Download

1 / 35
350 likes | 437 Views
CH 5 The Primary Level of Protein Structure. HW 2, 3, 4, 6, 7. Amino Acids and Peptides. Bioimportance: Monomer units for proteins Participate in cellular functions such as nerve transmissions Biosynthesis of porphyrins, purines, pyrimidines, and urea.

E N D
CH 5 The Primary Level of Protein Structure HW 2, 3, 4, 6, 7
Amino Acids and Peptides • Bioimportance: • Monomer units for proteins • Participate in cellular functions such as nerve transmissions • Biosynthesis of porphyrins, purines, pyrimidines, and urea
While human proteins only contain L-amino acids, other organisms contain both D and L • 10 of the 20 amino acids commonly used are essential nutrients, which mean they must be in our diet, we can not synthesize them • There are over 300 naturally occurring amino acids, but only 20 are used to make proteins.
These 20 are listed in table 5.3 page 129, according to side chain properties • Friday, we will have a quiz on the names, 1 letter abbreviation, and 3 letter abbreviation • Next Monday, we will have a quiz on the name, structure, and pKa’s (Table 5.1) • While we only use 20, some of these can be altered in a peptide by adding or removing a functional group to increase diversity.
Chirality • All amino acids, except Gycine, have an alpha carbon that is chiral. • This is the source of all chirality in organisms • The absolute configuration of all the alpha carbons are L
Amino Acids properties • Amino Acids may have a positive, negative or zero net charge. • Most amino acids are in the zwitterionic state at physiologic pH • An amino acid can not exist as COOH/NH2 because any pH low enough to protonate the COO- group would as protonate the NH2
Some amino acids, histidine and arginine, are resonance hybrids, but they still only have a 1+ charge. • By altering the net charge via pH, we can create separation processes for amino acids, peptides, and proteins • The isoelectric species is the form of a molecule that has an equal number of positive and negative charges, thus it is neutral.
The isoelectric pH, also called pI, is the pH midway between the pKa values on either side of the isoelectric species • Examples:
This pI guides selection of separation conditions • The pKa of side chains varies slightly • Nonpolar effects- • Thus the pKa in peptides and proteins will depend on unique local environments • These changes in charge affect physical properties of amino acids, peptides, and proteins. • Functional groups of the side chains typically determine chemical properties
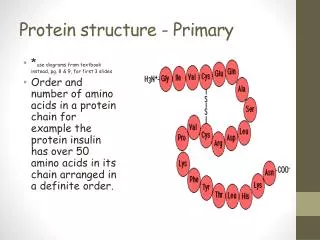
When amino acids are in a protein or peptide chain, they are called residues • Peptides are usually written with the free alpha amino group to the left and the free alpha carboxyl group to the right • The backbone will start with N, then the alpha carbon, then the carbonyl carbon, then repeat. • The side chains are bonded to the alpha carbon • Lines are used with 3-letter abbreviations, omitted with 1-letter abbreviations
For some peptides, non-common amino acids may be used or non-peptide bonds my be used • The peptide bond is not charged, however you still have a + at the N-terminal, - at the C-terminal, and any charges on side chains • Peptides are therefore classified as Polyelectrolytes
Structure Feature of Peptide Bond • See figure 5.12 page 138 • The peptide bond has some double bond character and does not have rotation about the C-N peptide bond • The carbonyl O and C, the N,and the H on the N, all lie in the same plane. • Rotation only occurs between the alpha carbon and N, and alpha carbon and COO-
Determination of Primary Structure • We know proteins are very important • An important goal of molecular medicine is the identification of proteins who presence, absence, or deficiency is associated with specific physiologic states or disease • The primary structure of proteins, which is the sequence of amino acids, provides both a molecular finger print for its identification and information that can be used to identify and clone the gene or genes that encode it.
In order to determine the amino acid sequence, a protein or peptide must be highly purified • Because of the 1000’s of different proteins in each cell, this is very difficult to do. • It usually requires many successive purification techniques
Purification • The classic approach exploits differences in: • Relative solubility of proteins as a function of pH • Polarity • Salt concentration • Chromatographic separtions
Chromatographic Separations • Mobile phase vs stationary phase • Paper chromatography • TLC • Column • Types of stationary phase • Size exclusion • Absorption • Ion exchange
Other types of Chromatography • pH based chromatography • Hydrophobic Interaction chromatography
Affinity Chromatography • Exploits high selectivity of binding proteins • This is what we did in lab • All the chromatography mentioned so far, is typically done slowly with low pressure • The stationary phases involved are somewhat “spongy” and their compressibility limit flow rates
HPLC • High Pressure Liquid Chromatography uses incompressible silica or alumina as stationary phase which allows much higher flow rates and pressures • This also helps limit diffusion thus enhances the resolution • This method is very effective on complex mixtures of lipids or peptides with very similar properties
HPLC • The stationary phase is typically hydrophobic and water miscible organic solvents such as acetonitrile or methanol are used as mobile phases
SDS-PAGE • SDS- sodium dodecyl sulfate (anion detergent) • PAGE- poly acrylamide gel electrophoresis • Electrophoresis separates biomolecules based on their ability to move through a gel matrix due to an applied electric field • SDS denatures and binds to proteins at a known ratio of 1 SDS for every 2 peptide bonds
2-mercaptoethanol or dithiothreitol is used to break disulfide linkages • The charge on SDS,-1, overcomes and negates charges on side chains • This leads to a constant charge to mass ratio which means the peptides are separated purely by the resistance the matrix provides • Larger peptides have more resistance, therefore move slower • The gel is then stained, usually with Coomassie Blue, to visualize the movement
IEF • IEF- Isoelectric Focusing • Ionic buffers called ampholytes and applied electric field are used to generate a pH gradient with in a matrix • The peptide/protein then migrate through the matrix to an area where the pH=pI, so there is no net charge on the peptide • IEF can be used in conjunction with SDS-PAGE to perform a 2-D analysis, separating peptides first by pI, then by size
Sequencing Peptides • Sanger was the first to determine the sequence of a polypeptide • Mature insulin consist of 2 chains, the A chain has 21 residues, the B chain has 30 residues • The chains are held together by disulfide linkages • Sanger first broke the linkages to separate the chains
He then broke the chains into smaller pieces using trypsin, chymotrypsin, and pepsin • These reagents cleave peptide bonds at known locations (see table 5.4 p 139) • These smaller fragments where the separated and hydrolyzed to form even smaller peptide chains • Each was reacted with 1-fluoro-2,4-dinitrobenzene, called Sanger’s reagent, which derivatizes the exposed alpha amino group
The amino acid content of the peptide was then determined. • Working backwards, he was able to determine the complete sequence of insulin and win the Nobel Prize in 1958
Peptide Cleaving Agents Reagent Bond Cleaved CNBr Met-X Trypsin Lys-X and Arg-X Chymotrypsin Hydrophobic AA-X Endoproteinase Lys-C Lys-X Endoproteinase Arg-C Arg-X Endoproteinase Asp-N X-Asp
Reagent Bond Cleaved V8 protease Glu-X particularly where X is hydrophobic Hydroxylamine Asn-Gly o-Iodosobenzene Trp-X Mild Acid Asp-Pro
Edman’s Reagent • Pehr Edman introduced phenylisothiocyanate, called Edman’s reagent, to selectivity label the amino-terminal residue of a peptide • Unlike Sanger’s, Edman’s derivative can be removed under mild conditions with out disrupting the rest of the peptide • After removal, a new amino terminal is produced and the process is repeated • This allows for the direct sequencing of a peptide
However, due to the efficiency of the reaction, this process is limited to peptides no larger than 20-30 residues • Process:
Because of the limitations to Edman’s process and since most polypeptides contain several hundred residues, most polypeptides must be broken into smaller chains which are then identified. • Sample problem on hand out.
Microbiology Impact • Advances in Microbiology have led to a new, simpler way to identify the primary structure of proteins. • Knowledge of the DNA sequence permits deductions of the sequence of AA • Sequencing DNA requires much less sample
So by sequencing only a small portion of protein, we can correlate it to DNA, find the section of DNA that encodes the protein, then deduce the whole sequence. • Limitation: No information is provided for post-translational modifications!