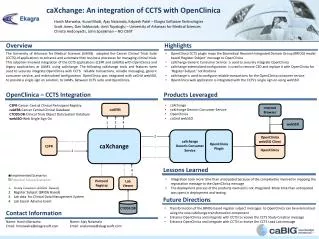
Download

1 / 17
170 likes | 488 Views
Localizing OpenClinica. Hiroaki Honshuku: SQA. What is Character Encoding?. Morse Code (1840) → Latin Alphabet ASCII (1963) The American Standard Code for Information Interchange Characters, Numerals, Symbols, Control Characters 7-bit: 0~127 0x41 = letter ‘ A ’ , 0x61 = letter ‘ a ’

E N D
Localizing OpenClinica Hiroaki Honshuku: SQA
What is Character Encoding? • Morse Code (1840) → Latin Alphabet • ASCII (1963) • The American Standard Code for Information Interchange • Characters, Numerals, Symbols, Control Characters • 7-bit: 0~127 • 0x41 = letter ‘A’, 0x61 = letter ‘a’ • ISO-8859-n • 8-bit: 0-255 • iso-8859-1: Latin-1, covers most of European Language • iso-8859-5: Cyrillic alphabet • No CJK (Chinese, Japanese, Korean) support
What is Character Encoding (cont.) • iso-8859-1 versus iso-8859-5
What is Character Encoding (cont.) • iso-8859-1 versus iso-8859-5 • CJK Encoding Mess • Chinese: Big5 (Traditional), GB18030 (Simplified) • Japanese: iso-2022-JP, EUC-JP, Shift-JIS • Korean: EUC-KR, KS C 5861
What is Character Encoding (cont.) • iso-8859-1 versus iso-8859-5 • CJK Encoding Mess • Chinese: Big5 (Traditional), GB18030 (Simplified) • Japanese: iso-2022-JP, EUC-JP, Shift-JIS • Korean: EUC-KR, KS C 5861 • Windows propriety Encoding • CP1252, CP932, etc
Unicode • 1887: Apple + Xerox • 1991: Unicode Consortium
Unicode • 1887: Apple + Xerox • 1991: Unicode Consortium • UTF-8: 1,112,064 Code Points • Standard • ASCII Compatible • Unix, Linux, Mac OS • Big Endian
Unicode • 1887: Apple + Xerox • 1991: Unicode Consortium • UTF-8: 1,112,064 Code Points • Standard • ASCII Compatible • Unix, Linux, Mac OS • Big Endian • UTF-16 (UCS-2) : 1,112,064 Code Points • Windows Only • Little Endian: Requires BOM (Bite Order Marker)
OpenClinica and i18n • i18n Support since 3.1.3 • OpenClinica i18n Work in Progress • Data Mart • Response OptionText • CRF Name • Discrepancy Note data passing • Escaping Ctrl Chars and MS Propriety Chars • Should detect at CRF upload • Hard-coded strings • Missing encode declaration in some Export formats
Microsoft Specific issues • Display issues on Windows • Pre-Win7, GUI was not fully UTF-8 compatible • Displayed character corruption after saving data • Viewing extracted data • Use UTF-8 compatible Text Editor • Never Copy/Paste from MSOffice
Demonstration • Search Subjects and Tables • CRF and Data Entry • Discrepancy Notes • Rules • Data Import • Data Extract
How to Localize • Documentation • https://docs.openclinica.com/3.1/technical-documents/openclinica-and-internationalization • UTF-8 Converter • i18n strings needs to be Hex value • http://www.branah.com/unicode-converter • Calendar Widget can take UTF-8 strings • Pseudo Translation • Insert one distinctive non-ASCII character • Duplicate English properties files first • Search “ = “ and replace by “ = \u8a66”
How to Localize (cont.) • Duplicate English properties files • Exclude licensing.properties
How to Localize (cont.) • Duplicate English properties files • Exclude licensing.properties • Rename duplicated files to your Locale NO
How to Localize (cont.) • Duplicate English properties files • Exclude licensing.properties • Rename duplicated files to your Locale • Date Format • Edit format.properties file
How to Localize (cont.) • Duplicate English properties files • Exclude licensing.properties • Rename duplicated files to your Locale • Date Format • Edit format.properties file • Translate per GUI page • Avoids possible legacy strings • Use Text Editor that supports global search