Download

1 / 24
260 likes | 939 Views
Tema 13. Inferencia estadística Principales conceptos. Muestreo. Distribución muestral de un estadístico. Principales distribuciones muestrales. Principales conceptos en inferencia estadística

E N D
Tema 13. Inferencia estadísticaPrincipales conceptos. Muestreo. Distribución muestral de un estadístico. Principales distribuciones muestrales.
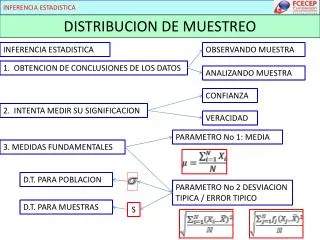
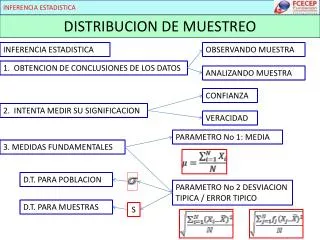
Principales conceptos en inferencia estadística Idea básica: Hacer inferencias sobre la población a partir de la muestra que hemos extraído de la misma. Ello nos lleva a tratar (brevemente) el tema del muestreo. Pensemos que la muestra habrá de ser representativa de la población, para que podamos efectuar inferencias que tengan sentido.
Muestreo Definición: Proceso que nos permite la extracción de una muestra a partir de una población • Hay dos tipos básicos de muestreo: • Muestreo probabilístico. En este tipo de muestreo, la probabilidad de aparición en una muestra de cualquier elemento de la población es conocida (o calculable). Es el único científicamente válido, y es sobre el que nos extenderemos especialmente. • Muestreo no probabilístico. Es aquel en el que la selección de los elementos de la muestra no se hacen al azar.
Muestreo probabilístico Este muestreo garantiza que, a la larga, las muestras que se van obteniendo de la población sean representativas de la misma. Vamos a ver varios tipos de muestreo probabilístico. • Muestreo aleatorio simple • Muestreo estratificado • Muestreo por conglomerados • Muestreo por etapas (o polietápico) • Muestreo sistemático (?)
Muestreo probabilístico 1. Muestreo aleatorio simple Es aquel en el que, a priori, todos los elementos de la muestra tienen la misma probabilidad de aparición. Supongamos que tengamos una población de 50.000 individuos, y que tenemos un listado con sus nombres. Si queremos elegir 100 personas, lo que necesitamos es que el ordenador elija al azar a 100 individuos de esos 50.000.
Muestreo probabilístico 2. Muestreo estratificado En el muestreo estratificado, los investigadores han de dividir a los sujetos en diferentes subpoblaciones (o estratos), en función de cierta característica relevante, y después lo que hacen es un muestro aleatorio simple de cada estrato. Evidentemente, cada individuo debe pertenecer a un estrato (y solo uno), y cada individuo del estrato habrá de tener la misma probabilidad de ser escogido como parte de la muestra. Ejemplo: Supongamos que, en Valencia, 70% de los niños de primaria van a escuela pública y el 30% a concertada. Si queremos 1,000 niños, lo que haremos es dividir los alumnos en 2 estratos (pública y concertada) y se eligen aleatoriamente 700 niños de la pública y aleatoriamente 300 de la concertada.
Muestreo probabilístico 3. Muestreo por conglomerados En el muestreo por conglomerados, en lugar de considerar cada elemento de la población, lo que consideramos son “conglomerados de elementos”. El proceso es elegir aleatoriamente uno o varios conglomerados y la muestra estará formada por TODOS los elementos de los conglomerados. Ejemplos: -En las encuestas durante las elecciones, los conglomerados pueden ser las mesas electorales, y lo que se hace es escoger algunas mesas al azar (y de ahí se toman todos los votos de las mesas seleccionadas). -En otros ejemplos, los conglomerados pueden ser los bloques de viviendas, los municipios, etc.
Muestreo probabilístico 4. Muestreo por etapas En este caso se combina el muestreo aleatorio simple con el muestreo por conglomerados: Primero se realiza un muestreo por conglomerados (v.g., si los conglomerados son colegios en Valencia, se seleccionan aleatoriamente varios de ellos). Segundo, no se eligen todos los alumnos (como ocurriría en un muestro por conglomerados), sino que se elige una muestra aleatoria. (Dicha muestra puede ser obtenida por muestreo aleatorio simple o puede ser estratificado.) Es decir, hemos tenido 2 etapas de muestreo. Y claro está, es posible tener más de 2 etapas...
Muestreo probabilístico 5. Muestreo aleatorio sistemático Supongamos que tengamos una lista de N elementos (e.g., estudiantes de secundaria) y queramos una muestra de tamaño “n”. En este caso, lo que se hace es ordenarlos (v.g., en función de los apellidos) y después se elige aleatoriamente un elemento entre los N/n=k primeros, y luego se elige de manera sistemática el que esté k lugares después del primer elemento, y así sucesivamente. Ejemplo: Tenemos 10000 estudiantes (en una lista) y queremos obtener una muestra de 100 estudiantes. Primero elegimos al azar un estudiante entre los 10000/100=100 primeros (supongamos que salga el 26), el segundo elemento será el estudiante 100+26 (126), el siguiente será el 226, luego el 326, etc.
Muestreo no probabilístico 1. Muestreo sin norma (o de conveniencia) Se elige a una muestra por ser conveniente, fácil, económica. Pero no se hace en base a un criterio de aleatoridad. Ejemplo: las encuestas en los periódicos electrónicos; el muestreo habitual en los trabajos en psicología. 2. Muestreo intencional En este caso, si bien el muestreo no es probabilístico, los investigadores procuran que se garantice la representatividad de la muestra
Distribución muestral de un estadístico Supongamos que tenemos una variable aleatoria, cuya distribución es f(x) Supongamos, por simplicidad, que obtenemos una muestra aleatoria simple con tamaño n X1, X2, ... Xn Entonces, un estadístico es cualquier función h definida sobre X1, X2, ... Xn y que no incluye parámetro desconocido alguno: Y=h(X1, X2, ... Xn) La distribución de dicho estadístico Y la vamos a denominar g(y)
Distribución muestral de un estadístico Observad: f(x) es la distribución de la v.a. bajo estudio g(y) es la distribución del estadístico que tenemos Es vital conocer la distribución muestral del estadístico de interés para poder efectuar inferencias sobre el parámetro correspondiente. Esto es, para efectuar inferencias sobre la media poblacional m, necesitamos conocer la distribución muestral de
Distribución muestral de la media Veremos primero el caso de que la distribución subyacente sea normal, con media y varianza La media de la distribución muestral de medias es La varianza de la distribución muestral de medias es La forma de la distribución muestral de la media es normal. Nota: La desviación típica de la distribución muestral suele ser denominada: error típico de tal estadístico (v.g., “error típico de la media”, etc.)
Distribución muestral de la media. Ejemplo 1 Distribución poblacional subyacente (dist. Normal): Media=100 (Varianza=225) Desv.Típica=15 La línea (en este y sucesivos ejemplos) es una curva normal Distribución muestral de la media: Tamaño muestral=10 Media=100 (Varianza=225/10=22.5) Desv.típica= En este y sucesivos gráficos: Número de réplicas
Distribución muestral de la media. Ejemplo 2 Distribución poblacional subyacente (dist. Normal): Media=100 Desv.Típica=15 Distribución muestral de la media: Tamaño muestral=20 Media=100 (Varianza=225/20=11.3) Desv.típica=3.35
Distribución muestral de la media. Ejemplo 3 Distribución poblacional subyacente (dist. Normal): Media=100 Desv.Típica=15 Distribución muestral de la media: Tamaño muestral=50 Media=100 (Varianza=225/50=4.5) Desv.típica=2.12
Distribución muestral de la media Veremos ahora el caso de que la distribución subyacente sea arbitraria, si bien sabemos que la media es y la varianza sea La media de la distribución muestral de medias es La varianza de la distribución muestral de medias es La forma de la distribución muestral de la media TAMBIÉN tiende a ser normal. En concreto, la distribución muestral se acercará más y más a la distribución normal (media m y varianza s2/n) a medida que se aumente el tamaño de cada muestra.
Distribución muestral de la media. Ejemplo 4 La distribución GAMMA tiene 2 parámetros: l que es un parámetro de escala (1) p que es un parámetro de forma (100) Distribución poblacional subyacente (dist. GAMMA): Media=100= Varianza=100=
Distribución muestral de la media. Ejemplo 4 Distribución poblacional subyacente (dist. GAMMA): Media=100 Varianza=100 Distribución muestral de la media: Tamaño muestral=10 Media=100 (Varianza=100/10=10) Desv.típica=
Distribución muestral de la media. Ejemplo 5 Distribución poblacional (dist. EXPONENCIAL): Media=0.1=1/l Varianza=0.01=1/l2 La distribución EXPONENCIAL tiene 1 parámetro: l (en el ejemplo: 10) Ejemplo de distr.exponencial en psicología: v.g., tiempo transcurrido entre 2 pulsaciones de una rata en una caja de Skinner.
Distribución muestral de la media. Ejemplo 5a Distribución poblacional (dist. EXPONENCIAL): Media=0.1=1/l Varianza=0.01=1/l2 Distribución muestral de la media: Tamaño muestral=10 Media=.100 (Varianza=0.01/10=.001) Desv.típica=.03 Observad que la dist. muestral se aproxima a la normal
Distribución muestral de la media. Ejemplo 5b Distribución poblacional (dist. EXPONENCIAL): Media=0.1=1/l Varianza=0.01=1/l2 Distribución muestral de la media: Tamaño muestral=20 Media=.100 (Varianza=0.01/20=.0005) Desv.típica=.022 Observad que la distribución muestral se aproxima más a la normal (al elevar el tamaño muestral).
OTRAS DISTRIBUCIONES MUESTRALES (1) Distribución muestral de Cuando la distribución de la que obtenemos las medias muestrales es gaussiana (“distr.normal”), la expresión anterior se distribuye según la distribución t de Student con tn-1 grados de libertad. (Esta distribución es básica para efectuar inferencias entre dos medias.) Distribución muestral de Asumiendo varianzas poblacionales iguales Cuando las distribuciones de la que obtenemos las varianzas muestrales son gaussianas, la expresión anterior se distribuye según la distribución F de Fisher con n1-1 grados de libertad en el numerador y n2-1 grados de libertad en el denominador. (Recordad que la distribución F es básica para la razón de varianzas: ANOVA.)
OTRAS DISTRIBUCIONES MUESTRALES (2) Distribución muestral de Cuando las distribución de la que obtenemos la varianza muestral es gaussiana, la anterior expresión se distribuye según la distribución chi-cuadrado con n-1 grados de libertad.