Download

1 / 43
580 likes | 1.5k Views
Single Nucleotide Polymorphism. Anshu Bhardwaj Research Fellow Centre for Cellular & Molecular Biology Hyderabad 8 th November, 2003. Single Nucleotide Polymorphism. Single base-pair differences occurring in a population with a frequency of >1%. ... C C A T T G A C.

E N D
Single Nucleotide Polymorphism Anshu Bhardwaj Research Fellow Centre for Cellular & Molecular Biology Hyderabad 8th November, 2003
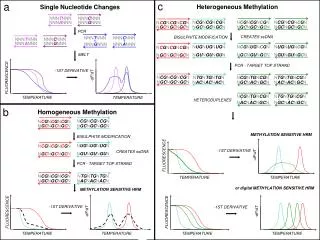
Single Nucleotide Polymorphism Single base-pair differences occurring in a population with a frequency of >1% ...C C A T T G A C... …G G T A A C T G... ...C C G T T G A C... …G G C A A C T G...
SNPs can be found in.. • NON-CODING REGION: • *5’ and 3’ UTR’s • * Introns • * splice sites • CODING REGION: * Non-synonymous • Amino acid substitution * Synonymous • Silent
MUTATION POLYMORPHISM Single base-pair differences occurring in a population with a frequency of >1%
GENOTYPIC FREQUENCY Relative distribution of genotypes in a population for a particular locus
Percent p q MM MN NN Location 83.5 15.6 0.9 0.92 0.08 Greenland ALLELIC FREQUENCY The relative abundance of an allele of a particular gene with reference to its other alleles Let p=f(M) and q=f(N). Thus, p=f(MM) + ½ f(MN) and q=f(NN) + ½ f(MN).
Genotype # of Individuals Genotypic frequencies MM 5118 MM = 5118/6129 = 83.5% MN 956 MN = 956/6129 = 15.6% NN 55 NN = 55/6129 = 0.9% Total 6129 ALLELIC FREQUENCY : The relative abundance of an allele of a particular gene with reference to its other alleles Percent p q MM MN NN Location 83.5 15.6 0.9 0.92 0.08 Greenland Let p=f(M) and q=f(N). Thus, p=f(MM) + ½ f(MN) and q=f(NN) + ½ f(MN). GENOTYPIC FREQUENCY : Relative distribution of genotypes in a population for a particular locus
WHY SNPs ? ? • SNPs are distributed non-randomly throughout the genome • On an average a significant SNP is found for every 1kb of the human genome, resulting in approximately 3 million SNPs • Large number • Unambiguous assay techniques • High levels of polymorphisms in population • Most of the phenotypic differences arise from SNPs in genes, but these form only a small fraction of the total number
dbSNP DENSITY DISTRIBUTION IN HUMAN • Mean Density : • 0.001765 SNPs per base (17.652 SNPs per 10 kb) • Mean Spacing : • 566.5118 bases per SNP
SNP Discovery • SNP Discovery refers to the initial identification of new • SNPs • The established method is electrophoresis(DNA sequencing) • with subsequent data analysis. Some indirect Discovery • techniques (e.g., dHPLC, SSCP) only indicate that a SNP • (or other mutation) exists • DNA sequencing of multiple individuals is used to determine • the point and type of polymorphism
SNP Validation • SNP Validation refers to genetic validation, the process of ensuring that the SNP is not due to sequencing error • Confirmation of SNPs found in discovery • Larger numbers of individual samples to get statistical data on occurrence in the population
THE EXPERIMENTAL APPROACH • RESTRICTION FRAGMENT LENGTH POLYMORPHISM • SINGLE STRANDED CONFORMATIONAL POLYMORPHISM • DENATURING HIGH PRESSURE LIQUID CHROMATOGRAPHY • HYBRIDIZATION METHOD • MALDI-TOF METHOD SEQUENCING & ALIGNMENT THEREAFTER
THE EXPERIMENTAL APPROACH • RESTRICTION FRAGMENT LENGTH POLYMORPHISM • SINGLE STRANDED CONFORMATIONAL POLYMORPHISM • DENATURING HIGH PRESSURE LIQUID CHROMATOGRAPHY • HYBRIDIZATION METHOD • MALDI-TOF METHOD SEQUENCING & ALIGNMENT THEREAFTER
IN SILICO SNP PREDICTION POLYBAYES SEAN SNP Prediction Program SNP Finder
IN SILICO SNP PREDICTION POLYBAYES SEAN SNP Prediction Program SNP Finder
Restriction Fragment Length Polymorphisms Botstein et al (1980) CHANGES IN MIGRATION PATTERNS THAT REPRESENT ALLELIC VARIATION A 3 Kb Homolog 1 12 B 12 A 12 C Homolog 2 1 Kb 2 Kb PROBE B 3 Kb Homolog 1 & 2 C Homolog 1 & 2 1 Kb 2 Kb CAN BE USED TO DETECT SNPs DIFFERENTIALLY IN HOMOZYGOUS & HETEROZYGOUS INDIVIDUALS
MALDI-TOF METHOD Matrix-assisted laser desorption ionization-time of flight
High Voltage Sample Laser Detector source Drift region
POLYBAYES BAYESIAN INFERENCE ENGINE TO CALCULATE THE PROBABILITY THAT A GIVEN SITE IS POLYMORPHIC • FRAGMENT CLUSTERING • PARALOGUE IDENTIFICATION • MULTIPLE ALIGNMENT
SNP DETECTION IN REDUNDANT SEQUENCE DATA SEQUENCE CLUSTERING CLUSTER REFINEMENT MULTIPLE ALIGNMENT SNP DETECTION
The PolyBayes Approach • Use genomic sequence as reference • cluster and align all available sequences • remove repeats/paralogs • Use Bayesian statistics to • distinguish polymorphic sites from artifacts • estimate likelihood • Marth, GT, Korf, I, Yandell, MD, Yeh, RT, Gu, Z, Zakeri, H, Stitziel, NO, Hillier, L, Kwok, P-Y, Gish, WR: A general approach to single-nucleotide polymorphism discovery. Nature Genet. 1999; 23:452-456.
1. Known repeat sequences are masked using RepeatMasker 2. FRAGMENT CLUSTERING (a) WU-BLAST used to search against dbEST (b) Sequence traces processed with PHRED base-calling values (c) Distinct group of matching ESTs registered as clusters 3. Each cluster member pair-wise aligned to the genomic anchor sequence with CROSS_MATCH
PARALOGUE IDENTIFICATION 1. May give rise to false SNP predictions & points to difficulties during marker development 2. Calculate probability PNAT that a cluster member is derived from genomic region. 3. Distinguish between less accurate sequences that nevertheless originate from the same underlying genomic location More accurate sequences with high-quality discrepancies that are likely to be paralogous 4. Using a threshold value PNAT,MIN paralogous cluster members are removed
1 1+e(DNAT- DPAR).(DPAR/DPAR) DNAT = L * PPOLY.2 + E (PPOLY.2 = 0.001) DPAR = L * PPAR + E (PPAR =0.02) d = discrepancies P(MODELNAT|D) = PNAT,MIN = 0.75
MULTIPLE ALIGNMENT • Depth of coverage • The base-quality values of the sequences • The a priori expected rate of polymorphic sites in the region • PSNP PROBABILITY THAT THE SITE IS POLYMORPHIC • DISTRIBUTION OF PROBABILITY SCORES EXHIBITS A • HIGH LEVEL OF SPECIFICITY
OTHER SNP PREDICTION & SNP FINDING SOFTWARE • SEAN: Search for localized SNPs and predict SNPs • (http://zebrafish.doc.ic.ac.uk/Sean/) • SNP Finder: For analyzing user-submitted trace data (http://gai.nci.nih.gov/)
SIGNIFICANCE OF SNPs • IN DISEASE DIAGNOSIS • IN FINDING PREDISPOSITION TO DISEASES • IN DRUG DISCOVERY & DEVELOPMENT • IN DRUG RESPONSES • INVESTIGATION OF MIGRATION PATTERNS ALL THESE ASPECT WILL HELP TO LOOK FOR MEDICATION & DIAGNOSIS AT INDIVIDUAL LEVEL
SNP Screening • Two different screening strategies - Many SNPs in a few individuals - A few SNPs in many individuals • Different strategies will require different tools • Important in determining markers for complex genetic states
SNP genotyping methods for detecting genes contributing to susceptibility or resistance to multifactorial diseases, adverse drug reactions: • => case-control association analysis ….GCCGTTGAC…. ….GCCATTGAC…. ….GCCATTGAC…. ….GCCATTGAC…. case control allele frequency genotype frequency haplotype frequency A %, G% AA %, AG %, GG% SNP1, SNP2, SNP3
HAPLOTYPE A set of closely linked genetic markers present on one chromosome which tend to be inherited together (not easily separable by recombination)
SNP-Haplotype Phenotype SNP SNP BLACK EYE BROWN EYE BLACK EYE BLUE EYE BROWN EYE BROWN EYE GATATTCGTACGGA-T GATGTTCGTACTGAAT GATATTCGTACGGA-T GATATTCGTACGGAAT GATGTTCGTACTGAAT GATGTTCGTACTGAAT Haplotypes AG 2/6(BLACK EYE) GTA 3/6(BROWN EYE) AGA 1/6 (BLUE EYE) 1 2 3 4 5 6 DNA Sequence
HAPLOTYPE CORRELATION WITH PHENOTYPE • The “Haplotype centric” approach combines the information of adjacent SNPs into composite multilocus haplotypes. • Haplotypes are not only more informative but also capture the regional LD information, which is assumed to be robust and powerful • Association of haplotype frequencies with the presence of desired phenotypic frequencies in the population will help in utilizing the maximum potential of SNP as a marker.
ADVANTAGES: SNPs ARE THE MOST FREQUENT FORM OF DNA VARIATIONS THEY ARE THE DISEASE CAUSING MUTATIONS IN MANY GENES THEY ARE ABUNDANT & HAVE SLOW MUTATION RATES EASY TO SCORE MAY WORK AS THE NEXT GENERATION OF GENETIC MARKERS
LIMITATIONS: 1.EXPERIMENTAL DETECTION OF SNPs REQUIRES IMPLEMENTATION OF EXPENSIVE TECHNOLOGIES 2. NEED FOR LARGE POPULATION DATASETS FOR ASSOCIATION STUDIES
Some important SNP database Resources 1. dbSNP (http://www.ncbi.nlm.nih.gov/SNP/) LocusLink (http://www.ncbi.nlm.nih.gov/LocusLink/list.cgi) 2. TSC (http://snp.cshl.org/) 3. SNPper (http://snpper.chip.org/bio/) 4. JSNP (http://snp.ims.u-tokyo.ac.jp/search.html) 5. GeneSNPs (http://www.genome.utah.edu/genesnps/) 6. HGVbase (http://hgvbase.cgb.ki.se/) 7. PolyPhen (http://dove.embl-heidelberg.de/PolyPhen/) OMIM (http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?db=OMIM) 8. Human SNP database (http://www-genome.wi.mit.edu/snp/human/) Feb. 25. 2003 SI Hung