Download

1 / 40
400 likes | 703 Views
A methodology for translating positional error into measures of attribute error, and combining the two error sources. Yohay Carmel 1 , Curtis Flather 2 and Denis Dean 3 1 The Thechnion, Haifa, Israel 2 USDA, Forest Service 3 Colorado State University.

E N D
A methodology for translating positional error into measures of attribute error, and combining the two error sources Yohay Carmel1, Curtis Flather2 and Denis Dean31The Thechnion, Haifa, Israel2 USDA, Forest Service3 Colorado State University
Part 1: bridging the gap between positional error and classification error
classification error -- difference in pixel class between the map and a reference
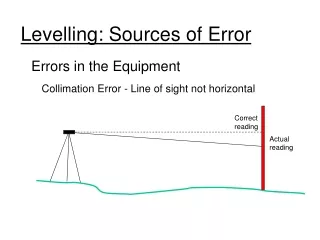
Positional error(misregistration, location error) Is the gap between the true location of an item and its location on the map / image
Positional error may translate to thematic error positional error largely affects overallthematic error(often more than classification error)(Townshend et al 1992, Dai and Khorram 1998)
classification error: Positional error: Accuracy Matrix: RMSE = 2.51 m Goal 1: find a common denominator for both error types Goal 2: combine the two error types to get an overall estimate of error (in the context of temporal change) THE PROBABILITY THAT AN OBSERVED TRANSITION IS CORRECT
Expressing positional error in terms of thematic error Shift = 15, 7 Shift = 1, 0 Shift = 2, 3
Error model: step 1 (and step 2) of 5 PositionalError ClassificationError RMSE
ABOTH2,1 = + ALOC1,1*ACLASS2,1 / n+1 ALOC2,1*ACLASS2,2 / n+2 + ALOC3,1*ACLASS2,3 / n+3 positional accuracy matrix ALOC error model: step 3 (of 5)Combining the two accuracy matrices Classified classification accuracy matrix ACLASS Classified Combined ABOTH Classified
Error model: step 3Combined Error Matrix Reference Classified
Error model: step 4 Calculating the combined PCC, and the Combined user accuracy, p(C) Reference Classified PCC = 0.70 THE PROBABILITY THAT AN OBSERVED STATE IS CORRECT
Calculating multi-temporal indices Error model: step 5 The context of this model is temporal change. The goal is to provide indices for the reliability of an observed change One such index is The probability that an observed transition is correct
Example: vegetation changes in Hastings Nature Reserve, California
1939 1971 1995 1956
C1 C4 1939 1995 Example: vegetation changes in Hastings, California positional accuracy Classification accuracy RMSE 1939 = 3.53 m 1995 = 2.51 m User accuracy for: Grass in 1939 = 0.92 Trees in 1995 = 0.91
C1 C2 C3 C4 1939 1956 1971 1995 The probability that an observed transition is correct p(C1C2…Cn) = p(C1) * p(C2) * … * p(Cn)
C1 C2 C3 C4 Error model: step 5 The probability that an observed transition is correct: p(C1C2…Cn) = p(C1) * p(C2) * … * p(Cn) 1939 1956 1971 1995 This probability may be calculated as the product of the respective user-accuracy value for the respective year and class
G T 1939 1995 G G G T Example: vegetation changes in Hastings, California p(GRASS1939TREE1995) = 0.53 1939 1956 1971 1995 p(G1939G1956G1971T1995) = 0.22
A simulation study was conducted in order to evaluate how robust is the model in generaland in particular -- to violations of two assumptions: • errors in each time step are independent of errors in other time steps • positional and classification errors are independent of one another
Maps for simulations High autocorrelation, equal class proportions Low autocorrelation, unequal class proportions Int. J. Rem. Sens. 2004
Spatial error Simulation Original map Both error types Classification error
Model simulations were conducted under a range of values for: • Number of map categories (2-4) • Class Proportions in the original map • Auto-correlation in the original map • Auto-correlation in classification error • Classification error rate • Positional error rate • Correlation in error structure between time steps • Correlation between the two error types
Maximum correlation found in real datasets* Maximum correlation found in real datasets* *IEEE GRSL 2004 *IEEE GRSL 2004 When models assumptions are not met, model fit decreases
PART 2:Controlling data-uncertainty via aggregation Grid cell size = 15 m = 2500 pixels Pixel size = 0.3 m
Map aggregation = image degradationoverlay a grid of cells on the image (cell >>pixel)and define the larger cell as the basic unit Grid cell size = 15 m = 2500 pixels Pixel size = 0.3 m
Map aggregation = image degradationoverlay a grid of cells on the image (cell >>pixel)and define the larger cell as the basic unit ‘hard’ aggregation ‘soft’ aggregation
Impact of positional error is largely reduced when cells are aggregated b a c
Impact of positional error is largely reduced when cells are aggregated At the pixel level: only 55% of the pixels remained unaffected by a minor shift At the grid cell level:
This trade-off calls for a model that quantifies the process to aid decisions on optimal level of aggregation Aggregation: Gain in accuracy BUT loss of information
Effective positional error at the grid cell level is the proportion of pixels that transgress into neighboring cells (RMSE units)
Positional error at the GRID CELL level p(loc)is the probability that positional error translates into attribute error pA(loc) is the same probability – in the context of a larger grid cell
The impact of aggregation on thematic accuracy 0.23 Ap(loc) cell size error 0.6 m 0.23 6 m 0.14 60 m 0.01
Conclusions • positional error has a large impact on thematic accuracy, particularly in the context of change • But can be easily mitigated: increase MMU to >10X[positional error] and do not worry about it. • Within overall thematic error at the pixel level –classification error component is typically smaller than the positional error component, but is more difficult to get rid of by aggregation.
TODA THANK YOU