Download

1 / 38
380 likes | 482 Views
Performance. Performance what is it: measures of performance The CPU Performance Equation: Execution time as the measure what affects execution time examples Choosing good benchmarks? choosing bad benchmarks? Amdahl's Law. Performance is Time. Time to do the task (Execution Time)

E N D
Performance • Performance • what is it: measures of performance • The CPU Performance Equation: • Execution time as the measure • what affects execution time • examples • Choosing good benchmarks? • choosing bad benchmarks? • Amdahl's Law
Performance is Time • Time to do the task (Execution Time) • execution time, response time, latency • Tasks per unit time (sec, minute, ...) • throughput, bandwidth
Performance as Response Time • Performance is most often measured as response time or execution time for some task. • “X is n times faster than Y” means Performance(X) Execution Time(Y) –––––––––––––– = –––––––––––––––– = n Performance(Y) Execution Time(X) • Example Execution time of program P X is 5 sec; Y is 10 sec. • X is 2 times faster than Y.
What time to measure? • Elapsed time, wall-clock time: • actual time from start to completion • depends on CPU, system, I/O, etc. • often used in real benchmarks • only suitable choice when I/O is included • CPU Time: • measure/analyze CPU performance only • may be suitable when machine is timeshared • possibly both user and system component • User CPU time is our focus for first part of course • Elapsed time = CPU time + Idle time • usually and assuming time is accurately accounted for
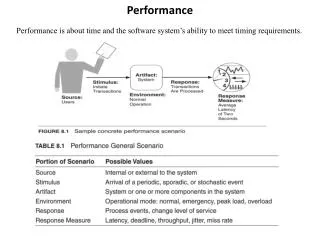
Application Programming Language Compiler Metrics ofperformance • Different performance metrics are appropriate at different levels: Frames per second Operations per second (millions) of Instructions per second – MIPS (millions) of (F.P.) operations per second – MFLOP/s ISA Cycles per second (clock rate) Cycles per Instruction Datapath Control Function Units Transistors
Relating Processor Metrics • CPU execution time per program = CPU clock cycles/program X Clock cycle time = CPU clock cycles/program ÷ Clock rate (frequency) • CPU clock cycles/program = Instructions/program X Clock cycles Per Instruction • Clock cycles Per Instruction (CPI) is an average measurement, it depends on : • ISA, the implementation, and the program measured • CPI = CPU clock cycles/program ÷ Instructions/program • Also, Instructions per clock cycle or IPC = 1 / CPI • CPU execution time = Instructions X CPI X Clock cycle
Static timing analysis • Memories 10 ns • Register 5 ns • Adders 10 ns • ALU 10 ns • Use topological sort!
Zeroext. 35 ns delay 5 ns 10 ns Branch logic 0 A 10 ns ALU 4 B + 31 + 10 ns Sgn/Ze extend lw $2 const($3) 10 ns 10 ns
But that path goes through the data memory! • What if this is not a load/store? • How about an instruction that does nothing? “NOP”
Zeroext. 10 ns delay 5 ns 10 ns Branch logic 0 A 10 ns ALU 4 B + 31 + 10 ns Sgn/Ze extend Nop 10 ns 10 ns
Zeroext. 25 ns delay 5 ns 10 ns Branch logic 0 A 10 ns ALU 4 B + 31 + 10 ns Sgn/Ze extend Add $ra $rb $rc 10 ns 10 ns
Zeroext. 20 ns delay 5 ns 10 ns Branch logic 0 A 10 ns ALU 4 B + 31 + 10 ns Sgn/Ze extend B label 10 ns 10 ns
35 ns for load/store but 10 ns for NOP !?
Amdahl’s Law: “Make the common case fast”
Amdahl's Law • Handy for evaluating impact of a change not tied to CPU performance equation • Insight: No improvement of a feature enhances performance by more than the use of the feature. • Suppose that enhancement E accelerates fraction F of a program by a factor S (remainder of the task is unaffected): • ExecTimeE = (1 – F(1 – 1/S)) X ExecTimewithout E F 1-F F/S 1-F S =
What if we don’t need the ALU? A branch instruction?
BUT! • The single cycle model has to accomodate the slowest instruction • Even if it rarely occurs!
How much work can our structure perform? • For a program Q: • Time = Number of executed instruction * Number of cycles per instruction * Time per cycle • T = Nq * CPI * Tc
For the single cycle model.... • CPI = 1 for all instructions • Tc determined by the slowest instruction
How to reduce T? • T = Nq * CPI * Tc Reduce Nq. More powerful instructions! More hardware, longer paths, cycle time goes up (slower machine)
“No free lunch” Why designers are so well paid - to optimize designs.
How to reduce T? • T = Nq * CPI * Tc Faster hardware Technological limits Cost increase not linearly related Sales volume drops
How to reduce T? • T = Nq * CPI * Tc Make this a function of the instruction For example: NOP = 1 cycle LW = 4 cycles Chapter 5.4, the classical method
How to reduce T? • T = Nq * CPI * Tc Make this a function of the instruction CPI goes up, but we can use an average, not the worst case Tc goes down, time to do the longes step, not the entire instruction
Example • Branch: Step 1: fetch Step 2: New PC • Add: Step 1: fetch Step 2: decode/ register fetch Step 3: Compute and write back
Example • LW = 4 steps • Cycletime = 1/4 old time • T = 4 * 1/4 old time, LW CPI • just as slow for the lw instruction our worst case!
But that’s not important if LW is not common! T = Nq * CPI * 1/4 old time Averaged over this many instructions 1,3? 1,7? Never = 4,0!
We win because of quantitative statisticalproperties of our programs!
What value of CPI do we use? 1,3? 1,5? 1,7? Easy: Use average program! ?
Artificial “average programs” called “benchmarks” Are they something to trust? What about “peak performance values” mips? mflops? We have a peak at CPI = 1.... ...a program of only NO-OPS!
Why Do Benchmarks? • How we evaluate performance differences • Across and within a single system (design & variations) • What should benchmarks do? • Represent a large class of important programs • Behave like typical programs: • improved benchmark performance => improved performance broadly • For better or worse, benchmarks shape a field • Good ones accelerate progress • Bad benchmarks hurt progress • help real programs vs. sell machines/papers? • Enhancements that help benchmarks may not help most programs and v.v.
Classes of Benchmarks • (Toy) Benchmarks • 10-100 line–e.g.,: sieve, puzzle, quicksort • good first programming assignments • Synthetic Benchmarks • attempt to match average frequencies of real workloads • e.g., Whetstone, dhrystone • mostly good for nothing: too artificial • Kernels • Time critical excerpts of real programs • e.g., Livermore loops, Linpack • good for micro-performance studies • Real programs • e.g., gcc, spice, Verilog, Database, stock trading
Successful Benchmark: SPEC Collection • 1987 RISC industry (workstations) mired in “bench marketing”: • (“That is an 8 MIPS machine, but they claim 10 MIPS!”) • EE Times + 5 companies band together to perform Systems Performance Evaluation Committee (SPEC) in 1988: • Sun, MIPS, HP, Apollo, DEC • Create standard list of programs, inputs, reporting rules: • several real programs, including OS calls • some I/O • rules for running and reporting
Multiple clock cycle designs: State machines Micro programming chapter 5.4 “Computer Organization & Design”
How to reduce T? T = Nq * CPI * Tc Reduce quotient cycles / instruction reduce “cycles” multiple clock- cycle design Increase “instruction” execute more than one instr. per cycle!
More than one instruction per cycle? • Parallelism • Div/mult + floating point + integer • Superscalarity • Multiple issue etc. • Pipelining • Of general importance