Download
1 / 17
210 likes | 407 Views
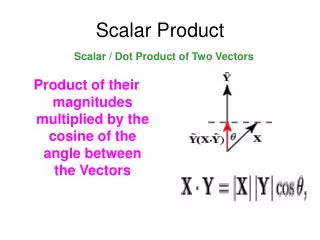
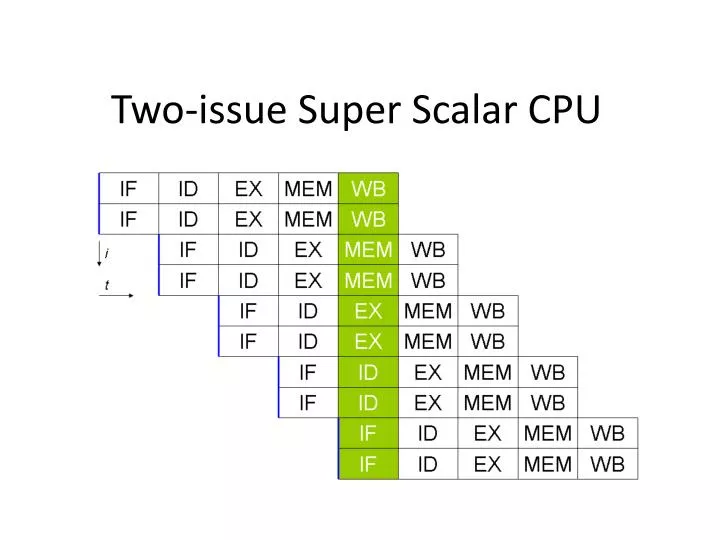
Two-issue Super Scalar CPU. CPU structure, what did we have to deal with: double clock generation double-port instruction cache double-port instruction fetch (bubble handling) decode stage (instr handling, scoreboard implemented)

E N D
CPU structure, what did we have to deal with: • double clock generation • double-port instruction cache • double-port instruction fetch (bubble handling) • decode stage (instr handling, scoreboard implemented) • execute stage (doubled execution unit, forwarding, branch resolving, write-back ports) • load-store stage (memory access handling, doubled write-back signal)
Top level model • Global 50MHz clock connected do DLL component which performs clock frequency doubling • Doubled clock needed to implement 4-port Block RAM IO interface chipset DLL CLK CLK0 CPU CLK2x performance counter
Instruction cache first port second port • Block RAM extension to two-port implementation • Cache miss and hit tests for two ports • One memory port • FSM responsible for memory access is switched between two requests from instruction fetch Block RAM FSM Memory Access
Instruction fetch two instruction cache ports • Fetching two instruction from cache • bubble insertion for each instruction stream • instructions passed to the output in order Instruction Fetch two decode stage ports branch request bubble1 bubble2
Decode stage two instruction fetch ports • Decoding two instructions • Quad-port Block RAM inferred • Taking advantage from doubled clock – double write-back handling • Scoreboard implemented – set of conditions for checking data dependencies • Bubble generation • Instruction stream prepared for load-store stage Scoreboard Previous Instr. Block RAM Instruction decoding Write-back two execute stage ports Write-back
Scoreboard Nr Instruction Idx_d Idx_a Idx_b Executability 1 MUL 2 0 1 1 - ST 1 2 0 2 In practice corresponds to Outputs of instructions fetch • Simplification of full scoreboard unit • Introduced as a set of conditions implemented in decode stage • Used for bubble insertion of both types (concurrent and consecutive instructions) and separating memory access instructions • Presented by abtract instruction table consisted of two lines
two instruction fetch ports Scoreboard Previous Instr. And few examples: Block RAM Firstly, normal operation without any bubble insertion, two instructions are fully independent Instruction decoding two execute stage ports Write-back Write-back
two instruction fetch ports Bubble insertion caused by data dependencies between concurrent instructions Scoreboard Previous Instr. Block RAM Instruction decoding two execute stage ports Write-back Write-back
Instr LD $0 Instr Instr $1,$0 Bubble insertion caused by data dependencies between load instruction and consecutive arbitrary instructions Scoreboard Previous Instr. Block RAM Instruction decoding two execute stage ports Write-back Write-back
ST ST LD Instr Bubble insertion introduced to split two memory-access instructions Scoreboard Previous Instr. Block RAM Instruction decoding two execute stage ports Write-back Write-back
Execute stage two decode stage ports branch request • Doubled ALU • Resolving of branch priority • Forwarding from both instruction streams • Write-back generation Data forwarding ALU ALU Register two load store stage ports
Load-store stage write back from execute • It is ensured that only one memory access instruction is passed to load store unit • Memory access process is switched to the right instruction • write back signals are generated write back multiplexing memory access memory ports write back signals
Performance (1) – blinking leds Instruction/cycle • Additional parameters: • Number of simulated cycles : 124988 • Execution Frequency of Memory Access Instructions compared with number of all instructions: - Super Sc : 0,29 - SIMD : 0,24 • ALU Instructions : - Super Sc : 0,14 - SIMD : 0,13 0,5 0,42 Super scalar SIMD SIMD
Performance (2) - apfel • Additional parameters: • Execution Frequency of Memory Access Instructions: - for both : 0,2 • ALU Instructions : - both : 0,4 • Measurement Results of Instruction Execution Frequency are surprising, probably because of many memory access instructions executed at the beginning of program (the longer the simulation time is, the better results we should get) Instruction/cycle 0,56 0,45 Super scalar SIMD SIMD
Synthesis • last version seen working on XCV300 was 2-way SIMD (MUCH faster than HaPra CPU!) • 4-way SIMD and Super Scalar versions are too big for XCV300... • ...and for unknown reasons don't work in XCV800 • probably severe timing issues - running on 25MHz instead of 50MHs doesn't help • (but 4-way SIMD should work anyway!) • all we've got is fully working simulation