Download
1 / 25
260 likes | 526 Views
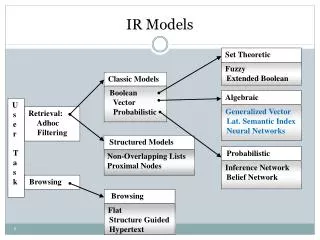
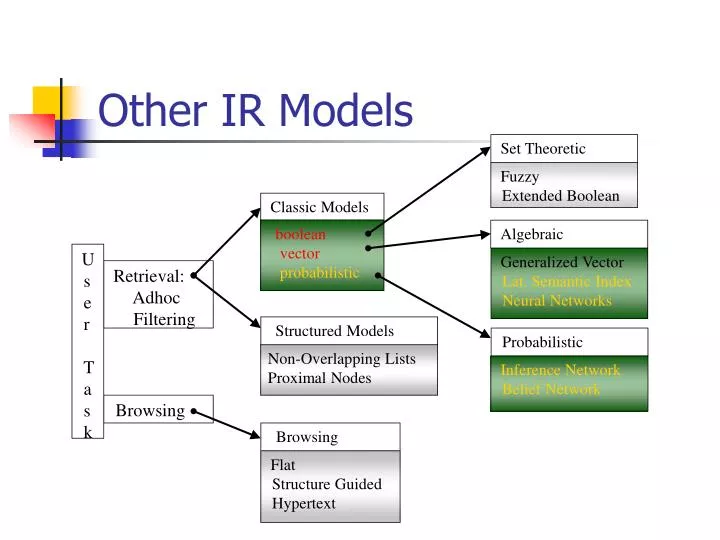
Set Theoretic. Structured Models. Fuzzy Extended Boolean. Non-Overlapping Lists Proximal Nodes. Browsing. Flat Structure Guided Hypertext. Other IR Models. Classic Models. boolean vector probabilistic. Algebraic. U s e r T a s k. Generalized Vector

E N D
Set Theoretic Structured Models Fuzzy Extended Boolean Non-Overlapping Lists Proximal Nodes Browsing Flat Structure Guided Hypertext Other IR Models Classic Models boolean vector probabilistic Algebraic U s e r T a s k Generalized Vector Lat. Semantic Index Neural Networks Retrieval: Adhoc Filtering Probabilistic Inference Network Belief Network Browsing
Another Vector Model: Motivation • Index terms have synonyms. [Use thesauri?] • Index terms have multiple meanings (polysemy). [Use restricted vocabularies or more precise queries?] • Index terms are not independent; think “phrases”. [Use combinations of terms?]
Latent Semantic Indexing/Analysis • Basic Idea: Keywords in a query are just one way of specifying the information need. One really wants to specify the key concepts rather than words. • Assume a latent semantic structure underlying the term-document data that is partially obscured by exact word choice.
LSI In Brief • Map from terms into lower dimensional space (via SVD) to remove “noise” and force clustering of similar words. • Pre-process corpus to create reduced vector space • Match queries to docs in reduced space
SVD for Term-Doc Matrix Docs = Terms m x m m x d t x d t x m C = where m is the rank of X (<=min(t,d)), T is orthonornal matrix of eigenvectors for term-term correlation, D is orthonornal matrix of eigenvectors from transpose of doc-doc correlation
Reducing Dimensionality • Order singular values in S0 by size, keep the k largest, and delete other rows/columns in S0, T0 and D0 to form • Approximate model is the rank-k model with best possible least-squares-fit to X. • Pick k large enough to fit structure, but small enough to eliminate noise – usually ~100-300.
Computing Similarities in LSI • How similar are 2 terms? • dot product between two row vectors of • How similar are two documents? • dot product between two column vectors of • How similar are a term and a document? • value of an individual cell
Query Retrieval • As before, treat query as short document: make it column 0 of C • First row of C provides rank of docs wrt query.
LSI Issues • Requires access to corpus to compute SVD • How to efficiently compute for Web? • What is the right value of k ? • Can LSI be used for cross-language retrieval? • Size of corpus is limited: “one student’s reading through high school” (Landauer 2002).
Other Vector Model: Neural Network • Basic idea: • 3 layer neural net: query terms, document terms, documents • Signal propagation based on classic similarity computation • Tune weights.
Query Terms DocumentTerms Documents k1 d1 ka ka dj kb kb dj+1 kc kc dN kt Neural Network Diagram from Wilkinson and Hingston, SIGIR 1991
Computing Document Rank • Weight from query to document term • Wiq = wiq sqrt ( i wiq ) • Weight from document term to document • Wij = wij sqrt ( i wij )
Probabilistic Models Principle: Given a user query q and a document d in the collection, estimate the probability that the user will find d relevant. (How?) • User rates a retrieved subset. • System uses rating to refine the subset. • Over time, retrieved subset should converge on relevant set.
Computing Similarity I probability that document dj is relevant to query q, probability that dj is non-relevant to the query q, probability of randomly selecting dj from set R probability that a randomly selected document is relevant
Computing Similarity II probability that index term ki is present in document randomly selected from R, Assumes independence of index terms
Initializing Probabilities • assume constant probabilities for index terms: • assume distribution of index terms in non-relevant documents matches overall distribution:
Improving Probabilities Assumptions: • approximate probability given relevant as % docs with index i retrieved so far: • approximate probabilities given non-relevant by assuming not retrieved are non-relevant:
Classic Probabilistic Model Summary • Pros: • ranking based on assessed probability • can be approximated without user intervention • Cons: • really need user to determine set V • ignores term frequency • assumes independence of terms
Probabilistic Alternative: Bayesian (Belief) Networks A graphical structure to represent the dependence between variables in which the following holds: • a set of random variables for the nodes • a set of directed links • a conditional probability table for each node, indicating relationship with parents • a directed acyclic graph
Earthquake Burglary Alarm JohnCalls Mary Calls Belief Network Example from Russell & Norvig
Earthquake Burglary Alarm JohnCalls Mary Calls Belief Network Example (cont.) Probability of false notification: alarm sounded and both people call, but there was no burglary or earthquake
Inference Networks for IR Random variables are associated with documents, index terms and queries. Edges from document node to term nodes increases belief in terms.
Computing rank in Inference Networks for IR • q is keyword query. q1 is Boolean query. I is information need. • Rank of document is computed as P(q^dj)
Where do probabilities come from? (Boolean Model) • uniform priors on documents • only terms in the document are active • query is matched to keywords ala Boolean model
Belief Network Formulation • different network topology • does not consider each document individually • adopts set theoretic view