Download

1 / 59
590 likes | 674 Views
Optimisations Mémoire dans la Méthodologie AAA pour Code Embarqué sur Architectures Parallèles. RAULET Mickaël 18 mai 2006 Mitsubishi ITE - Equipe Software Radio IETR/INSA - Groupe Image INRIA – Groupe AOSTE. Plan. Introduction Objectifs Problématique SynDEx Minimisation mémoire

E N D
Optimisations Mémoire dans la Méthodologie AAA pour Code Embarqué sur Architectures Parallèles RAULET Mickaël 18 mai 2006 Mitsubishi ITE - Equipe Software Radio IETR/INSA - Groupe Image INRIA – Groupe AOSTE
Plan • Introduction • Objectifs • Problématique • SynDEx • Minimisation mémoire • Applications • Conclusions perspectives
Introduction : Objectifs • Développement d’une méthodologie de prototypage rapide pour architectures complexes • Diminution du temps de développement pour le portage sur une cible multi-composants (PC, DSP et/ou FPGA) • Développement d’applications dans le domaine de l’embarqué (téléphonie mobile, décodeurs de salons) • Réalisation de démonstrateurs
Prototypage rapided’applications de traitement du signal et images pour systèmes embarqués temps réelsur architectures distribuées hétérogènes Méthodologies pour passer rapidement (automatiquement) d’une description de haut niveau de l’application à une implantation exécutable Méthodologie AAA (Adéquation Algorithme Architecture) Introduction : Problématique
Prototypage rapide d’applications de traitement du signal et imagespour systèmes embarqués temps réelsur architectures distribuées hétérogènes Applications fortement orientées données Introduction : Problématique
Prototypage rapide d’applications de traitement du signal et images pour systèmes embarqués temps réelsur architectures distribuées hétérogènes Minimisation des ressources et exécution “suffisamment” rapide Introduction : Problématique
Prototypage rapide d’applications de traitement du signal et images pour systèmes embarqués temps réelsur architectures distribuéeshétérogènes Distribution/ordonnancement des traitements Introduction : Problématique
Prototypage rapide d’applications de traitement du signal et images pour systèmes embarqués temps réelsur architectures distribuées hétérogènes Mise en oeuvre conjointe de composants cible variés Travaux essentiellement sur cibles multi-composants Introduction : Problématique
Introduction : Problématique • Systèmes multi-composants • Systèmes embarqués • Limitation mémoire • Traitement du signal, télécommunications et vidéo • Consommation mémoire importante • Nécessité d’une optimisation mémoire • Nécessité d’une méthodologie adaptée
SynDEx : Présentation • SynDEx : Synchronized Distributed Executives • Logiciel de CAO niveau système pour applications distribuées temps réel et embarquées • INRIA Rocquencourt projet AOSTE (Y. Sorel) • Fonctionnalités • Partitionnement/ordonnancement automatiques d’une application sur une architecture cible • Algorithme glouton basée sur une minimisation de la latence (optimisation orientée vitesse) • Génération d’un exécutif distribué indépendant de la cible
SynDEx : Caractéristiques • Approche globale • Modèle unifié de graphes • Algorithme : parallélisme potentiel • Architecture : parallélisme disponible • Implantations : transformations de graphes • Adéquation • Choix d’une implantation optimisée • But • Génération automatique d’exécutifs • taillés sur mesure aux applications, • basés sur un ordonnancement hors-ligne des calculs et des communications
SynDEx : Caractéristiques Graphe Temporel root FIFOs DSP1 Graphe d’Architecture Adéquation Graphe d’ Algorithme Opéra-tions Opéra-tions - Niveaux hiérarchiques - Conditionnement- Répétition www.syndex.org
SynDEx : Caractéristiques • Exécutif supporte : • l’exécution de l’algorithme sur l’architecture • l’ordonnancement, les communications et les synchronisations • Taillé sur mesure : • Minimisation du surcoût spatial et temporel • Implantation optimisée (latence) • Sans inter-blocage, garantie ordre total du graphe d’algorithme • Basé sur macro-code • Indépendant du processeur • Supportant des architectures hétérogènes, portabilité • Basé sur des bibliothèques génériques dépendantes • des processeurs (DSP, PC, FPGA…) • des communicateurs (SAM=FIFO, RAM)
Plan • Introduction • SynDEx • Présentation • Caractéristiques • Chaîne de développement • Minimisation mémoire • Applications • Conclusions perspectives
Algorithme Architecture Adéquation • Télécommunication • UMTS • MC-CDMA • Vidéo • LAR • MPEG4 • Plate-formes • Sundance • Pentek • Composant • DSP • FPGA Exécutifs Génériques Bibliothèques Exécutifs Spécifiques SynDEx : Chaîne de développement • Prototypage rapide et domaine d’applications
PC (Pentium) Personal Computer PCI Embedded Motherboard: SMT320 DSP2 (TMS320C6416) PCI (BUS_PCI ) SDBa SDBb CP0 CP1 PCI SMT361 Bus_6 (CP) FPGA1 (Virtex) SDBa SDBb CP0 CP1 CP2 Bus_3 (SDB) CP3 SMT358 Bus_1 (SDB) IN (VID_IN) PALtoYUV (BT829) DSP3 (TMS320C6414) VID_IN SDBa SDBb OUT (VID_OUT) YUVtoPAL (BT864a) VID_IN VID_OUT VID_OUT SMT319 SynDEx : Chaîne de développement • Exemple de topologie : Sundance Module DSP Module FPGA Framegrabber Plusieurs types de processeurs et de communicateurs
C62x.m4x SDB.m4x ( C 6 2x , C64x ) , Fpga C64x.m4x CP.m4x ( C 62x , C64x ) , Fpga Pentium.m4x BUS_PCI_RAM.m4x ( Pentium , C62x , C64x ) Fpga.m4x BUS_PCI_SAM.m4x ( Pentium , C62x , C64x ) TCP.m4x ( Pentium , C62x ) Bifo.m4x (C62x, Fpga ) Bifo_DMA.m4x (C62x, Fpga ) SynDEx : Chaîne de développement • Arborescence des bibliothèques Génération de code Dépendant de Dépendant de Générique l’architecture l’application SynDEx.m4x ApplicationName.m4x Dépendant du Dépendant du Type de media Type de processeur
SynDEx : Chaîne de développement • Développements de nombreuses bibliothèques • Vérification fonctionnelle • Ajout de fonction d’affichage de l’image directement sous SynDEx • Display générique • Webcam • Vérification et exploration architecturale TCP • facilitant la vérification fonctionnelle de l’application • séparation de codeur-décodeur • possibilité de décrire des architectures complexes (multi-PC) • plateformes de test et de vérification
Plan • Introduction • SynDEx • Minimisation mémoire • Objectifs • Principes d’allocation • Mono-composant • Multi-composants • Applications • Conclusions perspectives
Minimisation mémoire : Objectifs Algorithme Architecture Adéquation Génération de Code Minimisation des allocations de buffers
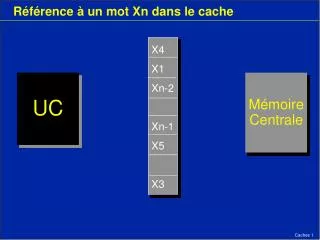
Minimisation mémoire : Principes d’allocation allocD allocD allocD allocD Une allocation (buffer) allouée pour chaque sortie
all.Po1 all.Dlo1 all.Dlo1 all.D_o1o2 all.D_o1o2 all.Po2 all.Dl2 all.Dlo2 all.Po2 all.Po3 all.Po1 all.Po4 all.D_o2o3 all.D_o2o3 all.Po3 all.Dlo3 all.D_o3o4 all.Dlo3 all.D_o3o4 all.Dlo4 all.Po4 all.Dlo4 Minimisation mémoire : Mono-composant Ram D/P ESPACE MEMOIRE RAM données données communiquées locales programmes opr1 o1 o2 o3 all.D_o3o4 o4
Légende f Td Tf b a e Durée d ’allocation du registre c Graphe d’intervalles d Tri par ordre croissant des dates de début b d a f c e Graphe d ’intervalles Minimisation mémoire : Mono-composant • Coloriage de graphe • Approche classique • minimisation des buffers (« registre ») 3 couleurs = 3 buffers • Méthode gloutonne • Minimum de couleur • Buffers de même type et de même taille
Minimisation mémoire : Mono-composant • Autre Méthode mono-composant • Minimisation « tétris » • Basée également sur la durée de vie des buffers • Basée uniquement sur des buffers de même type Minimum 6 couleurs = 6 registres
Plan • Introduction • SynDEx • Minimisation mémoire • Objectifs • Principes d’allocation • Mono-composant • Multi-composants • Applications • Conclusions perspectives
Minimisation mémoire : Multi-composants • Considération des buffers communiqués inter-processeurs • Diminution accrue de l’espace mémoire • Durée de vie des buffers communiqués liée au modèle de synchronisation de SynDEx
allocP calc1 allocDl in out allocP calc2 allocDl allocD allocD allocD calc1 send receive allocD in out allocD allocD allocD calc2 send receive allocD allocP allocP allocDl allocDl Minimisation mémoire : Multi-composants • Distribution/ordonnancement processeur1 processeur2 Opr1 RAM D/P Com1a Com2a RAM D/P Opr2 SAM
in_ini out_ini all.Pin loop loop loop all.Pcalc loop all.Dlin all.Dlcalc all.Din/calc all.Din/calc all.Din/calc all.Dcalc/out all.Pout all.Dlout endloop endloop endloop endloop in_end out_end Minimisation mémoire : Multi-composants processeur1 processeur2 Opr1 RAM D/P Comr1a Comr2a RAM D/P Opr2 SAM in send receive calc out
Suc-E in Pre-F Suc-F send s_empty Suc-E Pre-E Suc-E Pre-F Suc-F in Pre-F s_full Suc-F send Pre-E Pre-E Minimisation mémoire : Multi-composants • Schéma de principe dans SynDEx processeur1 Opr1 RAM D/P Comr1a loop loop Durée de vie du buffer sur un cycle in Pas de réutilisation possible des buffers communiqués inter-processeurs send endloop endloop
loop loop in1 Pre-F Suc-E s_empty Suc-F send Suc-F Pre-E Suc-E Pre-F s_full Pre-E Calcul endloop endloop Minimisation mémoire : Multi-composants processeur1 Opr1 RAM D/P Comr1a loop loop Durée de vie du buffer minimale in1 send Calcul Communications bloquantes Modèle SynDEx endloop endloop
loop loop in1 Pre-F Suc-E s_empty Suc-F send Suc-F Calcul1 Pre-E Pre-F s_full Pre-E Suc-E Calcul2 endloop endloop Minimisation mémoire : Multi-composants processeur1 Opr1 RAM D/P Comr1a loop loop Durée de vie du buffer = adéquation in1 send Calcul Communications comme sur le graphe temporel endloop endloop
Minimisation mémoire : Multi-composants • Solution : • Modifications du modèle SynDEx • Sans changement de l’ordre total • Avec prise en compte des temps de communications • Sans changement de la latence • Optimisations de la mémoire avec un gain important
Minimisation mémoire : Multi-composants • Principe de la réutilisation
Minimisation mémoire :Conclusion • Minimisation mémoire mono-composant efficace • Minimisation « registre » • Minimisation « tétris » • Minimisation mémoire multi-composants • Prise en compte des buffers communiqués inter-processeurs • Optimisation supplémentaire de la génération de code • Opérations implicites générant des « recopies » de buffers à buffers : • Explode – implode • Conditionnement • Retard ou mémoire
Plan • Introduction • SynDEx • Minimisation mémoire • Applications • UMTS • MPEG-4 • LAR • Conclusions perspectives
Applications : UMTS FDD • Troisième génération de téléphone portable • Caractéristiques • Débits maximum 2 Mbits/sec • Temps réel 10ms par trame • 1 trame = 15 slots
Applications : UMTS (Tx) • init • trame par trame trame • slot par slot init slot
Applications : UMTS • Minimisation UMTS • Portage sur un C6203 à 512 ko de RAM • Automatique Mieux que manuellement • Gain de 7 Très proche d’un gain attendu de 7.5 • Minimisation de toutes les recopies Diminution du temps
Applications : MPEG-4 • Successeur de MPEG-2 • Norme composée de sous-parties • Partie 2 = Vidéo • Norme complexe (boîte à outils) • Scène composée d’objets • Images de synthèse • Images naturelles • …
Application : Décodeur MPEG-4 • Décodeur images I (Intra) existant : • Description bas niveau Granularité fine • 3 niveaux d’abstraction de description • Niveau image haut niveau • Image I, P et B • Niveau macrobloc niveau intermédiaire • 16 * 16 pixels • Niveau bloc bas niveau • 6 blocs dans un macrobloc • 4 blocs de luminance • 2 blocs de chrominance
Description niveau Image Images I Images P Images B Base des descriptions plus détaillées Description niveau intermédiaire Description bas niveau Séquence Vidéo Image P Image I Image B Affichage Image Application : Décodeur MPEG-4 Description gros grain
Vop_coding_type = 4 Vop_coding_type = 1 Vop_coding_type = 0 Image I Image P Image B Application : Décodeur MPEG-4Description gros grain Récupération de l’image dans le flux affichage Choix du type de décodage d’image Mémorisation image
Application : Décodeur MPEG-4Description gros grain • Description de haut niveau • Gros grain • Résultats sur DSP (C6416 à 400 MHz) • Extension de ces résultats sur DSP à 1GHz • Temps moyen avec communications • QCIF : 5 ms • CIF : 12 ms • 640*480 : 30 ms
Application : Décodeur MPEG-4Description grain fin • Décodeur bas niveau grain fin • Granularité du décodeur : • VLC inverse (VLC = codage à longueur variable) • Scan inverse (scan = balayage) • DCT inverse (DCT = transformée discrète en cosinus) • … • Possibilité de parallélisme • Basée sur • Description haut niveau • Description images I bas niveau
Séquence Vidéo Description haut niveau Image I Image P Niveau macrobloc Macrobloc I Macrobloc P MB Codé MB non codé MB INTRA I MB INTRA P MB INTRAQ P MB INTER MB INTERQ MB INTER4V VLC inverse MB Blocs Luminance I Bloc Cb I Bloc Cr I Interpolation MB Blocs Luminance P Bloc Cb P Bloc Cr P Blocs Luminance non codés Bloc Cb Non codé Bloc Cr Non codé Niveau bloc X1 I X2 I X3 I X4 I XCb I XCr I X1P X2 P X3 P X4 P XCb P XCr P Description Images I bas niveau Description Images P bas niveau cbp Xn = 0 cbp Xn = 1 Application : Décodeur MPEG-4Description grain fin • Schéma hiérachiques :
Complexité SynDEx du décodeur bas niveau Nombre d’opérations proportionnel au nombre de macroblocs • Temps pour générer l’exécutif (QCIF > 12 h !) • Longueur de l’exécutif Nombre d’opérations Description intermédiaire niveau macrobloc Application : Décodeur MPEG-4Description grain fin
Application : Décodeur MPEG-4Description gros grain • Décodeur MPEG-4 sur 2 processeurs : • description de haut niveau (352*288) • Gain de 54 recopies • Minimisation mémoire : • Gain de 1,6 (Granularité de l’application trop forte)
Application : Décodeur MPEG-4Description gros grain • Haut niveau • Niveau intermédiaire • Bas niveau
Applications : LAR • Méthode développé au sein du laboratoire Image • Méthode basée contenu • Méthode hiérarchique • Images fixes • Fort taux de compression