Download

1 / 27
270 likes | 412 Views
Ditribución del valor extremo. Distribucion del maximo de N scores de matching de secuencias random independientes Si la probabilidad de este maximo de ser mayor que el mejor valor observado es pequeña, luego el score es significativo

E N D
Ditribución del valor extremo • Distribucion del maximo de N scores de matching de secuencias random independientes • Si la probabilidad de este maximo de ser mayor que el mejor valor observado es pequeña, luego el score es significativo • La distribucion del maximo de N variables aleatorias normales e independientes es conocida Nota: Ver cap. 11 de Durbin
Alineamiento Local - Motivación • Si el mejor alineamiento hasta un punto determinado tiene un score negativo es mejor empezar otro nuevo • Los alineamientos pueden terminar en cualquier lugar de la matriz no en (n,m) • Para el mejor alineamiento, empezamos buscando el mejor F(i,j) de toda la matriz y empezamos la traza inversa desde alli • La traza termina al llegar al score 0 • Esperamos que el score de un matching aleatorio sea negativo, sino: • largos alineamientos incorrectos parecidos al global
Global: encontrar el mejor alineamiento, tal vez a expensas de zonas de mayor similaridad Son estas secuencias en general similares? Local: encontrar zonas con el mejor alineamiento, inclusive a expensas del score general Contienen estas secuencias subsecuencias con alta similaridad?
Alineamientos repetidos • Encuentra una o + copias, significativas a nivel T, de secciones de una secuencia en otra (y en x) • Significación T: Score_alineamiento -T > 0 • F(i,0) muestra las no coincidencias y los fines de matching (score >T) • F(i,j) muestra los comienzos de matching y las extensiones, F(i,0) reemplaza el 0 local por el grado de coincidencia de la seccion anterior
Alineamientos repetidos (continuación) • Alineamiento global • Alin. Dependiente de T (grado de significación) • La traza comienza en (n+1,0), si es igual a 0 no hubo matchings
Alineamientos solapados o anidados • Se busca un alineamiento global sin restricciones • La traza se realiza a partir del mayor score • Comienza en el borde superior o izquierdo y termina en el inferior o derecho
Otros ejemplos • Secuencia repetitiva y en “tandem” sin gaps • Match que comience en (0,0) y termine en cualquier lado Cuando se busca la similaridad de una secuencia secuencia debemos pensar el tipo de matching o coincidencia deseado y buscar el algoritmo mas apropiado
Automatas de estado mas complejos • Los scores s(a,b) y t(a,b) pueden representar regiones de mayor fidelidad sin gaps (A) y de menor con gaps (B) • Valores probabilisticos en los ejes caracterizarian a un modelo de Markov
Cadenas de Markov • Dada una secuencia , podemos decidir si viene de una isla CG? • Uso de cadenas de Markov para discriminacion/clasificacion • Dado un conjunto de entrenamiento, aprendemos un modelo que nos permite discriminar futuras secuencias no observadas
Aplicando P(X,Y)=P(X/Y) P(Y) mujchas veces, y la propiedad que un estado Markoviano depende solo del anterior
¿Qué significa Aprendizaje? Decimos que un agente o un programa de computación aprende de la experiencia E con respecto a cierta clase de tareas T con la medida de performance P, si su performance en la tarea T, medida por P, mejora con respecto a la experiencia E Tarea: Reconocer y clasificar palabras manuscritas Medida de Performance: Porcentaje de palabras bien reconocidas o clasificadas Experiencia de Entrenamiento: Una base de datos de palabras manuscritas reconocidas o clasificadas previamente
Que se aprende? Estructura, parametros, ajustes (identificacion de sistemas) • No solo el orden caracteriza a los algoritmos, tambien el sesgo de aprendizaje • Generalizacion • Sobreaprendizaje
Modelos Hidden Markov Como podemos encontrar islas CG en una secuencia no observada? • Distinguir entre: • Sucesion de estados, la probabilidad de un estado depende del anterior (k,k-1) • Sucesion de simbolos, la probabilidad de observar el carácter b en el estado k (depende de la distrib. De simbolos, i.e., no es necesario asociar un estado a un simbolo).
Algoritmo de Viterbi (Camino mas probable) Aplicando el algoritmo “predictivo” encontramos los limites de las islas CG o de los estados de los dados (casino)
Estimación de los parametros • Cuando, dado un conjunto de entrenamiento conozco los caminos • Akl=numero de transiciones de k a l • Akl’=numero de tranciciones a otros estado • akl=Akl/SUMA(Akl’) • Ek(b)=numero de emisiones de b en k • ek(b)=Ek(b)/SUMA(E(b’)) • Cuando no conozco los caminos • Algoritmos de optimizacion de funciones continuas
Alineamiento de a pares usando HMMs Tal como los HMM estándar generan una secuencia, estos generan un par de secuencias alineadas
Estados iniciales y finales mas complejos (ver diferencias para alin. Locales y globales) • El estado M tiene una probabilidad de emision Pab, de emitir el alineamiento a:b • X, Qa de emitir el simbolo a:gap (idem Y)
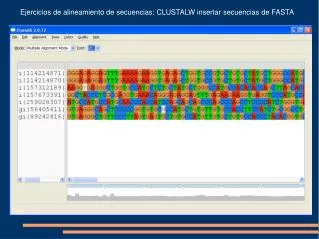
Alineamiento multiple empleando HMM • Emplear un metodo de alineaminto previo (gradual) en base a un conjunto de entrenamiento (e.g. Clustal W) • Aplicar HMM http://www.cse.ucsc.edu/research/compbio/sam.html
Importante: el mundo no es lineal, euclideo y deterministico • Dado un Problema, existen varios Modelos para representarlos, y posibles Soluciones a dicho Modelo (P->M->S) • Existen distintas formas de obtener dichas Ss (Soluciones exactas, heuristicas, metaheuristicas, etc.) • Conocer cual es la mas adecuada depende de varios factores, ej. Orden del algoritmo, Sesgo, tipo de modelo (lineal, estocastico, etc.), dependencia de los parametros, condicionamientos del metodo, etc. • Los algoritmos no necesariamente estan involucrados con el dominio del problema. Muchas soluciones se obtienen reinterpretando soluciones correspondientes a otros problemas (RN y física, tecnologia del habla -HMM, etc.)