Download

1 / 60
600 likes | 714 Views
Learning Ensembles of First-Order Clauses That Optimize Precision-Recall Curves. Mark Goadrich Computer Sciences Department University of Wisconsin - Madison Ph. D. Defense August 13th, 2007. Structured. Database. Biomedical Information Extraction.

E N D
Learning Ensembles of First-Order Clauses That OptimizePrecision-Recall Curves Mark Goadrich Computer Sciences Department University of Wisconsin - Madison Ph. D. Defense August 13th, 2007
Structured Database Biomedical Information Extraction *image courtesy of SEER Cancer Training Site
Biomedical Information Extraction http://www.geneontology.org
Biomedical Information Extraction NPL3 encodes a nuclear protein with an RNA recognition motif and similarities to a family of proteins involved in RNA metabolism. ykuD was transcribed by SigK RNA polymerase from T4 of sporulation. Mutations in the COL3A1 gene have been implicated as a cause of type IV Ehlers-Danlos syndrome, a disease leading to aortic rupture in early adult life.
Outline • Biomedical Information Extraction • Inductive Logic Programming • Gleaner • Extensions to Gleaner • GleanerSRL • Negative Salt • F-Measure Search • Clause Weighting (time permitting)
Inductive Logic Programming • Machine Learning • Classify data into categories • Divide data into train and test sets • Generate hypotheses on train set and then measure performance on test set • In ILP, data are Objects … • person, block, molecule, word, phrase, … • and Relations between them • grandfather, has_bond, is_member, …
verb(…) • alphanumeric(…) phrase_child(…, …) • internal_caps(…) noun_phrase(…) phrase_parent(…, …) • long_sentence(…) Seeing Text as Relational Objects Word Phrase Sentence
Protein Localization Clause prot_loc(Protein,Location,Sentence) :- phrase_contains_some_alphanumeric(Protein,E), phrase_contains_some_internal_cap_word(Protein,E), phrase_next(Protein,_), different_phrases(Protein,Location), one_POS_in_phrase(Location,noun), phrase_contains_some_arg2_10x_word(Location,_), phrase_previous(Location,_), avg_length_sentence(Sentence).
prot_loc(P,L,S) seed ILP Background • Seed Example • A positive example that our clause must cover • Bottom Clause • All predicates which are true about seed example prot_loc(P,L,S):- alphanumeric(P) prot_loc(P,L,S):- alphanumeric(P),leading_cap(L)
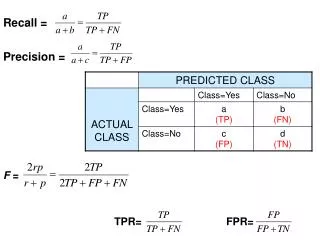
prediction 2PR TP TP TP FN actual + + + TP TP P FN FP R TN FP Clause Evaluation • Prediction vs Actual Positive or Negative True or False • Focus on positive examples Recall = Precision = F1 Score =
Protein Localization Clause prot_loc(Protein,Location,Sentence) :- phrase_contains_some_alphanumeric(Protein,E), phrase_contains_some_internal_cap_word(Protein,E), phrase_next(Protein,_), different_phrases(Protein,Location), one_POS_in_phrase(Location,noun), phrase_contains_some_arg2_10x_word(Location,_), phrase_previous(Location,_), avg_length_sentence(Sentence). 0.15 Recall 0.51 Precision 0.23 F1 Score
Aleph (Srinivasan ‘03) • Aleph learnstheories of clauses • Pick positive seed example • Use heuristic search to find best clause • Pick new seed from uncovered positivesand repeat until threshold of positives covered • Sequential learning is time-consuming • Can we reduce time with ensembles? • And also increase quality?
Outline • Biomedical Information Extraction • Inductive Logic Programming • Gleaner • Extensions to Gleaner • GleanerSRL • Negative Salt • F-Measure Search • Clause Weighting
Gleaner (Goadrich et al. ‘04, ‘06) • Definition of Gleaner • One who gathers grain left behind by reapers • Key Ideas of Gleaner • Use Aleph as underlying ILP clause engine • Search clause space with Rapid Random Restart • Keep wide range of clauses usually discarded • Create separate theories for diverse recall
Gleaner - Learning • Create B Bins • Generate Clauses • Record Best per Bin Precision Recall
Gleaner - Learning Seed K . . . Seed 3 Seed 2 Seed 1 Recall
ex1: prot_loc(…) 12 Pos ex2: prot_loc(…) 47 Neg ex3: prot_loc(…) 55 Pos ex598: prot_loc(…) 5 Pos ex599: prot_loc(…) Neg 14 ex2: prot_loc(…) ex600: prot_loc(…) 47 2 ex601: prot_loc(…) 18 Neg Pos Gleaner - Ensemble Clauses from bin 5 ex1: prot_loc(…) . 12 . . . .
Precision Recall 1.0 0.05 1.00 0.05 0.50 0.10 0.66 Precision 0.85 0.12 0.90 0.13 Recall 1.0 0.90 0.12 Gleaner - Ensemble Examples Score pos3: prot_loc(…) 55 neg28: prot_loc(…) 52 pos2: prot_loc(…) 47 . neg4: prot_loc(…) 18 neg475: prot_loc(…) 17 pos9: prot_loc(…) 17 neg15: prot_loc(…) 16 .
Precision Recall Gleaner - Overlap • For each bin, take the topmost curve
How to Use Gleaner (Version 1) • Generate Tuneset Curve • User Selects Recall Bin • Return Testset ClassificationsOrdered By Their Score Precision Recall = 0.50 Precision = 0.70 Recall
Gleaner Algorithm • Divide space into B bins • For K positive seed examples • Perform RRR search with precision x recall heuristic • Save best clause found in each bin b • For each bin b • Combine clauses in b to form theoryb • Find L of Kthreshold for theorym which performs best in bin b on tuneset • Evaluate thresholded theories on testset
Aleph Ensembles (Dutra et al ‘02) • Compare to ensembles of theories • Ensemble Algorithm • Use K different initial seeds • Learn K theories containing C rules • Rank examples by the number of theories
YPD Protein Localization • Hand-labeled dataset(Ray & Craven ’01) • 7,245 sentences from 871 abstracts • Examples are phrase-phrase combinations • 1,810 positive & 279,154 negative • 1.6 GB of background knowledge • Structural, Statistical, Lexical and Ontological • In total, 200+ distinct background predicates • Performed five-fold cross-validation
Evaluation Metrics 1.0 • Area Under Precision-Recall Curve (AUC-PR) • All curves standardized to cover full recall range • Averaged AUC-PR over 5 folds • Number of clauses considered • Rough estimate of time Precision Recall 1.0
Other Relational Datasets • Genetic Disorder(Ray & Craven ’01) • 233 positive & 103,959 negative • Protein Interaction (Bunescu et al ‘04) • 799 positive & 76,678 negative • Advisor (Richardson and Domingos ‘04) • Students, Professors, Courses, Papers, etc. • 113 positive & 2,711 negative
Gleaner Summary • Gleaner makes use of clauses that are not the highest scoring ones for improved speed and quality • Issues with Gleaner • Output is PR curve, not probability • Redundant clauses across seeds • L of Kclause combination
Outline • Biomedical Information Extraction • Inductive Logic Programming • Gleaner • Extensions to Gleaner • GleanerSRL • Negative Salt • F-Measure Search • Clause Weighting
Precision Recall Estimating Probabilities - SRL • Given highly skewed relational datasets • Produce accurate probability estimates • Gleaner only produces PR curves
Gleaner Algorithm GleanerSRL Algorithm(Goadrich ‘07) • Divide space into B bins • For K positive seed examples • Perform RRR search with precision x recall heuristic • Save best clause found in each bin b • For each bin b • Combine clauses in b to form theoryb • Find L of Kthreshold for theorym which performs best in bin b on tuneset • Evaluate thresholded theories on testset • Create propositional feature-vectors • Learn scores with SVM or other propositional learning algorithms • Calibrate scores into probabilities • Evaluate probabilities with Cross Entropy
Learning with Gleaner • Generate Clauses • Create B Bins • Record Best per Bin • Repeat for K seeds Precision Recall
Pos Neg Pos Pos Neg Creating Feature Vectors Clauses from bin 5 K Boolean 1 0 1 Binned ex1: prot_loc(…) 1 12 1 . . . . . . 0
0.00 0.50 0.66 1.00 Calibrating Probabilities • Use Isotonic Regression (Zadrozny & Elkan ‘03) to transform SVM scores into probabilities Probability Class 0 0 1 0 1 1 0 1 1 Score -2 -0.4 0.2 0.4 0.5 0.9 1.3 1.7 15 Examples
GleanerSRL Results for Advisor (Davis et al. 05) (Davis et al. 07)
Outline • Biomedical Information Extraction • Inductive Logic Programming • Gleaner • Extensions to Gleaner • GleanerSRL • Negative Salt • F-Measure Search • Clause Weighting
prot_loc(P,L,S) seed salt Negative Salt • Seed Example • A positive example that our clause must cover • Salt Example • A negative example that our clause should avoid
Gleaner Algorithm • Divide space into B bins • For K positive seed examples • Perform RRR search with precision x recall heuristic • Save best clause found in each bin b • For each bin b • Combine clauses in b to form theoryb • Find L of Kthreshold for theorym which performs best in bin b on tuneset • Evaluate thresholded theories on testset • Select Negative Salt example • Perform RRR search with salt-avoiding heuristic • Save best clause found in each bin b • For each bin b • Combine clauses in b to form theoryb • Find L of Kthreshold for theorym which performs best in bin b on tuneset • Evaluate thresholded theories on testset
Outline • Biomedical Information Extraction • Inductive Logic Programming • Gleaner • Extensions to Gleaner • GleanerSRL • Negative Salt • F-Measure Search • Clause Weighting
Gleaner Algorithm • Divide space into B bins • For K positive seed examples • Perform RRR search with precision x recall heuristic • Perform RRR search with F Measure heuristic • Save best clause found in each bin b • For each bin b • Combine clauses in b to form theoryb • Find L of Kthreshold for theorym which performs best in bin b on tuneset • Evaluate thresholded theories on testset
RRR Search Heuristic • Heuristic function directs RRR search • Can provide direction through F Measure • Low values for encourage Precision • High values for encourage Recall