Download
1 / 67
710 likes | 1.44k Views
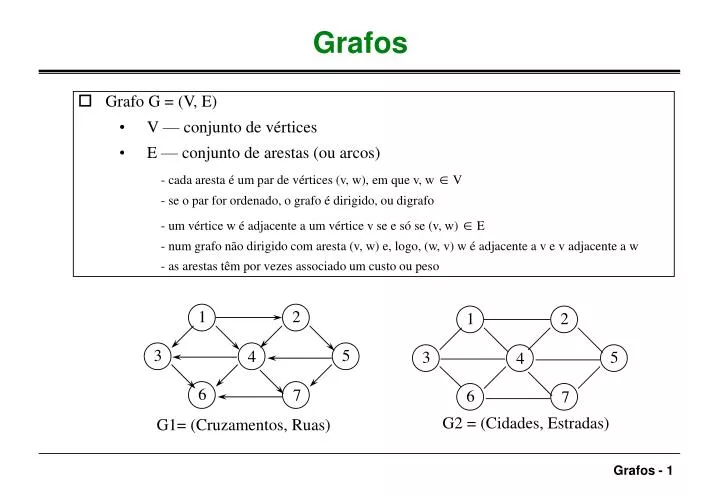
Grafo G = (V, E) V — conjunto de vértices E — conjunto de arestas (ou arcos) - cada aresta é um par de vértices (v, w), em que v, w Î V - se o par for ordenado, o grafo é dirigido, ou digrafo - um vértice w é adjacente a um vértice v se e só se (v, w) Î E

E N D
Grafo G = (V, E) V — conjunto de vértices E — conjunto de arestas (ou arcos) - cada aresta é um par de vértices (v, w), em que v, w Î V - se o par for ordenado, o grafo é dirigido, ou digrafo - um vértice w é adjacente a um vértice v se e só se (v, w) Î E - num grafo não dirigido com aresta (v, w) e, logo, (w, v) w é adjacente a v e v adjacente a w - as arestas têm por vezes associado um custo ou peso Grafos 1 2 1 2 3 5 4 3 5 4 6 7 6 7 G2 = (Cidades, Estradas) G1= (Cruzamentos, Ruas)
caminho — sequência de vértices v1, v2, …, vn tais que (vi, vi+1) Î E, 1 i <n comprimento do caminho é o número de arestas, n-1 - se n = 1, o caminho reduz-se a um vértice v1; comprimento = 0 anel — caminho v, v Þ (v, v) Î E , comprimento 1; raro caminho simples — todos os vértices distintos excepto possivelmente o primeiro e o último ciclo — caminho de comprimento 1 com v1 = vn num grafo não dirigido requer-se que as arestas sejam diferentes DAG — grafo dirigido acíclico conectividade grafo não dirigido é conexo sse houver um caminho a ligar qualquer par de vértices digrafo com a mesma propriedade — fortemente conexo digrafo fracamente conexo — não fortemente conexo; grafo subjacente conexo densidade grafo completo — existe uma aresta entre qualquer par de nós grafo denso — |E| = Q(V2) grafo esparso — |E| = Q(V) Mais definições
matriz de adjacências a[u][v] = 1 sse (u, v) Î E elementos da matriz podem ser os pesos (sentinelas indicam não aresta) apropriada para grafos densos 3000 cruzamentos e 12 000 troços de ruas (4 por cruzamento) - 9 000 000 de elementos na matriz! • 1 2 3 4 5 6 7 • 0 1 1 1 0 0 0 • 0 0 0 1 1 0 0 • 0 0 0 0 0 1 0 • 0 0 1 0 0 1 1 • 0 0 0 1 0 0 1 • 0 0 0 0 0 0 0 • 0 0 0 0 0 1 0 Representação
estrutura típica para grafos esparsos para cada vértice, mantém-se a lista dos vértices adjacentes vector de cabeças de lista, indexado pelos vértices espaço é O(|E| + |V|) pesquisa dos adjacentes em tempo proporcional ao número destes grafo não dirigido: matriz simétrica; lista com o dobro do espaço Lista de adjacências 1 2 4 3 2 4 5 3 6 4 6 7 3 5 4 7 6 7 6
impossível se o grafo for cíclico não é necessariamente única (1 2 5 4 3 7 6) ou (1 2 5 4 7 3 6) no exemplo anterior algoritmo simples: - descobrir um vértice sem arestas de chegada - imprimir o vértice - eliminá-lo e às arestas que dele saem - repetir o processo no grafo restante Indegree(v) — é o número de arestas (w, v) passagem sequencial do vector é O(|V|); com |V| chamadas: tempo é O( |V|2 ) Ordenação topológica Ordenação dos vértices de um DAG tal que, se existe um caminho de v para w, então v aparece antes de w
Versão ineficiente void topsort()throws CycleFound { Vertex v, w; for(int conta = 0; conta <= NUM_VERTEX; conta ++) { v = novo_Vertice_Indegree_Zero(); if( v == null ) throw new CycleFound() v.topNum = conta; for each w adjacent to v w.indegree--; } }
melhoria: em cada iteração, colocar numa fila (ou pilha) os vértices com indegree=0 em cada passo, é retirado da fila um qualquer dos vértices presentes ao actualizar o indegree na lista de adjacências do vértice a eliminar colocam-se na fila os que passam a ter indegree=0 inicialização põe na fila os vértices com indegree=0 à partida tempo de execução O(|E| + |V|) - o corpo do ciclo de actualização do indegree é executado no máximo uma vez por aresta - as operações na fila são executadas no máximo uma vez por vértice - a inicialização leva um tempo proporcional ao tamanho do grafo Refinamento da ordenação topológica
Algoritmo refinado void topsort ()throws CycleFound { int counter = 0; Vertex v, w; Queue q; q= new Queue(); for each vertex v if ( v.indegree == 0 ) q.enqueue( v ); while( !q.isEmpty() ) { v = q.dequeue(); v.topNum = ++counter; for each w adjacent to v if( --w.indegree == 0 ) q.enqueue( w ); } if( counter != NUM_VERTEX ) throw new CycleFound(); }
Execução no grafo de exemplo indegree anterior a cada operação dequeue Vértice 1 2 3 4 5 6 7 v1 0 0 0 0 0 0 0 v2 1 0 0 0 0 0 0 v3 2 1 1 1 0 0 0 v4 3 2 1 0 0 0 0 v5 1 1 0 0 0 0 0 v6 3 3 3 3 2 1 0 v7 2 2 2 1 0 0 0 enqueue v1 v2 v5 v4 v3,v7 v6 dequeue v1 v2 v5 v4 v3 v7 v6
Exemplo: rede de computadores, com custo de comunicação e de atraso dependente do encaminhamento (o caminho mais curto de v7 para v6 tem custo 1) arestas com custo negativo complicam o problema ciclos com custo negativo tornam o caminho mais curto indefinido (de v4 a v7 o custo pode ser 2 ou -1 ou -7 ou …) Outro exemplo: se o grafo representar ligações aéreas, o problema típico poderá ser: Dado um aeroporto de partida obter o caminho mais curto para um destino não há algoritmo que seja mais eficiente a resolver este problema do que a resolver o mais geral 2 1 2 4 -10 1 3 1 5 3 5 4 6 2 2 6 1 6 7 Caminho mais curto Dado um grafo pesado G = (V, E) e um vértice s, obter o caminho pesado mais curto de s para cada um dos outros vértices em G
pretende-se o comprimento dos caminhos: pode ser visto como um caso particular em que o peso de cada aresta é unitário começa-se por marcar o vértice inicial s com comprimento 0 sucessivamente, passa-se aos que lhe estão adjacentes e marcam-se com mais 1 do que o valor do caminho até ao antecedente progride-se por níveis, passando ao nível seguinte só depois de ter esgotado o anterior este tipo de pesquisa em grafos designa-se por pesquisa em largura semelhante à travessia por níveis de uma árvore código usa uma tabela em que regista, para cada vértice v - a distância de cada vértice ao inicial (dist) - se o vértice já foi processado (known) - qual o antecessor no caminho mais curto (path) 1 - Caminho não pesado
v1 v1 v1 v2 v2 v2 v1 v2 v3 v3 v3 v3 v4 v4 v4 v5 v5 v5 v4 v5 v6 v6 v6 v7 v7 v7 v6 v7 Evolução da marcação do grafo 1 0 0 1 1 1 2 2 0 0 2 2 3 3 1 1
Algoritmo básico void unweighted( Vertex s) { Vertex v, w; s.dist = 0; for(int currDist = 0; currDist < NUM_VERTEX; currDist++) for each vertex v if( !v.known && v.dist == currDist ) { v.known = true; for each w adjacent to v if( w.dist == INFINITY ) { w.dist = currDist + 1; w.path = v; } } }
tempo de execução O(|V|^2), devido aos ciclos for encaixados remoção da ineficiência semelhante à da ordenação topológica em cada momento, só existem dois tipos de vértices não processados com Dist - os do nível corrente (dist = currDist) ainda não processados e os adjacentes a estes já marcados no nível seguinte (dist=currDist+1) podiam guardar-se em duas caixas diferentes mas, como só se marca o primeiro do nível seguinte depois de ter todos os do nível corrente, basta usar uma fila o atributo known não é usado nesta solução Eficiência do algoritmo básico
Algoritmo refinado void unweighted( Vertex s) { Vertex v, w; Queue q; q= new Queue(); q.enqueue (s); s.dist = 0; while( !q.isEmpty() ) { v = q.dequeue(); v.known = true; //agora desnecessário for each w adjacent to v if( w.dist == INFINITY ) { w.dist = v.dist + 1; w.path = v; q.enqueue( w ); } }} • tempo de execução é O(|E| + |V|), com grafo representado por lista de adjacências
Evolução da estrutura de dados Início Visita v3 Visita v1 Visita v6 v known dv pv known dv pv known dv pv known dv pv v1 0 0 0 1 v3 1 1 v3 1 1 v3 v2 0 0 0 0 0 2 v1 0 2 v1 v3 0 0 0 1 0 0 1 0 0 1 0 0 v4 0 0 0 0 0 2 v1 0 2 v1 v5 0 0 0 0 0 0 0 0 v6 0 0 0 1 v3 0 1 v3 1 1 v3 v7 0 0 0 0 0 0 0 0 Q v3 v1, v6 v6, v2, v4 v2, v4
Evolução da estrutura de dados Visita v2 Visita v4 Visita v5 Visita v7 v Known dv pv Known dv pv Known dv pv Known dv pv v11 1 v3 1 1 v3 1 1 v3 1 1 v3 v21 2 v1 1 2 v1 1 2 v1 1 2 v1 v3 1 0 0 1 0 0 1 0 0 1 0 0 v40 2 v1 1 2 v1 1 2 v1 1 2 v1 v50 3 v2 0 3 v2 1 3 v2 1 3 v2 v61 1 v3 1 1 v3 1 1 v3 1 1 v3 v7 0 0 0 3 v4 0 3 v4 0 3 v4 Q v4, v5 v5, v7 v7 (vazia)
a solução é uma modificação da anterior cada vértice mantém uma distância ao inicial, obtida somando pesos nos caminhos quando se declara um vértice known , exploram-se os seus adjacentes; se o caminho através deste nó é melhor que o já registado, modifica-se este distância corrente em cada vértice: a melhor usando apenas vértices já processados o ponto crucial: escolher para declarar known o vértice que tiver o menor custo até ao momento é o único cujo custo não pode diminuir todas as melhorias de caminhos que usam este vértice são exploradas este é um exemplo de um algoritmo ganancioso: em cada passo faz o que melhora o ganho imediato restrição: só é válido se não existirem custos negativos regista-se o vértice antecedente, responsável directo pelo custo estimado; seguindo a sequência recupera-se o caminho mínimo 2 - Caminho pesado
2 2 v1 v2 v1 v2 4 4 1 10 1 10 3 3 v3 2 v3 2 v4 v5 v4 v5 2 2 8 8 4 4 5 6 5 6 v6 v7 v6 v7 1 1 2 2 v1 v2 v1 v2 4 4 1 10 1 10 3 3 v3 2 v3 2 v4 v5 v4 v5 2 2 8 8 4 4 5 6 5 6 v6 v7 v6 v7 1 1 Estádios do algoritmo de Dijkstra
2 v1 v2 4 1 10 3 v3 2 v4 v5 2 8 4 5 6 v6 v7 1 2 2 v1 v2 v1 v2 4 4 1 10 1 10 3 3 v3 2 v3 2 v4 v5 v4 v5 2 2 8 8 4 4 5 6 5 6 v6 v7 v6 v7 1 1 Estádios do algoritmo de Dijkstra 2 v1 v2 4 1 10 3 v3 2 v4 v5 2 8 4 5 6 v6 v7 1
Evolução da estrutura de dados Início Visita v1 Visita v4 Visita v2 v known dv pv known dv pv known dv pv known dv pv v1 0 0 0 1 0 0 1 0 0 1 0 0 v2 0 0 0 2 v1 0 2 v1 1 2 v1 v3 0 0 0 0 0 3 v4 0 3 v4 v4 0 0 0 1 v1 1 1 v1 1 1 v1 v5 0 0 0 0 0 3 v40 3 v4 v6 0 0 0 0 0 9 v4 0 9 v4 v7 0 0 0 0 0 0 0 5 v4
Evolução da estrutura de dados Visita v5 Visita v3 Visita v7 Visita v6 v known dv pv known dv pv known dv pv known dv pv v11 0 0 1 0 0 1 0 0 1 0 0 v21 2 v11 2 v1 1 2 v1 1 2 v1 v30 3 v4 1 3 v4 1 3 v4 1 3 v4 v41 1 v1 1 1 v1 1 1 v1 1 1 v1 v5 1 3 v41 3 v41 3 v41 3 v4 v60 9 v4 0 8 v3 0 6 v7 1 6 v7 v7 0 5 v40 5 v41 5 v41 5 v4
Algoritmo de Dijkstra void Dijkstra( Vertex s) { Vertex v, w; s.dist = 0; for( ; ; ) { v = vertice_a_menor_distancia; if( v == null ) break; v.known = true; for each w adjacent to v if( !w.known ) if v.dist + c(v,w) < w.dist ) { w.dist = v.dist + c(v,w); w.path = v; } }}
problema: pesquisa do mínimo método de percorrer a tabela até encontrar o mínimo é O(|V|) em cada fase; gasta-se O(|V|2) tempo ao longo do processo tempo de corrigir a distância é constante por actualização e há no máximo uma por aresta, num total de O(|E|) tempo de execução fica O(|E| + |V|2) = O(|V|2) se o grafo for denso |E| = Q(|V|2) e o resultado é satisfatório pois corre em tempo linear no número de arestas se o grafo fôr esparso |E| = Q(|V|), o algoritmo é demasiado lento melhoria: manter as distâncias numa fila de prioridade para obter o mínimo eficientemente O(log |V|), com uma operação deleteMin como as distâncias vão sendo alteradas no processo e a operação de Busca é ineficiente nas filas de prioridade, pode-se meter na fila mais do que um elemento para o mesmo vértice, com distâncias diferentes, e ter o cuidado, ao apagar o mínimo, de verificar se o vértice já está processado Análise do algoritmo O(|E| log |V|) actualização dos pesos com operação decreaseKey na fila O(|V| log |V|) percorrer os vértices com operação deleteMin para cada Tempo de execução total: O(|E| log |V|)
Algoritmo de Dijkstra não funciona custo ao longo de um caminho não é monótono depois de se marcar um vértice como processado pode aparecer um caminho mais longo mas com custo inferior Combinar os algoritmos para os caminhos pesado e sem peso usar uma fila; colocar o vértice inicial em cada passo retirar um vértice v da fila para cada vértice w adjacente a v tal que dist(w) dist(v) + cost(v, w)Þ actualizar dist(w), path(w) e colocar w na fila, se lá não estiver manter uma indicação de presença na fila 3 - Arestas com custos negativos
Exemplo: custos negativos 2 Achar os caminhos de menor custo a começar em 1. 1 2 4 10 1 -2 2 2 3 5 4 8 4 5 6 1 6 7 0 2 0 2 vértice 2 não altera nada … Dijkstra 2 2 1 2 1 2 4 10 4 10 1 -2 1 -2 1 1 2 2 2 3 5 3 2 4 3 3 5 4 8 8 4 4 5 6 5 6 1 6 7 1 6 7 9 5 0 2 2 1 2 4 10 1 -2 0 seria necessário rever 4 e propagar as alterações; piora o tempo … 2 2 pretendido: 3 5 2 4 2 8 4 5 6 1 6 7 8 4
pode ser necessário processar cada vértice mais do que uma vez (max: |V|) actualização pode ser executada O(|E|.|V|), usando listas de adjacência Algoritmo com custo negativo void weightedNegative( Vertex s) { Vertex v, w; Queue q; q = new Queue(); q.enqueue (s); while( !q.isEmpty() ) { v = q.dequeue(); for each w adjacent to v if v.dist + c(v,w) < w.dist ) { w.dist = v.dist + c(v,w); w.path = v; if(w not in q) ) q.enqueue(w); } } } • ciclo de custo negativo Þ algoritmo não termina • teste de terminação: algum vértice sai da fila mais do que |V|+1 vezes
simplificação do algoritmo de Dijkstra exigência de selecção, em cada passo, do vértice mínimo é dispensável nova regra de selecção: usar a ordem topológica um vértice processado jamais pode vir a ser alterado: não há ramos a entrar não é necessária a fila de prioridade ordenação topológica e actualização das distâncias combinadas numa só passagem aplicações em processos não reversíveis não se pode regressar a um estado passado (certas reacções químicas) deslocação entre dois pontos em esqui (sempre descendente) aplicações de Investigação Operacional modelar sequências de actividades em projectos grafos nó-actividade - nós representam actividades e respectiva duração - arcos representam precedência (um arco de v para w significa que a actividade em w só pode ser iniciada após a conclusão da de v) Þ acíclico 4 - Grafos acíclicos
Grafos Nó-Actividade Nó: actividade e tempo associado Arco: precedência C(3) A(3) F(3) D(2) H(1) início fim B(2) G(2) K(4) E(1) Qual a duração total mínima do projecto? Quais as actividades que podem ser atrasadas e por quanto tempo (sem aumentar a duração do projecto)?
nó = evento arco = actividade • evento: fim de actividade Reformulação em Grafo Nó-Evento Nó: evento- completar actividade Arco: actividade C/3 2 4 0 A/3 F/3 0 7’ 7 0 0 D/2 H/1 6’ 6 1 10’ 10 0 0 G/2 8’ 8 0 0 B/2 0 E/1 K/4 9 3 5 • reformulação introduz nós e arcos extra para garantir precedências
• menor tempo de conclusãoÛ caminho mais comprido do evento inicial ao nó • problema (se grafo não fosse acíclico): ciclos de custo positivo • adaptar algoritmo de caminho mais curto MTC(1) = 0 MTC(w) = max( MTC(v) + c(v,w) ) (v, w) Î E Menor Tempo de Conclusão MTC : usar ordem topológica 3 6 C/3 2 4 0 6 9 A/3 F/3 0 7’ 7 0 3 5 9 10 0 0 D/2 H/1 6’ 6 1 10’ 10 0 5 7 0 G/2 8’ 8 0 0 7 2 3 B/2 0 E/1 9 K/4 3 5
Último Tempo de Conclusão • • último tempo de conclusão: mais tarde que uma actividade pode terminar sem comprometer as que se lhe seguem • UTC(n) = MTC(n) • UTC(v) = min( UTC(w) - c(v w) ) • (v, w) Î E UTC : usar ordem topológica inversa valores calculados em tempo linear mantendo listas de adjacentes e de precedentes dos nós 3 6 C/3 2 4 0 6 9 A/3 F/3 3 6 0 7’ 7 0 3 5 9 10 0 0 D/2 H/1 6 9 6’ 6 1 10’ 10 0 5 0 7 G/2 0 4 6 9 10 8’ 8 0 0 7 2 3 B/2 0 7 9 E/1 9 K/4 3 5 9 4 5
Folgas nas actividades • • folga da actividade • folga(v,w) = UTC(w)-MTC(v)-c(v,w) 3 6 C/3/0 2 4 6 9 A/3/0 F/3/0 3 6 7’ 7 0 3 5 9 10 D/2/1 H/1/0 6 9 6’ 6 1 10’ 10 5 7 G/2/2 0 4 6 9 10 8’ 8 7 2 3 B/2/2 7 9 E/1/2 9 K/4/2 3 5 9 4 5 Caminho crítico: só actividades de folga nula (há pelo menos 1)
Exemplos abastecimento de líquido ponto a ponto tráfego entre dois pontos - s: fonte; t: poço - distribuição de fluxo pelos arcos arbitrária, desde que respeite as setas Problemas de fluxo numa rede Modelar fluxos conservativos entre dois pontos através de canais com capacidade limitada s s • Fluxo num arco não pode ultrapassar a capacidade • Soma das entradas num nó igual à soma das saídas 3 2 3 2 1 0 a b a b 4 1 3 2 2 2 c d c d 2 3 2 3 t t
algoritmo simples de aproximações sucessivas baseado em G ä grafo base de capacidades Gf ä grafo auxiliar de fluxos - inicialmente fluxos iguais a 0 - no fim, fluxo máximo Gr ä grafo residual (auxiliar) - capacidade disponível em cada arco (= capacidade - fluxo) - capacidade disponível = 0 — eliminar arco saturado método de calcular o fluxo máximo entre s e t em cada iteração, selecciona-se um caminho em Gr entre s e t (de acréscimo) —algoritmo não determinístico valor mínimo nos arcos desse caminho = quantidade a aumentar a cada um dos arcos respectivos em Gf recalcular Gr termina quando não houver caminho de s para t Fluxo máximo: 1ª abordagem
Exemplo: estado inicial s s s 3 2 0 0 3 2 1 0 1 a b a b a b 4 0 4 3 2 0 0 3 2 c d c d c d 2 3 0 0 2 3 t t t G Gf Gr
Exemplo: 1ª iteração s s s 3 2 0 2 3 1 0 1 a b a b a b 4 0 4 3 2 0 2 3 c d c d c d 2 3 0 2 2 1 t t t G Gf Gr
Exemplo: 2ª iteração s s s 3 2 2 2 1 1 0 1 a b a b a b 4 0 4 3 2 2 2 1 c d c d c d 2 3 2 2 1 t t t G Gf Gr
Exemplo: 3ª iteração s s s 3 2 3 2 1 0 1 a b a b a b 4 1 3 3 2 2 2 1 c d c d c d 2 3 2 3 t t t G Gf Gr
critério ganancioso de selecção do caminho: escolher o que dê maior fluxo - caminho s, a, d, t (3 unidades de fluxo) ä algoritmo termina sem obter o máximo - exemplo de algoritmo ganancioso que falha Algoritmo não garante fluxo óptimo s s s 3 2 3 0 2 1 0 1 a b a b a b 4 3 1 3 2 0 0 3 2 c d c d c d 2 3 0 3 2 t t t
para cada arco (v,w) com fluxo f(v,w) no grafo de fluxos acrescenta-se um arco (w,v) no grafo residual com capacidade f(v,w) - corresponde a deixar devolver fluxo para trás (nunca fica globalmente negativo, contra o arco) - podem existir arcos em sentidos opostos; podem existir ciclos se as capacidades forem números racionais, o algoritmo termina com máximo se as capacidades forem inteiros e o fluxo máximo f - bastam f estádios (fluxo aumenta pelo menos 1 por estádio) - tempo de execução ( caminho mais curto não pesado ) é O(f. |E| ) ä mau evitar o problema - escolher caminho que dá maior aumento de fluxo - semelhante ao problema do caminho pesado mais curto (pequena alteração a Dijkstra) - fluxo máximo em O(|E| log capMax) (capMax = capacidade máxima de um arco) - cada cálculo de um aumento em O(|E| log |V|) (Dijkstra) - global: O(|E|^2 log |V| log capMax) Algoritmo determinístico permitir que o algoritmo mude de ideias
Solução óptima - 1ª iteração s s s 3 2 3 0 3 2 1 0 1 a b a b a b 4 3 1 3 2 0 0 3 2 3 c d c d c d 2 3 0 3 2 3 t t t G Gf Gr 3 unidades de fluxo no caminho sadt
Solução óptima - 2ª iteração s s s 3 2 3 2 3 2 1 0 1 a b a b a b 4 1 3 3 2 2 2 2 3 2 1 c d c d c d 2 3 2 3 2 3 t t t G Gf Gr 2 unidades de fluxo no caminho s,b,d,a,c, t
Caso difícil - se se escolher passar sempre por a e por b… s 1 000 000 1 000 000 1 b a 1 000 000 1 000 000 t s s 1 000 000 1 999 999 1 1 1 b b a a 1 1 000 000 999 999 1 t t s s 999 999 1 999 999 1 1 1 1 0 b b a a 1 1 … temos 2 000 000 de iterações, em vez de 2! 999 999 1 999 999 1 t t
caso do grafo não dirigido grafo tem que ser conexo árvore Þ acíclico número de arestas = |V| - 1 Árvores de expansão mínimas Árvore que liga todos os vértices do grafo usando arestas com um custo total mínimo • exemplo de aplicação: cablamento de uma casa • - vértices são as tomadas • - arestas são os comprimentos dos troços
idêntico ao algoritmo de Dijkstra para o caminho mais curto informação para cada vértice - dist(v) é o custo mínimo das arestas que ligam a um vértice já na árvore - path(v) é o último vértice a alterar dist(v) - known(v) indica se o vértice jé foi processado (isto é, se já pertence à árvore) diferença na regra de actualização: após a selecção do vértice v, para cada w não processado, adjacente a v, dist(w) = min{ dist(w), cost(w,v) } tempo de execução - O( |V|2 ) sem fila de prioridade - O( |E| log |V| ) com fila de prioridade Algoritmo de Prim • expandir a árvore por adição sucessiva de arestas e respectivos vértices • critério de selecção: escolher a aresta (u,v) de menor custo tal que u já pertence à árvore e v não (ganancioso) • início: um vértice qualquer
known dist path 1 0 0 1 2 1 1 2 4 1 1 1 1 6 7 1 1 7 1 4 4 Evolução do algoritmo de Prim última tabela 2 1 2 4 10 1 3 7 2 3 5 4 8 4 5 6 1 6 7 ¶ ¸ · ¹ 2 2 1 1 1 2 1 2 1 1 2 4 4 3 4 º » ¼ 2 2 2 1 2 1 2 1 2 1 1 1 2 2 2 3 3 4 4 3 5 4 4 4 4 6 1 6 1 7 7 6 7
aceitação de arestas — algoritmo de Busca/União em conjuntos representados como árvores se dois vértices pertencem à mesma árvore/conjunto, mais uma aresta entre eles provoca um ciclo (2 Buscas) se são de conjuntos disjuntos, aceitar a aresta é aplicar-lhes uma União selecção de arestas: ordenar por peso ou, melhor, construir fila de prioridade em tempo linear e usar Apaga_Min tempo no pior caso O( |E| log |E| ), dominado pelas operações na fila Algoritmo de Kruskal • analisar as arestas por ordem crescente de peso e aceitar as que não provocarem ciclos (ganancioso) • método • manter uma floresta, inicialmente com um vértice em cada árvore (há |V|) • adicionar uma aresta é fundir duas árvores • quando o algoritmo termina há só uma árvore (de expansão mínima)
Pseudocódigo (Kruskal) void kruskal() { DisjSet s; PriorityQueue h; Vertex u, v; SetType uset, vset; Edge e, int edgesAccepted = 0; h = readGraphIntoHeapArray(); h.buildHeap(); s = new DisjSet(NUM_VERTICES); while(edgesAccepted < NUM_VERTICES -1 ) { e = h.deleteMin(); // e = (u,v) uset = s.find(u); vset = s.find(v); if (uset != vset) { edgesAccepted++; S.union(uset, vset); } }}
2 1 2 4 10 1 3 7 2 3 5 4 8 4 5 6 1 6 7 Evolução do algoritmo de Kruskal ¶ 1 2 3 5 4 6 7 · ¸ 1 2 1 2 1 1 3 5 4 3 5 4 1 6 7 6 7