Experiment Lib Name: indiv. 2, mantle RNA Seq Paired-End Illumina HiSeq 2000 Sample Tissue: Mantle Indiv.: Squid 2 Experiment Lib Name: indiv. 3, arm RNA Seq Paired-End Illumina HiSeq 2000 Sample Tissue: Arm Tip Indiv.: Squid 3 Sample Tissue: Arm Tip Indiv.: Squid 4 Experiment Lib Name: indiv. 4, arm RNA Seq Paired-End Illumina HiSeq 2000
The Metadata Model: A Squid’s Perspective The result of these 6 paired end experiments is 12 FASTQ files. These are compressed and uploaded to a database, where they undergo processing and wait to be made public.
The Metadata Model: A Squid’s Perspective Study Sample Tissue: Arm Tip Indiv.: Squid 1 Experiment Lib Name: indiv. 1, arm RNA Seq Paired-End Illumina HiSeq 2000 Run 01_R1.fastq.gz 01_R2.fastq.gz Experiment Lib Name: indiv. 1, mantle RNA Seq Paired-End Illumina HiSeq 2000 Sample Tissue: Mantle Indiv.: Squid 1 Run 05_R1.fastq.gz 05_R2.fastq.gz Experiment Lib Name: indiv. 2, arm RNA Seq Paired-End Illumina HiSeq 2000 Sample Tissue: Arm Tip Indiv.: Squid 2 Run 02_R1.fastq.gz 02_R2.fastq.gz Experiment Lib Name: indiv. 1, mantle RNA Seq Paired-End Illumina HiSeq 2000 Sample Tissue: Mantle Indiv.: Squid 2 Run 06_R1.fastq.gz 06_R2.fastq.gz Experiment Lib Name: indiv. 2, arm RNA Seq Paired-End Illumina HiSeq 2000 Sample Tissue: Arm Tip Indiv.: Squid 3 Run 03_R1.fastq.gz 03_R2.fastq.gz Sample Tissue: Arm Tip Indiv.: Squid 4 Experiment Lib Name: indiv. 2, arm RNA Seq Paired-End Illumina HiSeq 2000 Run 04_R1.fastq.gz 04_R2.fastq.gz
Data Retrieval How You Can Benefit
Data Retrieval: Simple Text Search • Enter terms into search box at ENA page • Prone to false positives • Good if you already know what you’re looking for
Data Retrieval: Leveraging Indexed Fields • Focus your search on: • Specific data type • Particular taxon • Restricted description • Leverage annotated fields
Data Retrieval: Leveraging Indexed Fields • Restricting your search gets you more relevant results • Searches can focus on: • Taxonomy • Geography • Environmental conditions • Experimental protocol
Submitting Data How You Can Join In
Submitting Data: Why? • All data in the ENA is submitted by members of the research community • What motivates people to submit? • Open data • Reproducibility • Trail of evidence • 3rd party access • Archival • Publication • MGnify
Submitting Data: How It’s Done • There are three submissions routes • ‘Interactive Submission’: • Use your browser to fill out web forms describing your work • ‘Webin-CLI’: • Smart new submission interface, made in-house • ‘Programmatic Submission’: • Describe your work in XML documents, submit them to use using cURL
Submitting Data: The Interactive Route • Register your objects using your browser • Familiar and largely accessible • Prepare spreadsheets for bigger submissions
Submitting Data: Webin-CLI • A tool to validate, upload and submit data in a single step • Use a manifest file to describe your submission: • And then just submit it: webin-cli -context reads-manifest lib_01_manifest.txt-submit -userName "Webin-1234"-password XXXX Invoke the program Location of manifest Tell it what you’resubmitting Submit the files Login data
Submitting Data: The Programmatic Route • Prepare an XML file describing your submission • Send this to us via HTTPS • Example cURL command: curl-u username:password-F "SUBMISSION=@submission.xml" -F "SAMPLE=@sample.xml""https://wwwdev.ebi.ac.uk/ena/submit/drop-box/submit/"
Any Questions? • Register a submission account at the Webin homepage:https://www.ebi.ac.uk/ena/submit • See submission tutorials at our ReadTheDocs page:https://ena-docs.readthedocs.io/en/latest/ • Get in touch with me via our Helpdesk address:datasubs@ebi.ac.uk
Upcoming Webinars See the full list of upcoming webinars at https://www.ebi.ac.uk/training/webinars Don’t Forget! Please fill in the survey that launches after the webinar – thanks!