Download

1 / 69
690 likes | 714 Views
Explore the evolution of batch computing into data-intensive workloads, challenges with environmental transparency, and approaches to run data-intensive workloads remotely. Learn about data-aware scheduling policies and the need for knowledge of I/O behavior in batch workloads.

E N D
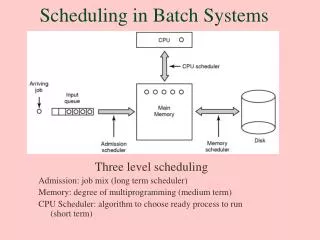
Data-Driven Batch Scheduling John Bent Ph.D. Oral Exam Department of Computer Sciences University of Wisconsin, Madison May 31, 2005
Batch Computing • Highly successful, widely-deployed technology • Frequently used across the sciences • As well as in video production, document processing, data mining, financial services, graphics rendering • Evolved into much more than a job queue • Manages multiple distributed resources • Handles complex job dependencies • Checkpoints and migrates running jobs • Enables transparent remote execution • Environmental transparency is becoming problematic
Problem with Environmental Transparency • Emerging trends • Data sets are getting larger [Roselli00,Zadok04,LHC@CERN] • Data growth outpacing increase in processing ability [Gray03] • More wide-area resources are available [Foster01,Thain04] • Users push successful technology beyond design [Wall02] • Batch schedulers are CPU-centric • Ignore data dependencies • Data movement happens as a side-effect of job placement • Great for compute-intensive workloads executing locally • Horrible for data-intensive workloads executing remotely • How to run data-intensive workloads remotely?
Approaches to Remote Execution • Direct I/O: Direct remote data access • Simple and reliable • Large throughput hit • Prestaging Data: Manipulating environment • Allows remote execution without performance hit • High user burden • Fault tolerance, restarts are difficult • Distributed File Systems: AFS, NFS, etc. • Designed for wide-area networks and sharing • Infeasible across autonomous domains • Policies not appropriate for batch workloads
Common Fundamental Problem • Layers upon CPU-centric scheduling • Data planning external to the scheduler • “Second class citizen in batch scheduling” • Data-aware scheduling policies needed • Knowledge of I/O behavior of batch workloads • Support from the file system • Data-driven batch scheduler
Outline • Intro • Profiling data-intensive batch workloads • File system support • Data-driven scheduling • Conclusions and contributions
Selecting Workloads to Profile • General characteristics of batch workloads? • Select a representative suite of workloads • BLAST biology • IBIS ecology • CMS physics • Hartree-Fock chemistry • Nautilus molecular dynamics • AMANDA astrophysics • SETI@home astronomy
Key Observation:Batch-Pipeline Workloads • Workloads consist of many processes • Complex job and data dependencies • Three types of data and data sharing • Vertical relationships: Pipelines • Processes often are vertically dependent • Output of parent becomes input to child • Horizontal relationships: Batches • Users often submit multiple pipelines • May be read sharing across siblings
Endpoint Endpoint Batch dataset Endpoint Pipeline Pipeline Batch dataset Batch-Pipeline Workloads Batch width Endpoint Endpoint Pipeline Pipeline Pipeline Pipeline Pipeline Pipeline Pipeline Endpoint Endpoint Endpoint Endpoint
Pipeline Observations • Large proportion of random access • IBIS, CMS close to 100%, HF ~ 80% • No isolated pipeline is resource intensive • Max memory is 500 MB • Max disk bandwidth is 8 MB/s • Amdahl and Gray balances skewed • Drastically overprovisioned in terms of I/O bandwidth and memory capacity
Workload Observations • These pipelines are NOT run in isolation • Submitted in batch widths of 100s, 1000s • Run in parallel on remote CPUs • Large amount of I/O sharing • Batch and pipeline I/O are shared • Endpoint I/O is relatively small • Scheduler must differentiate I/O types • Scalability implications • Performance implications
Bandwidth needed for Direct I/O Storage center (1500 MB/s) Commodity disk (40 MB/s) • Bandwidth needed for all data (i.e. endpoint, batch, pipeline). • Only seti, ibis, and cms can scale to greater than 1000.
Eliminate Pipeline Data Storage center (1500 MB/s) Commodity disk (40 MB/s) • Endpoint and batch data is accessed at submit site. • Better . . .
Eliminate Batch Data Storage center (1500 MB/s) Commodity disk (40 MB/s) • Bandwidth needed for endpoint and pipeline data. • Better . . .
Complete I/O Differentiation Storage center (1500 MB/s) Commodity disk (40 MB/s) • Only endpoint traffic is incurred at archive storage. • Best. All can scale to batch width greater than 1000.
Outline • Intro • Profiling data-intensive batch workloads • File system support • Develop new distributed file system: BAD-FS • Develop capacity-aware scheduler • Evaluate against CPU-centric scheduling • Data-driven scheduling • Conclusions and contributions
Why a New Distributed File System? Internet Home store • User needs mechanism for remote data access • Existing distributed file systems seem ideal • Easy to use • Uniform name space • Designed for wide-area networks • But . . . • Not practically deployable • Embedded decisions are wrong
Existing DFS’s make bad decisions • Caching • Must guess what and how to cache • Consistency • Output: Must guess when to commit • Input: Needs mechanism to invalidate cache • Replication • Must guess what to replicate
BAD-FS makes good decisions • Removes the guesswork • Scheduler has detailed workload knowledge • Storage layer allows external control • Scheduler makes informed storage decisions • Retains simplicity and elegance of DFS • Uniform name space • Location transparency • Practical and deployable
Batch-Aware Distributed File System:Practical and Deployable • User-level; requires no privilege • Packaged as a modified batch system • A new batch system which includes BAD-FS • General; will work on all batch systems SGE SGE SGE SGE BAD- FS BAD- FS BAD- FS BAD- FS BAD- FS BAD- FS BAD- FS BAD- FS SGE SGE SGE SGE Internet Home store
Storage Manager Storage Manager Storage Manager Storage Manager Jobqueue 1 2 3 4 Modified Batch System Compute node Compute node Compute node Compute node CPU Manager CPU Manager CPU Manager CPU Manager BAD-FS BAD-FS BAD-FS 1) Storage managers 2) Batch-Aware Distributed File System Job queue 3) Expanded job description language 4) Data-aware scheduler Home storage Data-aware Scheduler Scheduler
Requires Knowledge • Remote cluster knowledge • Storage availability • Failure rates • Workload knowledge • Data type (batch, pipeline, or endpoint) • Data quantity • Job dependencies
Requires Storage Control • BAD-FS exports explicit control via volumes • Abstraction allowing external storage control • Guaranteed allocations for workload data • Specified type: either cache or scratch • Scheduler exerts control through volumes • Creates volumes to cache input data • Subsequent jobs can reuse this data • Creates volumes to buffer output data • Destroys pipeline, copies endpoint • Configures workload to access appropriate volumes
Knowledge Plus Control • Enhanced performance • I/O scoping • Capacity-aware scheduling • Improved failure handling • Cost-benefit replication • Simplified implementation • No cache consistency protocol
I/O Scoping • Technique to minimize wide-area traffic • Allocate volumes to cache batch data • Allocate volumes for pipeline and endpoint • Extract endpoint Compute node Compute node AMANDA: 200 MB pipeline 500 MB batch 5 MB endpoint Internet Steady-state: Only 5 of 705 MB traverse wide-area. BAD-FS Scheduler
Capacity-Aware Scheduling • Technique to avoid over-allocations • Over-allocated batch data causes WAN thrashing • Over-allocated pipeline data causes write failures • Scheduler has knowledge of • Storage availability • Storage usage within the workload • Scheduler runs as many jobs as can fit
Endpoint Endpoint Endpoint Endpoint Batch dataset Batch dataset Batch dataset Pipeline Pipeline Endpoint Endpoint Endpoint Pipeline Pipeline Endpoint Batch dataset Capacity-Aware Scheduling Pipeline Pipeline Pipeline Pipeline Pipeline Pipeline Pipeline Pipeline Endpoint Endpoint Endpoint Endpoint
Capacity-aware scheduling • 64 batch-intensive synthetic pipelines • Four processes within each pipeline • Four different batch datasets • Vary size of batch data • 16 compute nodes
Improved failure handling • Scheduler understands data semantics • Data is not just a collection of bytes • Losing data is not catastrophic • Output can be regenerated by rerunning jobs • Cost-benefit replication • Replicates only data whose replication cost is cheaper than cost to rerun the job
Simplified implementation • Data dependencies known • Scheduler ensures proper ordering • Build a distributed file system • With cooperative caching • But without a cache consistency protocol
Setup Batch-width of 64 16 compute nodes Emulated wide-area Configuration Remote I/O AFS-like with /tmp BAD-FS Result is order of magnitude improvement Real workload experience
Outline • Intro • Profiling data-intensive batch workloads • File system support • Data-driven scheduling • Codify simplifying assumptions • Define data-driven scheduling policies • Develop predictive analytical models • Evaluate • Discuss • Conclusions and contributions
Simplifying Assumptions • Predictive models • Only interested in relative (not absolute) accuracy • Batch-pipeline workloads are “canonical” • Mostly uniform and homogeneous • Combine pipeline and endpoint data into private • Environment • Assume homogeneous compute nodes • Target scenario • Single workload on a single compute cluster
Predictive Accuracy:Choosing Relative over Absolute • Develop predictive models to guide scheduler • Absolute accuracy not needed • Relative accuracy to select between different possible schedules • Predictive model does not consider • Latencies • Disk bandwidths • Buffer cache size or bandwidth • Other “lower” characteristics such as buses, CPUs, etc • Simplify model and retain relative predictive accuracy • These effects are more uniform across different possible schedules • Network and CPU utilization make largest difference • The Trade-off?Loss of absolute accuracy
Canonical B-P Workload WWidth WPrivate WPrivate WBatch WRun WRun +/- +/- WVar WVar WPrivate WPrivate WDepth • Represented using six variables. WBatch WRun WRun +/- +/- WVar WVar WPrivate WPrivate
Target Compute Platform CFailure CStorage CStorage CRemote CLocal CCPU Storage Server Compute Cluster • Represented using five variables.
Scheduling Objective • Maximize throughput for user workloads • Easy without data considerations • Run as many jobs as possible • Potential problems with data considerations • WAN overutilization by resending batch data • Data barriers can reduce CPU utilization • Concurrency limits can reduce CPU utilization • Need data-driven policies to avoid these problems
Five Scheduling Allocations • Define allocations to avoid problems • All: Has no constraints; allows CPU-centric scheduling • AllBatch: Avoids overutilizing WAN and barriers • AllPrivate: Avoids concurrency limits • Slice: Avoids overutilizing WAN • Minimal: Attempts to maximize concurrency • Each allocation might incur other problems • Which problems are incurred by each?
Full concurrency No batch data refetch No barriers Requires most storage Minimum storage needed: WDepthWBatch + WWidthWPrivate(WDepth+1) Workflow for All Allocation
Limited concurrency No batch data refetch No barriers Minimum storage needed: WDepthWBatch + 2WPrivate Workflow for AllBatch allocation
Full concurrency No batch data refetch Barriers possible Minimum storage needed: WBatch + WWidthWPrivate(WDepth+1) Workflow for AllPrivate allocation
Limited concurrency No batch data refetch Barriers possible Minimum storage needed: WBatch + WWidthWPrivate +WPrivate Workflow for Slice allocation
Limited concurrency Batch data refetch Barriers possible Smallest storage footprint Minimum storage needed: WBatch + 2WPrivate Workflow for Minimal allocation
Selecting an allocation • Multiple allocations may be possible • Dependent on WWidthand WDepth • Dependent of WBatchand WPrivate • Which allocations are possible? • Which possible allocation is preferrable?
WWidth = 3, WDepth = 3 Only Minimal Possible Maximum Private Volume Size (% of CStorage) Minimal, Slice, AllBatch Possible All Five Allocations Possible Maximum Batch Volume Size (% of CStorage)
Analytical Modelling • How to select when multiple are possible? • Use analytical models to predict runtimes • Use 6 workload and 5 environmental constants • WWidth, WDepth, WBatch, WPrivate, WRun, WVar • CStorage,CFailure,CRemote,CLocal,CCPU
Slice Predictive Model • Slice has two phases of concurrency • At start and end of workload • Steady-state in the middle • Concurrency limited by remaining storage after allocating one volume for each pipeline • At start and end, fewer pipelines are allocated • Other allocations are more consistent