Download
1 / 1
10 likes | 120 Views
Motivation. Bidirectional Query Planning Algorithm. Growth of size and popularity of biological deep web data sources Increasing need for querying these data sources Answering cross-source queries manually Identify relevant data sources Submit queries to numerous query forms

E N D
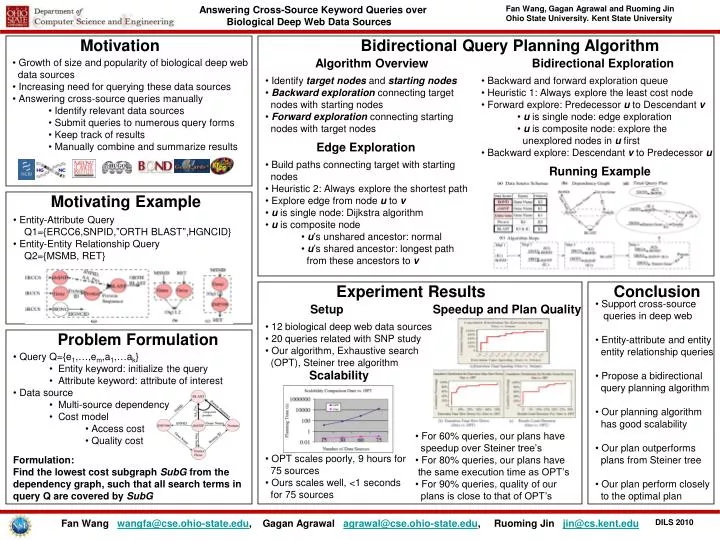
Motivation Bidirectional Query Planning Algorithm • Growth of size and popularity of biological deep web • data sources • Increasing need for querying these data sources • Answering cross-source queries manually • Identify relevant data sources • Submit queries to numerous query forms • Keep track of results • Manually combine and summarize results Algorithm Overview Bidirectional Exploration • Identify target nodes and starting nodes • Backward exploration connecting target • nodeswith starting nodes • Forward exploration connecting starting • nodes with target nodes • Backward and forward exploration queue • Heuristic 1: Always explore the least cost node • Forward explore: Predecessor u to Descendant v • u is single node: edge exploration • u is composite node: explore the • unexplored nodes in u first • Backward explore: Descendant v to Predecessor u Edge Exploration • Build paths connecting target with starting • nodes • Heuristic 2: Always explore the shortest path • Explore edge from node u to v • u is single node: Dijkstra algorithm • u is composite node • u’s unshared ancestor: normal • u’s shared ancestor: longest path • from these ancestors to v Running Example Motivating Example • Entity-Attribute Query • Q1={ERCC6,SNPID,”ORTH BLAST”,HGNCID} • Entity-Entity Relationship Query • Q2={MSMB, RET} Experiment Results Conclusion • Support cross-source • queries in deep web • Entity-attribute and entity • entity relationship queries • Propose a bidirectional • query planning algorithm • Our planning algorithm • has good scalability • Our plan outperforms • plans from Steiner tree • Our plan perform closely • to the optimal plan Setup Speedup and Plan Quality • 12 biological deep web data sources • 20 queries related with SNP study • Our algorithm, Exhaustive search • (OPT), Steiner tree algorithm Problem Formulation • Query Q={e1,…,em,a1,…ak} • Entity keyword: initialize the query • Attribute keyword: attribute of interest Scalability • Data source • Multi-source dependency • Cost model • Access cost • Quality cost • For 60% queries, our plans have • speedup over Steiner tree’s • For 80% queries, our plans have • the same execution time as OPT’s • For 90% queries, quality of our • plans is close to that of OPT’s • OPT scales poorly, 9 hours for • 75 sources • Ours scales well, <1 seconds • for 75 sources Formulation: Find the lowest cost subgraph SubG from the dependency graph, such that all search terms in query Q are covered by SubG





















