Download
1 / 18
180 likes | 372 Views
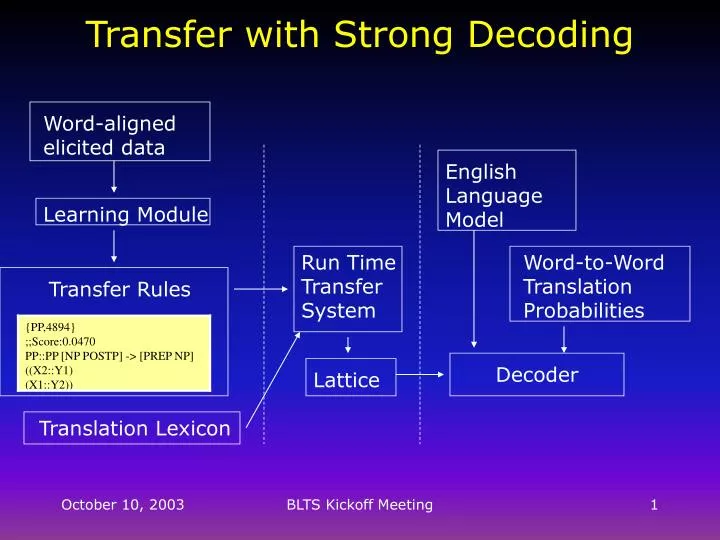
Word-aligned elicited data. English Language Model. Learning Module. Run Time Transfer System. Word-to-Word Translation Probabilities. Transfer Rules. {PP,4894} ;;Score:0.0470 PP::PP [NP POSTP] -> [PREP NP] ((X2::Y1) (X1::Y2)). Decoder. Lattice. Translation Lexicon.

E N D
Word-aligned elicited data English Language Model Learning Module Run Time Transfer System Word-to-Word Translation Probabilities Transfer Rules {PP,4894};;Score:0.0470PP::PP [NP POSTP] -> [PREP NP]((X2::Y1)(X1::Y2)) Decoder Lattice Translation Lexicon Transfer with Strong Decoding BLTS Kickoff Meeting
Type information Part-of-speech/constituent information Alignments x-side constraints y-side constraints xy-constraints, e.g. ((Y1 AGR) = (X1 AGR)) Transfer Rule Formalism ;SL: the man, TL: der Mann NP::NP [DET N] -> [DET N] ( (X1::Y1) (X2::Y2) ((X1 AGR) = *3-SING) ((X1 DEF = *DEF) ((X2 AGR) = *3-SING) ((X2 COUNT) = +) ((Y1 AGR) = *3-SING) ((Y1 DEF) = *DEF) ((Y2 AGR) = *3-SING) ((Y2 GENDER) = (Y1 GENDER)) ) BLTS Kickoff Meeting
Rule Learning - Overview • Goal: Acquire Syntactic Transfer Rules • Use available knowledge from the source side (grammatical structure) • Three steps: • Flat Seed Generation: first guesses at transfer rules; flat syntactic structure • Compositionality:use previously learned rules to add hierarchical structure • Seeded Version Space Learning: refine rules by learning appropriate feature constraints BLTS Kickoff Meeting
Flat Seed Rule Generation BLTS Kickoff Meeting
Compositionality BLTS Kickoff Meeting
Version Space Learning BLTS Kickoff Meeting
Examples of Learned Rules BLTS Kickoff Meeting
Manual Transfer Rules: Example ;; PASSIVE OF SIMPLE PAST (NO AUX) WITH LIGHT VERB ;; passive of 43 (7b) {VP,28} VP::VP : [V V V] -> [Aux V] ( (X1::Y2) ((x1 form) = root) ((x2 type) =c light) ((x2 form) = part) ((x2 aspect) = perf) ((x3 lexwx) = 'jAnA') ((x3 form) = part) ((x3 aspect) = perf) (x0 = x1) ((y1 lex) = be) ((y1 tense) = past) ((y1 agr num) = (x3 agr num)) ((y1 agr pers) = (x3 agr pers)) ((y2 form) = part) ) BLTS Kickoff Meeting
Manual Transfer Rules: Example NP PP NP1 NP P Adj N N1 ke eka aXyAya N jIvana NP NP1 PP Adj N P NP one chapter of N1 N life ; NP1 ke NP2 -> NP2 of NP1 ; Ex: jIvana ke eka aXyAya ; life of (one) chapter ; ==> a chapter of life ; {NP,12} NP::NP : [PP NP1] -> [NP1 PP] ( (X1::Y2) (X2::Y1) ; ((x2 lexwx) = 'kA') ) {NP,13} NP::NP : [NP1] -> [NP1] ( (X1::Y1) ) {PP,12} PP::PP : [NP Postp] -> [Prep NP] ( (X1::Y2) (X2::Y1) ) BLTS Kickoff Meeting
Future Directions • Continued work on automatic rule learning (especially Seeded Version Space Learning) • Improved leveraging from manual grammar resources, interaction with bilingual speakers • Developing a well-founded model for assigning scores (probabilities) to transfer rules • Improving the strong decoder to better fit the specific characteristics of the XFER model • MEMT with improved • Combination of output from different translation engines with different scorings • strong decoding capabilities BLTS Kickoff Meeting
A Limited Data Scenario for Hindi-to-English • Put together a scenario with “miserly” data resources: • Elicited Data corpus: 17589 phrases • Cleaned portion (top 12%) of LDC dictionary: ~2725 Hindi words (23612 translation pairs) • Manually acquired resources during the SLE: • 500 manual bigram translations • 72 manually written phrase transfer rules • 105 manually written postposition rules • 48 manually written time expression rules • No additional parallel text!! BLTS Kickoff Meeting
Testing Conditions • Tested on section of JHU provided data: 258 sentences with four reference translations • SMT system (stand-alone) • EBMT system (stand-alone) • XFER system (naïve decoding) • XFER system with “strong” decoder • No grammar rules (baseline) • Manually developed grammar rules • Automatically learned grammar rules • XFER+SMT with strong decoder (MEMT) BLTS Kickoff Meeting
Results on JHU Test Set (very miserly training data) BLTS Kickoff Meeting
Effect of Reordering in the Decoder BLTS Kickoff Meeting
Observations and Lessons (I) • XFER with strong decoder outperformed SMT even without any grammar rules in the miserly data scenario • SMT Trained on elicited phrases that are very short • SMT has insufficient data to train more discriminative translation probabilities • XFER takes advantage of Morphology • Token coverage without morphology: 0.6989 • Token coverage with morphology: 0.7892 • Manual grammar currently somewhat better than automatically learned grammar • Learned rules did not yet use version-space learning • Large room for improvement on learning rules • Importance of effective well-founded scoring of learned rules BLTS Kickoff Meeting
Observations and Lessons (II) • MEMT (XFER and SMT) based on strong decoder produced best results in the miserly scenario. • Reordering within the decoder provided very significant score improvements • Much room for more sophisticated grammar rules • Strong decoder can carry some of the reordering “burden” BLTS Kickoff Meeting
Conclusions • Transfer rules (both manual and learned) offer significant contributions that can complement existing data-driven approaches • Also in medium and large data settings? • Initial steps to development of a statistically grounded transfer-based MT system with: • Rules that are scored based on a well-founded probability model • Strong and effective decoding that incorporates the most advanced techniques used in SMT decoding • Working from the “opposite” end of research on incorporating models of syntax into “standard” SMT systems [Knight et al] • Our direction makes sense in the limited data scenario BLTS Kickoff Meeting
The Transfer Engine BLTS Kickoff Meeting




















