Download

1 / 12
120 likes | 138 Views
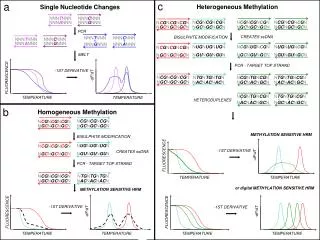
Structural Location of Disease-associated Single-nucleotide Polymorphisms. By Stitziel, Tseng, Pervouchine, Goddeau, Kasif, Liang JMB, 2003, 327, 1021-1030. Presented by Nancy Baker. What is a SNP?. Single nucleotide polymorphism – a single base change

E N D
Structural Location of Disease-associated Single-nucleotide Polymorphisms By Stitziel, Tseng, Pervouchine, Goddeau, Kasif, Liang JMB, 2003, 327, 1021-1030 Presented by Nancy Baker
What is a SNP? • Single nucleotide polymorphism – a single base change • Most common form of human genetic variation • 500,000 SNPs in human coding region • nsSNPs (nonsynonymous cause amino acid changes) • Can cause diseases in many different ways
Goal: is the location of a SNP important? • Do disease causing SNPs occur in one site of a protein more than others? • Possible geometric sites: • Pocket or void • Convex or shallow region • Interior (have 0 solvent accessibility)
Another goal: Get evolutionary perspective • Are SNPs conserved? • Use HMM techniques.
Step 1: Find SNPs associated with disease • OMIM (Online Mendelian Inheritence in Man) • http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?db=OMIM • Picked OMIM SNPs with link to SwissProt • Extracted SwissProt sequences • Ended up with 2128 variants of 310 genes
Step 2: Control Dataset: SNPs not necessarily associated with disease • dbSNP database is source • They admit this is not a perfect control • Extract sequences from Genbank sequences • Use sequences to find structure entry in PDB • End up with 973 variants on 504 genes
Step 3: Where is the SNP in the protein? • Map to PDB structures • For OMIM SNPs – 924 variants in 82 alleles mapped to 129 PDB structures • For dbSNP – 558 variants in 339 alleles mapped to 263 PDB structures • Classify locations: • P: surface pocket or interior void • S: convex or depressed regions • I: interior
Results • Many disease-associated nsSNPs are located in pockets or voids – more likely than non-disease associated nsSNPs – binding pockets • nsSNPs in shallow depressed or convex regions also cause disease - probably because these can also be binding pockets • nsSNPs unlikely to be buried in protein – why? • Buried sites not accessible for molecular recognition and binding • Core mutations either do not affect stability or affect it so much the mutation is fatal – not in population
Results • For interior nsSNPs – no tendency for disease-associated mutations to be conserved • For SNPs in interior – disease-associated SNPs more likely to be conserved
Value of paper • Makes use of available data – no lab work involved • Provides data, but … • http://gila.bioengr.uic.edu/snp • Little vague on some methods • Control set