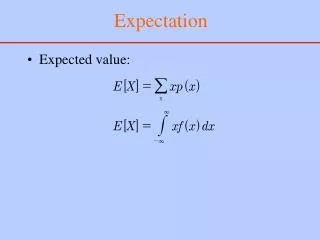Download

1 / 73
740 likes | 900 Views
Preconditioning in Expectation. Richard Peng. MIT. Joint with Michael Cohen (MIT), Rasmus Kyng (Yale), Jakub Pachocki (CMU), and Anup Rao (Yale). CMU theory seminar, April 5, 2014. Random Sampling. Collection of many objects Pick a small subset of them. Goals of Sampling.

E N D
Preconditioning in Expectation Richard Peng MIT Joint with Michael Cohen (MIT), RasmusKyng (Yale), JakubPachocki (CMU), and AnupRao (Yale) CMU theory seminar, April 5, 2014
Random Sampling • Collection of many objects • Pick a small subset of them
Goals of Sampling • Estimate quantities • Approximate higher dimensional objects • Use in algorithms
Sample to Approximate • ε- nets / cuttings • Sketches • Graphs • Gradients This talk: matrices
Numerical Linear Algebra • Linear system in n x n matrix • Inverse is dense • [Concus-Golub-O'Leary `76]: incomplete Cholesky, drop entries
How To Analyze? • Show sample is good • Concentration bounds • Scalar: [Bernstein `24][Chernoff`52] • Matrices: [AW`02][RV`07][Tropp `12]
This talk • Directly show algorithm using samples runs well • Better bounds • Simpler analysis
Outline • Random matrices • Iterative methods • Randomized preconditioning • Expected inverse moments
How To Drop Entries? • Entry based representation hard • Group entries together • Symmetric with positive entries adjacency matrix of a graph
Sample with Guarantees • Sample edges in graphs • Goal: preserve size of all cuts • [BK`96] graph sparsification • Generalization of expanders
Dropping Entries/edges • L: graph Laplacian • 0-1 x : |x|L2 = size of cut between 0s-and-1s Unit weight case: |x|L2 = Σuv (xu – xv)2 Matrix norm: |x|P2 = xTPx
Decomposing a Matrix u Σuv (xu – xv)2 P.S.D. multi-variate version of positive L = Σuv v • Sample based on positive representations • P = Σi Pi, with each Pi P.S.D • Graphs: one Pi per edge u v
Matrix Chernoff Bounds ≼ : Loewner’s partial ordering, A ≼B B – A positive semi definite P = Σi Pi, with each Pi P.S.D Can sample Q with O(nlognε-2) rescaled Piss.t.P≼ Q ≼ (1 +ε) P
Can we do better? • Yes, [BSS `12]: O(nε-2) is possible • Iterative, cubic time construction • [BDM `11]: extends to general matrices
Direct Application Find Qvery close toP Solve problem on Q Return answer For ε accuracy, need P≼ Q≼(1 +ε) P Size of Q depends inversely on ε ε-1 is best that we can hope for
Use inside iterative methods Find Qsomewhat similar to P Solve problem on P using Q as a guide • [AB `11]: crude samples give good answers • [LMP `12]: extensions to row sampling
Algorithmic View • Crude approximations are ok • But need to be efficient • Can we use [BSS `12]?
Speed up [BSS `12] • Expander graphs, and more • ‘i.i.d. sampling’ variant related to the Kadison-Singer problem
Motivation • One dimensional sampling: • moment estimation, • pseudorandom generators • Rarely need w.h.p. • Dimensions should be disjoint
Motivation • Randomized coordinate descent for electrical flows [KOSZ`13,LS`13] • ACDM from [LS `13] improves various numerical routines
Randomized coordinate descent • Related to stochastic optimization • Known analyses when Q= Pj • [KOSZ`13][LS`13] can be viewed as ways of changing bases
Our Result For numerical routines, random Q gives same performances as [BSS`12], in expectation
Implications • Similar bounds to ACDM from [LS `13] • Recursive Chebyshev iteration ([KMP`11]) runs faster • Laplacian solvers in ~ mlog1/2n time
Outline • Random matrices • Iterative methods • Randomized preconditioning • Expected inverse moments
Iterative Methods Find Qs.t.P≼ Q≼10 P Use Q as guide to solve problem on P • [Gauss, 1823] Gauss-Siedel iteration • [Jacobi, 1845] Jacobi Iteration • [Hestnes-Stiefel `52] conjugate gradient
[Richardson `1910] x(t + 1) = x(t) + (b – Px(t)) • Fixed point: b – Px(t) = 0 • Each step: one matrix-vector multiplication
Iterative Methods • Multiplication is easier than division, especially for matrices • Use verifier to solve problem
1D case Know: 1/2 ≤ p ≤ 1 1 ≤ 1/p ≤ 2 • 1 is a ‘good’ estimate • Bad when p is far from 1 • Estimate of error: 1 - p
Iterative Methods • 1 + (1 – p) = 2 – p is more accurate • Two terms of Taylor expansion • Can take more terms
Iterative Methods 1/p = 1 + (1 – p) + (1 – p)2 + (1 – p)3… Generalizes to matrix settings: P-1 = I + (I – P) + (I – P)2 + …
[Richardson `1910] x(0) = Ib X(1)= (I + (I – P))b x(2)= (I + (I – P) (I + (I – P)))b … x(t + 1) = b + (I – P) x(t) • Error of x(t) = (I – P)t b • Geometric decrease if P is close to I
Optimization view Residue: r(t) = x(t ) – P-1b Error: |r(t)|22 • Quadratic potential function • Goal: walk down to the bottom • Direction given by gradient
Descent Steps x(t) x(t+1) x(t) x(t+1) • Step may overshoot • Need smooth function
Measure of Smoothness x(t + 1) = b + (I – P) x(t) Note: b = PP-1b r(t + 1) = (I – P) r(t) |r(t + 1)|2 ≤|I – P|2 |x(t)|2
Measure of Smoothness • |I – P|2 :smoothness of |r(t)|22 • Distance between P and I • Related to eigenvalues of P 1 / 2 I ≼ P≼ I |I – P|2 ≤ 1/2
More general • Convex functions • Smoothness / strong convexity This talk: only quadratics
Outline • Random matrices • Iterative methods • Randomized preconditioning • Expected inverse moments
Ill Posed Problems • Smoothness of directions differ • Progress limited by steeper parts
Preconditioning P Q P • Solve similar problem Q • Transfer steps across
Preconditioned Richardson P Q • Optimal step down energy function of Q given by Q-1 • Equivalent to solving Q-1Px = Q-1b
Preconditioned Richardson x(t + 1) = b + (I – Q-1P) x(t) Residue: r(t + 1) = (I – Q-1P) r(t) |r(t + 1)|P = |(I– Q-1P)r(t)|P
Convergence P Q Improvements depend on |I– P1/2Q-1P1/2|2 • If P≼ Q≼10 P, error halves in O(1) iterations • How to find a good Q?
Matrix Chernoff P = ΣiPi Q = ΣisiPi s has small support • Take O(nlogn) (rescaled) Pis with probability ~ trace(PiP-1) • Matrix Chernoff ([AW`02],[RV`07]): w.h.p. P≼ Q≼ 2P Note: Σitrace(PiP-1) = n
Why These Probabilities? • trace(PiP-1): • Matrix ‘dot product’ • If P is diagonal • 1 for all i • Need all entries Overhead of concentration: union bound on dimensions
Is Chernoff necessary? • P: diagonal matrix • Missing one entry: unbounded approximation factor
Better Convergence? • [Kaczmarz `37]: random projections onto small subspaces can work • Better (expected) behavior than what matrix concentration gives!
How? Q1 P ≠ • Will still progress in good directions • Can have (finite) badness if they are orthogonal to goal
Quantify Degeneracies P D • Have some D≼P ‘for free’ • D = λmin (P)I (min eigenvalue) • D = tree when P is a graph • D = crude approximation/ rank certificate
Removing Degeneracies P D • ‘Padding’ to remove degeneracy • If D≼P and 0.5 P ≼ Q≼P, 0.5P≼ D + Q≼ 2P
Role of D P D • Implicit in proofs of matrix Chernoff, as well as [BSS`12] • Splitting of P in numerical analysis • D and P can be very different