Download

1 / 142
1.42k likes | 1.43k Views
This study presents a stochastic nonparametric framework for ensemble hydrologic forecast and downscaling, using nonparametric methods such as kernel estimators, splines, and K-nearest neighbor estimators. The framework aims to provide more accurate and flexible predictions of hydroclimate variables for decision-making purposes.

E N D
Balaji Rajagopalan Department of Civil and Environmental Engg. University of Colorado Boulder, CO IRI / Lamont – Aug 2003 A Stochastic Nonparametric Framework for Ensemble Hydrologic Forecast and Downscaling
James Prairie, Katrina Grantz, Somkiat Apipattanavis, Nkrintra Singhrattna Subhrendu Gangopadhyay, Martyn Clark CIRES/University of Colorado, Boulder, CO Upmanu Lall (Lamont-Doherty Earth Observatory) Columbia University, NY David Yates NCAR/University of Colorado, Boulder, CO Acknowledgements
Inter-decadal Climate Decision Analysis: Risk + Values Time Horizon • Facility Planning • Reservoir, Treatment Plant Size • Policy + Regulatory Framework • Flood Frequency, Water Rights, 7Q10 flow • Operational Analysis • Reservoir Operation, Flood/Drought Preparation • Emergency Management • Flood Warning, Drought Response Data: Historical, Paleo, Scale, Models Weather Hours A Water Resources Management Perspective
Ensemble Forecast (or Scenarios generation) • Scenarios (synthetic sequences) of hydroclimate are simulated for various decision making situations Reservoir operations (USBR/Riverware) Erosion Prediction (USDA/WEPP) Reservoir sizing (Flood frequency) • Given [Yt] t = 1,2,…,N hydroclimate time series (e.g. daily weather variables, streamflow, etc.) Parametric models are fit (probability density functions – Gamma, Exponential etc.) Time series Models (Auto Regressive Models)
Hydrologic Forecasting • Conditional Statistics of Future State, given Current State • Current State: Dt : (xt, xt-t, xt-2 t, …xt-d1t, yt, yt- t, yt-2t, …yt-d2t) • Future State: xt+T • Forecast: g(xt+T) = f(Dt) • where g(.) is a function of the future state, e.g., mean or pdf • and f(.) is a mapping of the dynamics represented by Dt to g(.) • Challenges • Composition of Dt • Identify g(.) given Dt and model structure • For nonlinear f(.) , Nonparametric function estimation methods used • K-nearest neighbor • Local Regression • Regression Splines • Neural Networks
The Problem • Ensemble Forecast/Stochastic Simulation /Scenarios generation – all of them are conditional probability density function problems • Estimate conditional PDF and simulate (Monte Carlo, or Bootstrap)
Parametric Models • Periodic Auto Regressive model (PAR) • Linear lag(1) model • Stochastic Analysis, Modeling, and Simulation (SAMS) (Salas, 1992) • Data must fit a Gaussian distribution • Expected to preserve • mean, standard deviation, lag(1) correlation • skew dependant on transformation • gaussian probability density function
Parametric Models - Drawbacks • Model selection / parameter estimation issues Select a model (PDFs or Time series models) from candidate models Estimate parameters • Limited ability to reproduce nonlinearity and non-Gaussian features. All the parametric probability distributions are ‘unimodal’ All the parametric time series models are ‘linear’
Parametric Models - Drawbacks • Models are fit on the entire data set Outliers can inordinately influence parameter estimation (e.g. a few outliers can influence the mean, variance) Mean Squared Error sense the models are optimal but locally they can be very poor. Not flexible • Not Portable across sites
Nonparametric Methods • Any functional (probabiliity density, regression etc.) estimator is nonparametric if: It is “local” – estimate at a point depends only on a few neighbors around it. (effect of outliers is removed) No prior assumption of the underlying functional form – data driven
Nonparametric Methods • Kernel Estimators (properties well studied) • Splines • Multivariate Adaptive Regression Splines (MARS) • K-Nearest Neighbor (K-NN) Bootstrap Estimators • Locally Weighted Polynomials (K-NN Polynomials)
K-NN Philosophy • Find K-nearest neighbors to the desired point x • Resample the K historical neighbors (with high probability to the nearest neighbor and low probability to the farthest) Ensembles • Weighted average of the neighbors Mean Forecast • Fit a polynomial to the neighbors – Weighted Least Squares • Use the fit to estimate the function at the desired point x (i.e. local regression) • Number of neighbors K and the order of polynomial p is obtained using GCV (Generalized Cross Validation) – K = N and p = 1 Linear modeling framework. • The residuals within the neighborhood can be resampled for providing uncertainity estimates / ensembles.
K-Nearest Neighbor Estimators A k-nearest neighbor density estimate A conditional k-nearest neighbor density estimate f(.) is continuous on Rd, locally Lipschitz of order p k(n) =O(n2p/(d+2p)) A k-nearest neighbor ( modified Nadaraya Watson) conditional mean estimate
Classical Bootstrap (Efron): Given x1, x2, …... xn are i.i.d. random variables with a cdf F(x) Construct the empirical cdf Draw a random sample with replacement of size n from Moving Block Bootstrap (Kunsch, Hall, Liu & Singh) : Resample independent blocks of length b<n, and paste them together to form a series of length n k-Nearest Neighbor Conditional Bootstrap (Lall and Sharma, 1996) Construct the Conditional Empirical Distribution Function: Draw a random sample with replacement from
k-nearest neighborhoods A and B for xt=x*A and x*B respectively Logistic Map Example 4-state Markov Chain discretization
Define the composition of the "feature vector" Dt of dimension d. (1) Dependence on two prior values of the same time series. Dt : (xt-1, xt-2) ; d=2 (2) Dependence on multiple time scales (e.g., monthly+annual) Dt: (xt-t1, xt-2t1, .... xt-M1t1; xt-t2, xt-2t2, ..... xt-M2t2) ; d=M1+M2 (3) Dependence on multiple variables and time scales Dt: (x1t-t1, .... x1t-M1t1; x2t, x2t-t2, .... x2t-M2t2); d=M1+M2+1 Identify the k nearest neighbors of Dt in the data D1 ... Dn Define the kernel function ( derived by taking expected values of distances to each of k nearest neighbors, assuming the number of observations of D in a neighborhood Br(D*) of D*; r0, as n , is locally Poisson, with rate (D*)) for the jth nearest neighbor Selection of k: GCV, FPE, Mutual Information, or rule of thumb (k=n0.5)
Applications to date…. • Monthly Streamflow Simulation Space and time disaggregation of monthly to daily streamflow • Monte Carlo Sampling of Spatial Random Fields • Probabilistic Sampling of Soil Stratigraphy from Cores • Hurricane Track Simulation • Multivariate, Daily Weather Simulation • Downscaling of Climate Models • Ensemble Forecasting of Hydroclimatic Time Series • Biological and Economic Time Series • Exploration of Properties of Dynamical Systems • Extension to Nearest Neighbor Block Bootstrapping -Yao and Tong
y * t y t-1 K-NN Algorithm
e * t y * t y t-1 Residual Resampling yt = yt* + et*
Applications K-NN Bootstrap • Weather Generation – Erosion Prediction (Luce et al., 2003; Yates et al., 2003) • Precipitation/Temperature Downscaling (Clark et al., 2003) Local-Polynimial + K-NN residual bootstrap • Ensemble Streamflow forecasting Truckee-Carson basin, NV (Grantz et al., 2002, 2003) • Ensemble forecast from categorical probabilistic forecast Local Polynomial • Flood Frequency Analysis (Apipattanavis et al., 2003) • Salinity Modeling in the Upper Colorado Basin (Prairie et al., 2002, 2003)
Are multi-scale statistics preserved by the Daily Model ? Is a 2 State Markov Chain Adequate ? Can the lag-0 and lag-1 dependence across variables be easily preserved ?
Our current implementation uses moving window seasons Rajagopalan and Lall, 1999
mean wet spell length standard deviation of wet spell length longest wet spell length fraction of wet days
mean dry spell length standard deviation of dry spell length fraction of dry days longest dry spell length
Mean seasonal precipitation Variance of seasonal precipitation Annual Mean Annual Variance k-nn daily Simulations of Precipitation - Performance in terms of aggregated statistics
SRAD and TMX SRAD and TMN SRAD and DPT lag 0 cross correlation, for selected daily variables TMX and TMN TMX and DPT TMX and P TMN and P TMN and DPT DPT and P MAR-1 simulations SRAD and TMX SRAD and TMN SRAD and DPT k-nn simulations TMX and TMN TMX and DPT TMX and P TMN and P TMN and DPT DPT and P
Mean Annual Erosion in Kg/Sq. m. Impact of Improper Dependence Structure on Erosion Estimated from Physical Model (WEPP) using Simulated Weather Differences in CLIGEN/BOOTCLIM-scramble vs BOOTCLIM are due to inability vs ability to preserve cross-correlations between temperature and precipitation (and hence rain/snow) Luce et al., 2003
Region Figure 1. Map depicting the 21-state area of interest in this study. The numbers indicate stations grouped by region. The two dark filled squares in the east are Stations 114198 and 112140 in Region 4, and the two dark squares in the west are Stations 52281 and 52662 in Region 7. Map depicting the 21-state area of interest in this study. The numbers indicate stations grouped by region. The two dark filled squares in the east are Stations 114198 and 112140 in Region 4, and the two dark squares in the west are Stations 52281 and 52662 in Region 7. (Yates et al., 2003)
Downscaling Concept Horizontal resolution ~ 200 km • Purpose: Downscale global-scale atmospheric forecasts to local scales in river basins (e.g., individual stations). [scale mis-match] Area of interest ~500 to 2000 km2
Downscaling Approach • Identify outputs from the global-scale Numerical Weather Prediction (NWP) model that are related to precipitation and temperature in the basins of interest • Geo-potential height, wind, humidity at five pressure levels etc. • Various surface flux variables • Computed variables such as vorticity advection, stabilitiy indices, etc. • Variables lagged to account for temporal phase errors in atmospheric forecasts. • Use NWP outputs in a statistical model to estimate precipitation and temperature for the basins • Multiple linear regression • K-nn • NWS bias-correction methodology • Local polynomial regression • Canonical Correlation Analysis • Artificial Neural Networks
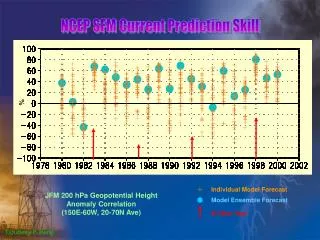
Multiple Linear Regression (MLR) Approach • Multiple linear Regression with forward selection Y = a0 + a1X1 + a2X2 + a3X3 . . . + anXn + e • Use cross-validation procedures for variable selection – typically less than 8 variables are selected for a given equation • A separate equation is developed for each station, each forecast lead time, and each month. • Stochastic modeling of the residuals in the regression equation is done to provide ensemble time series • The ensemble members are subsequently shuffled to reconstruct the observed spatio-temporal covariability • Regression coefficients are estimated from the period of the NCEP 1998 MRF hindcast (1979-2001)
Get all the NCEP MRF output variables within a 14 day window (7 days, lag+lead) centered on the current day • Perform EOF analysis of the climate variables and retain the first few leading Pcs, that capture most of the variance • ~6 Pcs capture about 90% of the variance • The PC space leading Pcs becomes the “feature vector” • Project the forecast climate variable of the current day on to the PC space – i.e. The “feature vector” • Select the “nearest” neighbor to the “feature vector” in the PC space – hence, a day from the historical record. (Yates, D., Gangopadhyay, S., Rajagopalan, B., and Strzepek, K., A technique for generating regional climate scenarios using a nearest neighbor bootstrap, submitted to Water Resources Research ) K-nn Approach - Methodology
Snowmelt Dominated Cle Elum Rainfall Dominated 526km2 East Fork of the Carson Snowmelt Dominated Animas 3626km2 Snowmelt Dominated Alapaha 922km2 1792km2 BASINS
1 1 1 2 2 2 3 3 3 4 4 4 5 5 5 6 6 6 7 7 7 8 8 8 9 9 9 10 10 10 11 11 11 12 12 12 13 13 13 14 14 14 The “Schaake Shuffle” method Stn 1 Stn 2 Stn 3
The “Schaake Shuffle” method (ranked ens. output) Stn 1 Stn 2 Stn 3 Ranked ensemble output for a given forecast day
The “Schaake Shuffle” method (ranked ens. output) (data from days selected from the historical record) Stn 1 Stn 2 Stn 3 Stn 1 Stn 2 Stn 3
The “Schaake Shuffle” method (ranked ens. output) (ranked historical obs) Stn 1 Stn 2 Stn 3 Stn 1 Stn 2 Stn 3 Data ranked separately for each station
The “Schaake Shuffle” method (ranked ens. output) (ranked historical obs) (re-shuffled output) Stn 1 Stn 2 Stn 3 Stn 1 Stn 2 Stn 3 Stn1 Stn2 Stn3
The “Schaake Shuffle” method (ranked ens. output) (ranked historical obs) (re-shuffled output) Stn 1 Stn 2 Stn 3 Stn 1 Stn 2 Stn 3 Stn1 Stn2 Stn3
The “Schaake Shuffle” method (ranked ens. output) (ranked historical obs) (re-shuffled output) Stn 1 Stn 2 Stn 3 Stn 1 Stn 2 Stn 3 Stn1 Stn2 Stn3
The “Schaake Shuffle” method (Clark et al., 2003) (“Observed” Ensemble) 5 4 4 5 4 3 6 7 10 9 9 8 5 6 (Downscaled Ensemble)