Download

1 / 40
460 likes | 994 Views
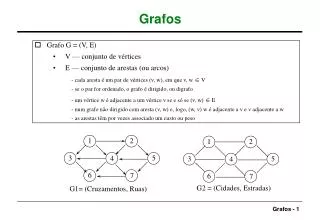
Ejemplos de Grafos:. Red de tráfico con caminos y cruces. Redes de cañerías Flujos: grafos dirigidos Redes de computadores (transmisión de datos) Largos o costos y capacidades de los arcos se representan por pesos, y/o valores en los arcos. Problemas importantes en la teoría de grafos.

E N D
Ejemplos de Grafos: • Red de tráfico con caminos y cruces. • Redes de cañerías • Flujos: grafos dirigidos • Redes de computadores (transmisión de datos) Largos o costos y capacidades de los arcos se representan por pesos, y/o valores en los arcos.
Problemas importantes en la teoría de grafos • Calcular la distancia mínima desde un nodo de salida hasta todos los otros nodos. • Calcular un árbol cobertor (el subgrafo que tiene la menor menor suma de la cantidad/costo/largo de los arcos que une a todos los nodos). • Encontrar un elemento en el grafo, determinar si hay ciclos. • Cálculo de un camino que pasa justo una sola vez por todos los arcos/nodos. • Coloracion de grafos. • Centralidades en grafos: ej. ¿Cual es el nodo mas „central“ ?, ¿ bajo qué criterios ?.
Representación de grafos (1) • Matriz de adjacencia: Se asocian los nodos a los índices de las filas y columnas de la matriz. Un arco del i-esimo al j-esimo nodo se representa por una marca en el elemento (i,j) de lamatriz. Para grafos no dirigidos basta una mitad de la matriz.
Representación de grafos (2) 2. Lista de Adjacencia: Los sucesores de un nodo se ponen en una misma lista enlazada, una asiciada a cada nodo. (arreglo de listas, o lista de listas) 1 2 4 2 4 1 3 3 5 4 5 5 3
Representación de grafos (3) 4 3. Matriz de Incidencia... ... de un Grafo no dirigido G=(V,E) es una matriz |V| |E|, con i(j,k) = 0, cuando el arco k no incide en el nodo j (no llega/sale), bzw. i(j,k)=1,2, cuando el arco k incide una o dos veces (Loops) con el nodo j. 3 2 5 1 6
Costo de las representaciones 1. Matriz de adjacencia Memoria: O(|V|²) costo de saber si hay un arco (v,w): O(1). 2. Lista de adjacencia Memoria: O(|V|+|E|) costo de saber si hay un arco (v,w): O(|E|). 3. Matriz de incidencia Memoria: O(|V| • |E|) costo de saber si hay un arco (v,w):
Búsqueda (recorrido) en profundidad o en amplitud La expansión de un grafo dirigido desde un nodo v se representa por un árbol X(v) donde: • X(v) = (v), si v no tiene sucesores, • X(v) = (v, X(v1), …, X(vp)), si v1,…,vp son los sucesores de v. Cuando el grafo tiene ciclos la expansión es infinitamente.
Dos algoritmos de búsqueda En profundidad: en un grafo dirigido G hacer un recorrido similar al de preorden (primero los hijos luego el padre) pero se detiene la recursividad cuando se alcanza un nodo ya visitado Profundidad(v) si v no ha sido visitado: procesar v; marcar v como visitado; para todo sucesor de N(v) de v (de izquierda a derecha) invocar (N(v)). costo: O(|V| + |E|). Estructura de datos usada: Stack.
Búsqueda en amplitud Amplitud(v) primero la raíz v, luego los nodos vecinos a v (nivel 1), luego los nodos vecinos a los de nivel 1 (nivel 2), usw. costo: O(|V| + |E|). Estructura de datos usada: Queue
Algoritmo Búsqueda en amplitud Amplitud(v) { print(v) Mark(v) p = new Queue() put all neighbors of root in q and mark them while(!empty(q)) { o = dequeue(q) print(o) put all not marked neighbors of o in q and mark them } }
Algoritmos de Prim y de Kruskal Recordemos: un grafo conexo (no dirigido ) sin ciclos es un árbol. Características: • Tiene n nodos y exactamente n-1 arcos. • Si se le pone un arco más entonces se crea un ciclo en el grafo. Objetivo: Calcular el spanning tree de minimo costo para un grafo conexo no dirigido (un árbol que es subgrafo del original que contiene todos los nodos y la suma de los costos de sus arcos es mínima).
Algoritmo de Kruskal Descripción: • Descomponer el grafo y su conjunto de nodos en componentes unitarias en una particion P de una estructura tipño Find-and-Merge. • Los arcos se ordenan segun sus costos de menor a mayor usando una cola de prioridad Q: Si el arco de menor costo une dos componentes de la estructura se usa para la construcción del spanning tree minimal T. Las componentes que une se funden entonces en una sola. Si no se ignora. • Cuando la estructura quede con una componente entonces esta corresponde al spanning tree T de G.
Sea G=(V,E,d) un grafo conexto con n nodos. Sea e := |E|. Algorithmus Kruskal (G)//Computa el spanning tree minimal de G Inicializar la partición P de modo que cada nodo V es una componente # O(n) Sea T = (V, { }); Construir una cola de prioridad (Heap) Q con los arco # O(e log e) ncomp := n; while ncomp > 1 do # máximo e iteraciones (Q, (v,w)) := deletemin(Q); # O(log e) a:= find (P, v); # O(log n) b:= find (P, w); # O(log n) if a!=b {insert(T,(v,w)) ; P:= merge(P,a,b); dec(ncomp); } # O(1) end {Kruskal}. Partition in Find-and-Merge-Struktur: con ella se construye el spanning tree. Costo total : O(e log e) (Notar: e >= n-1, ya que el grafo es conexo).
Correctitud del algoritmo de Kruskal: Por probar: el árbol construido T es minimal. Prueba por contradicción. Suposición: no es el caso. Sea H un árbol cobertor minimal, que tiene los arcos casi todos coincidentes con T. Sea eiel primer arco considerado por el algoritmo que solo pertenece a E(T) o solo pertenece a E(H), pero no está está en ambos. Segun el algoritmo el segundo caso (esta en E(H), pero no en E(T)) imposible. Por lo tanto, ei esta en E(T), pero no en E(H). Si uno pone ei en el árbol H entonces se tiene en „H con ei“ un ciclo. En este ciclo hay un arco em, que no pertenece a T. Si lo sacamos entonces tenemos un nuevo árbol cobertor H‚ que tiene a lo más el mismo peso que H. Según la definición de ei éste se considera antes que em por el algoritmo, o sea puede tener a lo más el mismo peso que em. Con esto es H´ también un árbol cobertor mínimo y tiene un un arco más en común con T
Algoritmode Prim Sea G=(V,E,d) un grafo conexo con pesos. Objetivo: calcular el árbol cobertor mínimo T. Breve: Construir el árbol T por pasos: Partir con un vértico (nodo) cualquiera. incorporar siempre el arco con menor peso (costo) que tiene un extremo en el árbol construido y otro fuera de él hasta que todos los nodos hayan sido incorporados al árbol.
A -> B -> E -> {G->F, D, C}
Algoritmo de Prim - detallado Construir: • Lista de n vértices, en la que se especifican sus respectivos arcos con sus pesos y su posición en el heap (de los arcos), • Lista de arcos con sus vértices. • Inicializar dos conjuntos de nodos M = { } y N=V \ M así como el árbol cobertor T = (V, { }). • Escoger un vértice y0 de V, poner M:={y0} y adaptar N. • Definir s(y) := d(y,y0), donde d(y) = maxInteger, si es que no hay un arco entre y0 a y. • Se construye un Heap (según la función: s(y)) de todos los arcos que salen de N se guarda su posición en el Heap en la lista de vértices. WHILE N <> { } DO BEGIN • Sea y1 el nodo con el s(y1) mínimo. Se inserta el arco de M a y1 en T, se saca y1 del Heap y se pone y1 en M. • Redefinir s(y) := min {s(y), d(y1,y)} para todo y de N. • Ahora debe adecuarse el heap para todos los sucesores de y1. Esto puede ser realizado con la informacion de ka posición en el Heap con un costo de O(log n). END # While
Costo del Algoritmo de Prim: • Construir la lista de vértices y el primer Heap: O(|E| + |V| log |V|) (O usando la idea de que un heap puede construirse en tiempo lineal: O(|E| + |V|) = O(|E|) ). • La actualización del heap requiere que se itere sobre la lista de los sucesores de un vértice: costo = O(|E| log |V|), es decir O(log |V|) por cada sucesor. • La readecuación del Heap se tiene que hacer la cantidad de vértices que hayan |V|-veces, cada vez que se extrae el mínimo. costo: O(|V| log |V|). Costo total: O(|E| log|V|) (ya que |E| |V|-1)
Bases para el Algoritmo de Prim: Observación: Loa árboles de cobertura mínimos tienen siempre un arco con el peso mínimo. Demostración: Si no fuera así se puede introducir este arco y se creará un ciclo. Como dos vértices pueden alcanzarse uno a otro por dos caminos distintos, basta borrar uno sin que deje de ser un árbol conexo. De esta manera se puede lograr otro árbol que tiene al menos el mismo peso que el original (sino menor).
Esta característica es válida en forma más general aún. Sean U y W una partición del conjunto de vértices de G en dos subconjuntos disjuntivos y (u,w) un arco de costo mínimo que une estos dos conjuntos. Entonces existe un árboil de costo mínimo que contiene este arco. Demostración: aquí también se podria incluir (u,w) y borrar otro arco (u',w') que une U con W . La correctitud del algoritmo se demuestra ya que la última observación se aplica en cada iteración del algoritmo para unir los conjuntos de los nodos que están en el árbol construido hasta ahora con los nodos del conjunto de vértices que aún no están
Distancias mínimas en Grafos „Single source shortest path problem“ Dado: • Grafo dirigido con pesos (todos 0), • Un vértice („pubto de partida“) v0 en el grafo. Buscar: camino más corto de v0 a todos los otros nodos (suponiendo que hay camino a ellos).
Dijkstra-Algorithmus Algorithmus Dijkstra (v0,G) //verdes; distancia final calculada, amarillos distancia previa calculada para todo u { dist(u) := maxint }; verde :=vacío; amarillo:= {v0}; dist(v0):=0; While amarillo != vacío do { escoger w de amarillo de modo que dist(w) minimal; colorear w verde; para cada u scc(w) do { si u está en V\(verde o amarillo) { colorear u amarillo; dist(u):= dist(w)+ cost(w,u);} si u de amarillo //tenia calculada una distancia preliminar { si dist (u) > dist(w)+cost(w,u) entonces dist(u):=dist(w)+cost(w,u) } } } end;
C D A 30 B E F Ejemplo C D 40 40 10 30 A B 30 10 100 90 F E 20 Distancias más cortas desade A 30 40 10 40 10 100 20 90
Descripción: Idea: Hacer crecer el subárbol construido hasta ahora por los caminos más cortos. Nodos verdes: nodos cuyos sucesores ya hab sido considerados. = nodos a los cuales ya se les ha calculado la distancia mínima . Nodos amarillos: los sucesores de los nodos verdes que no son verdes Arcos rojos: arcos sobre los cuales pasa al menos una ruta óptima de las calculadas hasta el momento. Arcos amarillo: arcos que han sido reconocidos como no optimales.
Ciclo Un ciclo del algoritmo: • De todos los nodos amarillos, colorear verde el w el que tiene menor distancia a v0. • Colorear amarillo todos los sucesores de w. • Registrar o corregir los los caminos más cortos desde v0 a cada uno de los sucesores de w, asi como su longitud (con esto arcos no coloreados pueden tornarse rojos y arcos rojos pueden tornarse amarillos).
Ejemplo (2) C D C D 40 10 30 30 A B A B 100 100 90 90 F E F E
Ejemplo(3) 40 40 C D C D 40 40 10 40 40 10 30 30 A B A B 10 10 100 100 90 90 F E F E 50 20
Ejemplo (4) 40 40 C D C D 70 70 40 40 40 40 10 10 30 30 30 30 30 A B A B 10 10 100 100 90 90 F F E E 50 50 20 20 70 70
A 5 B 7 5 6 5 4 D 2 3 2 E 3 1 F C 2 3 Computing „on the paper“ G
Computing „on the paper“ A 5 B 7 5 6 5 4 D 2 3 2 E 3 1 F C G 2 3 Primero se ponen las distancias desde A en la primera fila correspondientes a los arcos que salen de A. De estos se escoge el menor (5) y se anota en la primera columna de la segunda fila. Ademas se anota el nodo (B) y las distancias de A a los vecinos pasando por B (10 a C, 10 a D y 9 a E). De aquí notamos que hay un camino menor de A a D sin pasar por B (directo 6). El siguiente más cercano a A es D (6) por lo que se anota en la tercera fila y se hace el mismo proceso.
8.4.2 Implementación del Algoritmo a) Implementación con una matriz de adjacencia Sea V={1,...,n} y sea cost(i,j) la matriz de distancias donde se registra un infinito donde no hay camino directo entre dos nodos. Además usaremos: double dist[] = new double[n]; node father[] = new node[n];boolean green[] = new boolean[n]; El arreglo father representa el árbol de los arcos rojos, en el cual cada nodo apunta a su nodo padre. Los nodos amarillo no se representan explícitamente.
Ciclo Cada iteración consta de los siguientes pasos: • El arreglo dist se recorre completo, para encontrar el w amarillo con la menor distancia. costo: O(n). • Las lineas cost(w,*) de la matriz son recorridas para corregir (en caso necesario) las distancias de los sucesores de w. costo: O(n). Costo total: O(n²), ya que hay n iteraciones. Inefficiente, salvo cuando n es muy chico o e cercano a n² !
b) Implemntaciòn con listas de adyacencia y Heap Grafo: dado con listas de adjacencia. Como antes: • Array dist • Array father Además: • Heap (implementado cmo arreglo) de todos los nodos amarillos, ordenados según distancia al nodo de origen, • Array heapaddress, que contiene para cada nodo amarillo su posición en el Heap.
Iteración Cada iteraci+on consta de los siguientes pasos: 1. Sacar el nodo amarillo w con la distancia mínima del Heap Aufwand: O(log n). 2. Encontrar en la lista de adyacencia m(w) sucesor de w. Aufwand: O(m(w)). (i) para cada nodo sucesor amarillo ,,nuevo" ponero en el heap (ii) para cada nodo sucesor ,,antiguo" corregir en caso necesario su distancia y su posiciòn en el heap. Su posiciòn se puede encontrar en el heapaddress. Dado que su distancia al nodo de origen disminuye (o no se correige) puede ser necesario elevarlo a la parte superior. Las posiciones en el heap de este nodo pueden modificarse en O(1). Costo para (i) y (ii): en total O(m(w) log n). Costo total para 2: O( log n•{Knoten w}m(w)) = O( e log n). Costo total para 1: O(min{n,e}log n), ya que un elemento se puede sacar del heap solo si antes se haia puesto. Costo total: O(e log n) (costo total de memoria: O(n+e))
Prueba de correctitud: Aseveración: en todo momento se cumple para todo nodo verde: • Existe un camino mínimo de v0 hasta u, que solo contiene nodos verdes. • Su longitud es dist(u). Prueba: por Induccion. Se debe mostrar esta aseveración para los nodos que pasan de amarillo a verde. De esta aseveración se desprende la correctitud del algoritmo.