Download

1 / 43
690 likes | 1.36k Views
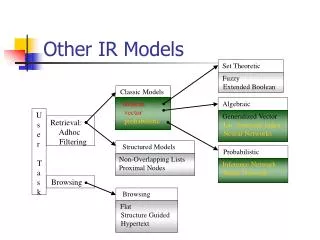
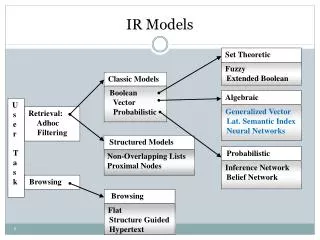
Classic IR Models. Boolean model simple model based on set theory queries as Boolean expressions adopted by many commercial systems Vector space model queries and documents as vectors in an M -dimensional space M is the number of terms

E N D
Classic IR Models • Boolean model • simple model based on set theory • queries as Boolean expressions • adopted by many commercial systems • Vector space model • queries and documents as vectors in an M-dimensional space • M is the number of terms • find documents most similar to the query in the M-dimensional space • Probabilistic model • a probabilistic approach • assume an ideal answer set for each query • iteratively refine the properties of the ideal answer set Information Retrieval Models
Document Index Terms • Each document is represented by a set of representative index terms or keywords • requires text pre-processing (off-line) • these terms summarize document contents • adjectives, adverbs, connectives are less useful • the index terms are mainly nouns (lexicon look-up) • Not all terms are equally useful • very frequent terms are not useful • very infrequent terms are not useful neither • terms have varying relevance (weights) when used to describe documents Information Retrieval Models
Text Preprocessing • Extract terms from documents and queries • document - query profile • Processing stages • word separation • sentence splitting • change terms to a standard form (e.g., lowercase) • eliminate stop-words (e.g. and, is, the, …) • reduce terms to their base form (e.g., eliminate prefixes, suffixes) • construct term indices (usually inverted files) Information Retrieval Models
Text Preprocessing Chart from Baeza – Yates & Ribeiro – Neto, 1999 Information Retrieval Models
documents index posting list 1 άγαλμα αγάπη … δουλειά … πρωί … ωκεανός 2 (1,2)(3,4) 3 4 (4,3)(7,5) 5 6 ……… 7 8 9 (10,3) 10 11 Inverted Index Information Retrieval Models
Basic Notation • Document: usually text • D: document collection (corpus) • d: an instance of D • Query: same representation with documents • Q: set of all possible queries • q: an instance of Q • Relevance: R(d,q) • binary relation R: D x Q {0,1} • d is “relevant” to qiffR(d,q) = 1or • degree of relevance: R(d,q) [0,1] or • probability of relevance R(d,q) = Prob(R|d,q) Information Retrieval Models
Term Weights • T = {t1, t2, ….tM } the terms in corpus • N number of documents in corpus • dj a document • djis represented by (w1j,w2j,…wMj)where • wij > 0 if ti appears in dj • wij= 0 otherwise • q is represented by (q1,q2,…qM) • R(d,q) > 0 ifq and d have common terms Information Retrieval Models
docs terms d1 d2 …. dN t1 w11 w12 w1N t2 w2i tM wM1 wMN Term Weighting Information Retrieval Models
D q query relevant document non-relevant document Document Space(corpus) Information Retrieval Models
Boolean Model • Based on set theory and Boolean algebra • Boolean queries: “John”and“Mary”not“Ann” • terms linked by “and”, “or”, “not” • terms weights are 0or 1(wij=0 or 1) • query terms are present or absent in a document • a document is relevant if the query condition is satisfied • Pros: simple, in many commercial systems • Cons: no ranking, not easy for complex queries Information Retrieval Models
Query Processing • For each term ti in query q={t1,t2,…tM} • use the index to retrieve all dj with wij> 0 • sort them by decreasing order (e.g., by term frequency) • Return documents satisfying the query condition • Slow for many terms: involves set intersections • Keep only the top K documents for each term at step 2 or • Do not process all query terms Information Retrieval Models
Vector Space Model • Documents and queries are M – dimensional term vectors • non-binary weights to index terms • a query is similar to a document if their vectors are similar • retrieved documents are sorted by decreasing order • a document may match a query only partially • SMARTis the most popular implementation Information Retrieval Models
q d θ Query – Document Similarity • Similarity is defined as the cosine of the angle between document and query vectors Information Retrieval Models
Weighting Scheme • tf x idf weighting scheme • wij: weight of term tiassociated with document dj • tfij frequency of term ti in document dj • max frequencytfli is computed over all terms in dj • tfij: normalized frequency • idfi: inverse document frequency • ni: number of documents where term ti occurs Information Retrieval Models
Weight Normalization • Many ways to express weights • E.g., using log(tfij) • The weight is normalized in [0,1] • Normalize by document length Information Retrieval Models
Normalization by Document Length • The longer the document, the more likely it is for a given term to appear in it • Normalize the term weights by document length (so longer documents are not given more weight) Information Retrieval Models
Comments on Term Weighting • tfij: term frequency – measures how well a term describes a document • intra documentcharacterization • idfi: terms appearing in many documents are not very useful in distinguishing relevant from non-relevant documents • inter documentcharacterization • This schemefavors averageterms Information Retrieval Models
Comments on Vector Space Model • Pros: • at least as good as other models • approximate query matching: a query and a document need not contain exactly the same terms • allows for ranking of results • Cons: • assumes term independency Information Retrieval Models
Document Distance • Consider documents d1, d2 with vectors u1, u2 • theirdistance is defined as the length AB Information Retrieval Models
Probabilistic Model • Computes the probability that the document is relevant to the query • ranks the documents according to their probability of being relevant to the query • Assumption: there is a set R of relevant documents which maximizes the overall probability of relevance • R: ideal answer set • R is not known in advance • initially assume a description (the terms) of R • iteratively refine this description Information Retrieval Models
Basic Notation • D: corpus, d: an instance of D • Q: set of queries, q: an instance of Q • P(R | d):probability that d is relevant • : probability that d is not relevant Information Retrieval Models
Probability of Relevance • P(R|d): probability that d is relevant • Bayes rule • P(d|R): probability of selecting d from R • P(R): probability of selecting R from D • P(d): probability of selecting d from D Information Retrieval Models
Document Ranking • Take the odds of relevance as the rank • Minimizes probability of erroneous judgment • are the same for all docs Information Retrieval Models
Ranking (cont’d) • Each document is represented by a set of index terms t1,t2,..tM • assume binary terms wi for terms ti • d=(w1,w2,…wM) where • wi=1 if the term appears in d • wi=0 otherwise • Assuming independence of index terms Information Retrieval Models
Ranking (conted) • By taking logarithms and by omitting constant terms • R is initially unknown Information Retrieval Models
Initial Estimation • Make simplifying assumptions such as • where ni: number of documents containing ti and N: total number of documents • Retrieve initial answer set using these values • Refine answer iteratively Information Retrieval Models
Improvement • Let V the number of documents retrieved initially • Take the fist r answers as relevant • From them compute Vi: number of documents containing ti • Update the initial probabilities: • Resubmit query and repeat until convergence Information Retrieval Models
Comments on Probabilistic Model • Pros: • good theoretical basis • Cons: • need to guess initial probabilities • binary weights • independence assumption • Extensions: • relevance feedback: humans choose relevant docs • OKAPI formula for non – binary weights Information Retrieval Models
Comparison of Models • The Boolean model is simple and used used almost everywhere. It does not allow for partial matches. It is the weakest model • The Vector space model has been shown (Salton and Buckley) to outperform the other two models • Various extensions deal with their weaknesses Information Retrieval Models
Query Modification • The results are not always satisfactory • some answers are correct, others are not • queries can’t specify user’s needs precisely • Iteratively reformulate and resubmit the query until the results become satisfactory • Two approaches • relevance feedback • query expansion Information Retrieval Models
Relevance Feedback • Mark answers as • relevant: positive examples • irrelevant: negative examples • Query: a point in document space • at each iteration compute new query point • the query moves towards an “optimal point” that distinguishes relevant from non-relevant document • the weights of query terms are modified • “term reweighting” Information Retrieval Models
Rochio Vectors q0 q1 optimal query q2 Information Retrieval Models
Rochio Formula • Query point • di: relevant answer • dj: non-relevant answer • n1: number of relevant answers • n2: number or non-relevant answers • α, β, γ: relative strength (usually α=β=γ=1) • α = 1, β = 0.75, γ = 0.25: q0 and relevant answers contain important information Information Retrieval Models
Query Expansion • Adds new terms to the query which are somehow related to existing terms • synonyms from dictionary (e.g., staff, crew) • semantically related terms from a thesaurus (e.g., “wordnet”): man, woman, man kind, human…) • terms with similar pronunciation (Phonix, Soundex) • Better results in many cases but query defocuses (topic drift) Information Retrieval Models
Comments • Do all together • query expansion: new terms are added from relevant documents, dictionaries, thesaurus • term reweighing by Rochio formula • If consistent relevance judgments are provided • 2-3 iterations improve results • quality depends on corpus Information Retrieval Models
Extensions • Pseudo relevance feedback: mark top k answers as relevant, bottom k answers as non-relevant and apply Rochio formula • Relevance models for probabilistic model • evaluation of initial answers by humans • term reweighting model by Bruce Croft, 1983 Information Retrieval Models
Text Clustering • The grouping of similar vectors into clusters • Similar documents tend to be relevant to the same requests • Clustering on M-dimensional space • M number of terms Information Retrieval Models
Clustering Methods • Sound methods based on the document-to-document similarity matrix • graph theoretic methods • O(N2) time • Iterative methods operating directly on the document vectors • O(NlogN) or O(N2/logN) time Information Retrieval Models
Sound Methods • Two documents with similarity > T(threshold) are connected with an edge [Duda&Hart73] • clusters: the connected components (maximal cliques) of the resulting graph • problem: selection of appropriate threshold T Information Retrieval Models
Zahn’s method [Zahn71] the dashed edge is inconsistent and is deleted • Find the minimum spanning tree • For each doc delete edges with length l > lavg • lavg: average distance if its incident edges • Or remove the longest edge (1 edge removed => 2 clusters, 2 edges removed => 3 clusters • Clusters: the connected components of the graph Information Retrieval Models
Iterative Methods • K-means clustering (K known in advance) • Choose some seed points (documents) • possible cluster centroids • Repeat until the centroids do not change • assign each vector (document) to its closest seed • compute new centroids • reassign vectors to improve clusters Information Retrieval Models
Cluster Searching • The M-dimensional query vector is compared with the cluster-centroids • search closest cluster • retrieve documents with similarity > T Information Retrieval Models
References • "Modern Information Retrieval", Richardo Baeza-Yates, Addison Wesley 1999 • "Searching Multimedia Databases by Content", Christos Faloutsos, Kluwer Academic Publishers, 1996 • Information Retrieval Resources http://nlp.stanford.edu/IR-book/information-retrieval.html • TREC http://trec.nist.gov/ • SMART http://en.wikipedia.org/wiki/SMART_ Information_Retrieval_System • LEMOUR http://www.lemurproject.org/ • LUCENE http://lucene.apache.org/ Information Retrieval Models