Download
1 / 1
10 likes | 179 Views
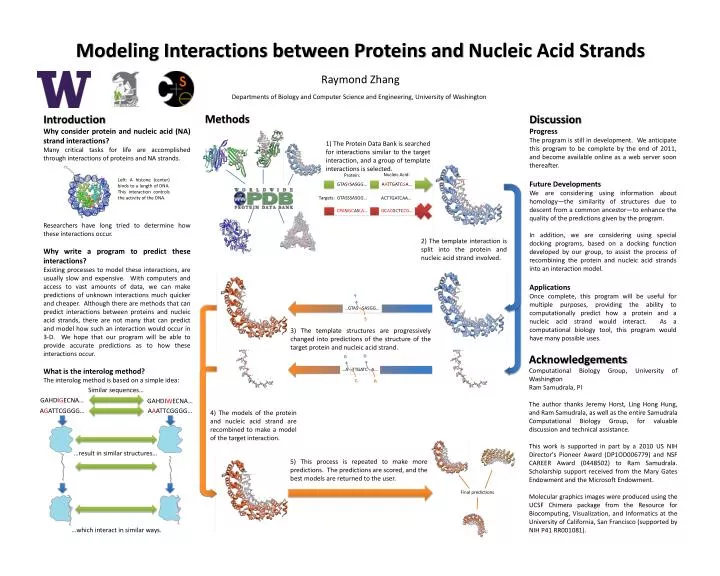
1) The Protein Data Bank is searched for interactions similar to the target interaction, and a group of template interactions is selected. Modeling Interactions between Proteins and Nucleic Acid Strands . Nucleic Acid:. Protein:. GTAS Y SASGG…. A A TTGATC G A…. Targets:. GTASSSASGG….

E N D
1) The Protein Data Bank is searched for interactions similar to the target interaction, and a group of template interactions is selected. Modeling Interactions between Proteins and Nucleic Acid Strands Nucleic Acid: Protein: GTASYSASGG… AATTGATCGA… Targets: GTASSSASGG… ACTTGATCAA… Raymond Zhang CPASIGCASLA… GCACGCTCCG… Departments of Biology and Computer Science and Engineering, University of Washington 2) The template interaction is split into the protein and nucleic acid strand involved. Methods Introduction Why consider protein and nucleic acid (NA) strand interactions? Many critical tasks for life are accomplished through interactions of proteins and NA strands. Researchers have long tried to determine how these interactions occur. Why write a program to predict these interactions? Existing processes to model these interactions, are usually slow and expensive. With computers and access to vast amounts of data, we can make predictions of unknown interactions much quicker and cheaper. Although there are methods that can predict interactions between proteins and nucleic acid strands, there are not many that can predict and model how such an interaction would occur in 3-D. We hope that our program will be able to provide accurate predictions as to how these interactions occur. What is the interolog method? The interolog method is based on a simple idea: Discussion Progress The program is still in development. We anticipate this program to be complete by the end of 2011, and become available online as a web server soon thereafter. Future Developments We are considering using information about homology—the similarity of structures due to descent from a common ancestor—toenhance the quality of the predictions given by the program. In addition, we are considering using special docking programs, based on a docking function developed by our group, to assist the process of recombining the protein and nucleic acid strands into an interaction model. Applications Once complete, this program will be useful for multiple purposes, providing the ability to computationally predict how a protein and a nucleic acid strand would interact. As a computational biology tool, this program would have many possible uses. Y S Left: A histone (center) binds to a length of DNA. This interaction controls the activity of the DNA. 3) The template structures are progressively changed into predictions of the structure of the target protein and nucleic acid strand. …GTAS SASGG… G A …A TTGATC A… C A 4) The models of the protein and nucleic acid strand are recombined to make a model of the target interaction. 5) This process is repeated to make more predictions. The predictions are scored, and the best models are returned to the user. Final predictions Acknowledgements Computational Biology Group, University of Washington Ram Samudrala, PI The author thanks Jeremy Horst, Ling Hong Hung, and Ram Samudrala, as well as the entire SamudralaComputational Biology Group, for valuable discussion and technical assistance. This work is supported in part by a 2010 US NIHDirector's Pioneer Award (DP1OD006779) and NSF CAREER Award (0448502) to Ram Samudrala. Scholarship support received from the Mary Gates Endowment and the Microsoft Endowment. Molecular graphics images were produced using the UCSF Chimera package from the Resource for Biocomputing, Visualization, and Informatics at the University of California, San Francisco (supported by NIH P41 RR001081). Similar sequences… GAHDIGECNA… GAHDIWECNA… AGATTCGGGG… AAATTCGGGG… …result in similar structures… …which interact in similar ways.