Download

1 / 37
370 likes | 598 Views
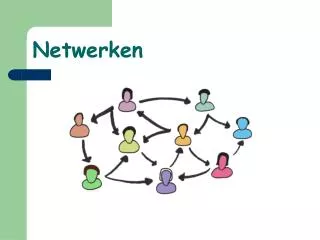
Bayesiaanse Netwerken. Voorbeeld Bayesiaans netwerk. Acyclische graph met nodes {A,B,C,D,E} Directed Acyclic Graph (DAG). Causaal netwerk. Kansberekening. Bereik van kansen: 0 P(A) 1 Somregel: Mutually exclusive:. Logisch equivalent: P(A B ) = P(B A ). Productregel:.

E N D
Voorbeeld Bayesiaans netwerk Acyclische graph met nodes {A,B,C,D,E} Directed Acyclic Graph (DAG) Causaal netwerk
Kansberekening Bereik van kansen: 0 P(A) 1 Somregel: Mutually exclusive: Logisch equivalent: P(A B) = P(B A) Productregel:
Conditionele waarschijnlijkheid Gegeven gebeurtenis b, de kans dat a optreedt is x Oftewel: P(a|b) = x We zijn ook geïnteresseerd in de kans dat zowel a als b optreden. De gezamelijke waarschijnlijkheid (jointprobability) van a b is: P(a,b) = P(a|b) P(b)
Regel van Bayes 1. P(a,b) = P(a|b) P(b) Verder: Als b relevant is voor a, dan is a relevant voor b, en dus als de waarschijnlijkheid voor a verandert dan verandert die voor b ook. Dit heet symmetrie. Er geldt derhalve: 2. P(a,b) = P(b|a) P(a) Dit resulteert in de regel van Bayes: P(a|b) P(b) = P(b|a) P(a) Ook wel:
(On)afhankelijkheid en joint probability Iemand is Blank en Man Stel P(Blank) = 0.5 en P(Man) = 0.4 Stel ook dat P(Blank) en P(Man) onafhankelijk zijn, dan geldt er: P(Blank|Man) = P(Blank) En de joint probability: P(Blank Man) = P(Blank|Man) *P(Man) = P(Blank) *P(Man) = 0.5*0.4 = 0.2 1 Iemand is Lang en Man Stel P(Lang) = 0.5 en P(Man) = 0.4 Stel ook dat P(Lang) en P(Man) afhankelijk zijn en dat de conditionele kans op Lang gegeven Man: P(Lang | Man) = 0.8 Nu wordt de joint probability: P(Lang Man) = P(Lang|Man) * P(Man) = 0.8*0.4 = 0.32 2
Er geldt: P(Blank Man) = P(Man Blank) P(Blank | Man) * P(Man) = P(Man | Blank) * P (Blank) 0.5 * 0.4 = P(Man | Blank) * 0.5 En dus: P(Man | Blank) = 0.4 1 Er geldt: P(Lang Man) = P(Man Lang) P(Lang | Man) * P(Man) = P(Man | Lang) * P (Lang) 0.8 * 0.4 = P(Man | Lang) * 0.5 En nu is: P(Man | Lang) = 0.32 / 0.5 = 0.64 2
Symmetrie, the “inverse fallacy” • Verwar dus de kans dat iemand Lang is gegeven dat hij Man is P(Lang|Man) niet met de kans dat iemand Man is gegeven dat de persoon Lang is P(Man|Lang) • Je moet dus ook de kans meenemen dat iemand Man P(Man) is of de kans dat iemand Lang is P(Lang)
Afleiding Bayes Rule Er geldt: A = (AB) v (AB) Dus: P(A) = P((AB) v (AB)) (AB) en (AB) zijn mutually exclusive, dus: P(A) = P((AB) v (AB)) = P(AB) + P(AB) Verder geldt er: P(AB) = P(A|B).P(B) en P(AB) = P(A|B).P(B) Dus, P(A) = P(A|B).P(B) + P(A| B).P(B) Ergo:
Definitie van een Bayesiaans Netwerk (BN) • Een Bayesiaans netwerk bestaat uit: • Een set variabelen en een set gerichte verbindingen tussen de variabelen • Elke variabele heeft een eindig aantal elkaar uitsluitende toestanden • De variabelen vormen een gerichte acyclische graph (DAG) • Elke variabele A met parents B1, …,Bn heeft een conditionele waarschijnlijkheidstabel P(A | B1, ….,Bn)
Variabelen en toestanden Elke node kan in een bepaalde toestand zijn. We zeggen, de nodes zijn variabelen met een eindig aantal, elkaar uitsluitende, toestanden (mutually exclusive states) Bijv. A is een variabele met toestanden {a1, a2 … an}. P(A) is dan de waarschijnlijkheidsdistributie over deze toestanden: P(A) = {P(a1), P(a2) … P(an)} : SP(ai) = 1 i
Voorbeeld Conditionele kansen A a1,a2 P(B|A): B b1,b2,b3 som v.d. rijen = 1
Bereken nu de joint probability uitde conditionele kansen Gegeven is de waarschijnlijkheids-distributie van A: P(A) = (0.4, 0.6) P(B|A): Er geldt: P(bi, aj) = P(bi|aj)P(aj) En dus, P(B,A):
Bereken nu P(B) uit P(B,A) P(B) = SP(B,A) A P(bi) = SP(bi,aj) j En dus, P(B) = (0.52, 0.18, 0.3) Dit proces heet Marginalisation
Bewijs (evidence) Er zijn twee soorten evidence: Hard evidence (instantiation). Als voor een node X bekend is dat hij zeker in een bepaalde toestand is. Voorbeeld: een voetbalclub kan in drie toestanden zijn, winnen gelijk spelen of verliezen. Na afloop is de toestand bekend en kan als hard evidence in het netwerk opgenomen worden. Soft evidence. Als er voor een node X iets bekend is dat ons in staat stelt de waarschijnlijkheid van een bepaalde toestand te verhogen. Voorbeeld: als het bij de rust van een voetbalwedstrijd 3-0 staat, stijgt de waarschijnlijkheid voor de toestand “winnen”.
Ander rekenvoorbeeld S = stijve nek, M = meningtitis Wat is de kans dat iemand meningtitis heeft gegeven dat hij een stijve nek heeft ? a-priori: P(S) = 0.05 P(M) = 0.0002 P(S|M) = 0.9 (dus als iemand meningtitis heeft dan heeft hij bijna altijd een stijve nek) (dus als iemand een stijve nek heeft dan heeft hij bijna nooit meningtitis)
Typen connecties • In Bayesiaanse netwerken zijn er drie typen verbindingen: • Serieel • Convergerend • Divergerend
Seriele verbinding Evidence in node A beinvloedt beide nodes B en C Als er evidence in node A is, heeft evidence in node B geen invloedt op node C
Convergerend Eén van de parents is bekend. Dit beinvloedt de andere parent node (“hoofdpijn”) niet Eén van de parents is bekend en de child node “antwoord” is ook bekend. De ene parent beinvloedt de andere parent node (“hoofdpijn”) nu wel. Hieruit volgt dat als er niets bekend is over the child node, dan zijn de parent nodes onafkhankelijk, anders niet. Dus parent nodes zijn conditioneel afhankelijk van child nodes. Dit wordt ook wel d-separation genoemd.
Divergerend Child node “geleerd” beinvloedt child node “hoofdpijn” niet door parent node “antwoord” als deze bekend is (d-separated). (Als “antwoord” niet bekend is beinvloedt node “geleerd” de node “hoofdpijn” wel). De parent node “antwoord” beinvloedt de beide child nodes “geleerd” en “hoofdpijn”
D-separation • Twee nodes B en C in een Bayesiaans netwerk zijn d-separated als voor alle • paden tussen B en C er een tussennode A bestaat waarvoor geldt: • De verbinding is serieel of divergent en de toestand van A is bekend; • De verbinding is convergent en de toestand van A is onbekend.
Voorbeeld: geleerd voor een examen Probleem: Een student moet voor een examen leren. Wat is de kans dat hij een goed antwoord geeft? Oplossing: We stellen dat de kans dat de student de examenstof geleerd heeft op 0.5. Deze kans noemen we G. Dus P(G=true) = 0.5 De student kan een goed of een fout antwoord A geven. De kans dat het antwoord goed is noemen we P(A=goed) of kortweg P(A). Deze kans is conditioneel afhankelijk van of de student de stof heeft geleerd.
Het Bayesiaanse netwerk P(A|G):
Berekening P(A=goed) • Voor het netwerk zijn de a-priori kansen voor P(A) onder de • voorwaarde “geleerd” gegeven: • goed antwoord en geleerd : P(A=goed | G=true) = 0.9 • fout antwoord en geleerd : P(A=fout | G=true) = 0.1 • goed antwoord en niet geleerd : P(A=goed | G=false) = 0.4 • fout antwoord en niet geleerd : P(A=fout | G=false) = 0.6 • Nu wordt de kans P(A=goed), d.w.z. de kans dat de student een goed antwoord • geeft, als volgt berekend: • P(A=goed) = P(A=goed|G=true). P(G=true) +P(A=goed|G=false). P(G=false) • = 0.9*0.5 + 0.4*0.5 • = 0.65
Invloed van evidence Stel dat de student het examen doet en een goed antwoord geeft. Deze zekerheid (“evidence”) kunnen we aan het netwerk geven. Wat is nu de a-posteriori kans dat de student de stof geleerd heeft, P(G|A) oftewel P(G=true|A=goed)? En wat is de nieuwe kans dat hij voor het volgende examen de stof gaat leren, P`(G) (Het is bekend dat de student een goed antwoord gegeven heeft)
Evidence Dus, gevraagd wordt: P(G) = 0.5 P(A) = P(A=goed|G=true) * P(G=true) + P(A=goed|G=false) * P(G=false) = 0.9*0.5 + 0.4*0.5 = 0.65 En dus P(G | A) = 0.9 * 0.5 / 0.65 = 0.692 (Als A=goed als evidence wordt ingegeven, wordt de nieuwe waarde voor P(G=true) = P(G|A) = 0.692) Gemaakt in Netica (zie www.norsys.com)
Bereken nu P(G | A) onder de evidence Antwoord = false P(G | A) = 0.143
Voorbeeld, meer nodes Stel dat we de invloed van hoofdpijn H op het examenresultaat willen modelleren. Dan kunnen we een (convergerend) netwerkje maken:
Berekening P(A=goed) • De kans op een goed antwoord is nu de som van de 4 mogelijkheden, • vermenigvuldigd met de conditionele kans op een goed antwoord: • Dus P(A=goed) = S{P(A=goed|G,H) . P(G) . P(H)} • P(A=goed|G=true,H=true). P(G=true).P(H=true) = 0.3*0.5*0.2 = 0.03 + • P(A=goed|G=true,H=false). P(G=true).P(H=false) = 0.9*0.5*0.8 = 0.36 + • P(A=goed|G=false,H=true). P(G=false).P(H=true) = 0.05*0.5*0.2 = 0.005 + • P(A=goed|G=false,H=false). P(G=false).P(H=false) = 0.4*0.5*0.8 = 0.16 • Totaal = 0.555
Explaining away Uit de evidence dat de auto niet start berekent het netwerk dat de waarschijnlijkheid het grootst is dat de accu goed is (67.9% tegen 57.3% van de startmotor). Echter, uit nieuw evidence dat de lampen ook niet aan gaan berekent het netwerk nu dat de kans dat de accu goed is 32.0% is tegen 68.9% dat de startmotor goed is. Op zo’n manier fenomenen met elkaar vergelijken en conclusies trekken heet “explaining away”..
Samenvatting • BNs erg populair de laatste tijd • Onzekere gebeurtenissen en processen kunnen modelleren op een manier die erg begrijpelijk is. • Grafische representaties van de netwerken maken het gedrag en de rekenmethode zeer inzichtelijk. • Kennis van experts kan eenvoudig overgedragen en duidelijk gemaakt worden voor iedereen. • Het kunnen toepassen van evidence is een krachtig middel om de waarschijnlijkheden in het netwerk te kunnen “leren” • Dus: BNs momenteel de meest geschikte methode voor waarschijnlijkheidsrekening • Bekendste applicatievoorbeeld: “Help Wizard” in Microsoft Office. BNs worden ook toegepast in medische en mechanische diagnose systemen
Volgende week … Bayesiaanse netwerken en MAS Negotiation