Download

1 / 39
390 likes | 508 Views
Semantisk opmærkning. Bolette Sandford Pedersen Center for Sprogteknologi. Indhold. semantisk opmærkning af tekstkorpus (opmærkningssprog: xml - projekt: Senseval ) semantiske ordbøger beskrevet med opmærkningssprog (opmærkningssprog: sgml - projekt: SIMPLE )

E N D
Semantisk opmærkning Bolette Sandford Pedersen Center for Sprogteknologi
Indhold • semantisk opmærkning af tekstkorpus (opmærkningssprog: xml - projekt: Senseval) • semantiske ordbøger beskrevet med opmærkningssprog (opmærkningssprog: sgml - projekt: SIMPLE) • Eksempel på anvendelse af semantisk opmærkning i applikation: Indholdsbaseret søgning (projekt: OntoQuery)
Semantisk opmærkning af tekstkorpus: Senseval Formål: at opbygge semantisk opmærkede korpora på forskellige sprog: Gold Standards Hvorfor: for at muliggøre test af værktøjer til entydiggørelse af flertydige ord på de samme tekster Projektstatus: verdensomspændende ufinansieret projekt hvor man deltager på frivillig basis; der igangsættes løbende ’konkurrencer’
Senseval Initiativtagere: Scott Cotton, University of Pennsylvania Phil Edmonds, Sharp Laboratories of Europe Adam Kilgarriff, ITRI, University of Brighton Martha Palmer, University of Pennsylvania web-site: http://www.sle.sharp.co.uk/senseval2/
Fælles referenceramme: XML • Projekthjemmeside hvor alle krav er specificeret • Document type definition (dtd) tilgængelig på nettet • eksempler på de filer der skal genereres på hvert sprog • krav for deltagelse: producer disse filer i parset format for eget sprog og få dem oploadet på hjemmesiden inden deadline
Dansk deltagelse i Senseval • Center for Sprogteknologi • Institut for Datalingvistik, Handelshøjskolen i København Vi afsluttede opmærkningen i 2001 Data er (endnu) ikke blevet anvendt til entydiggørelse, men korpus er tilgengængeligt på http://cst.ku.dk/senseval/index.html Steder hvor der arbejdes med automatisk entydiggørelse: http://ilk.kub.nl/ (Tilburg) http://trec.nist.gov/pubs/trec10/t10_sysdes/insightsoft/insight.html http://svenska.gu.se/%7Esvedk/software.html)
Dansk deltagelse i Senseval Det danske trænings- og evalueringsmateriale indbefatter betydningsopmærkede korpuseksempler for 100 flertydige ord på dansk, heraf • 50 substantiver, • 25 adjektiver • 25 verber. For hvert ord er der betydningsopmærket gennemsnitligt 150 eksempler - afhængigt af hvor flertydigt ordet er.
Beregningsfaktor • hvis et ord har n betydninger i en ’mellemstørrelsesordbog’ (Nudansk) så undersøg 100 + 15n korpuseksempler med dette ord (f.eks. 120 eksempler for et ord med 3 betydninger) • f.eks. røre: 8 betydninger i Nudansk Ordbog giver 100 + 120 = 220 korpuseksempler, underbetydninger og idiomatiske udtryk tælles med
Semantiske ordbøger beskrevet med opmærkningssprog • vi taler her om sprogteknologiske ordbøger som har computeren som primær bruger (men naturligvis mennesker som sekundære brugere) • skal udformes i et formelt sprog • opmærkningssprog som sgml og xml er velegnede hertil • fælles referenceramme for den semantiske ordbog: sgml
Om SIMPLE • SIMPLE-projektet var et EU-projekt som blev afsluttet i 2000 • Formål: at udarbejde harmoniserede semantiske ordbøger for 12 EU sprog (Semantic Information for Multifunctional, Plurilingual Lexica) • 10.000 betydninger for hvert sprog • på basis af en fælles ontologi, SIMPLE-ontologien (Lenci et al. 2001)
Hvorfor skal der være semantik i en sprogteknologisk ordbog ? Niveau 1: f.eks. maskinoversættelse kræver at maskinen kan entydiggøre ord som kan betyde flere ting: Kosten var velsmagende tiden går
Semantik Niveau 2: F.eks. avanceret informationssøgning kræver at maskinen i en vis forstand kan fortolke ord: Søgeudtryk: støtte til solvarme Finde tekster med: tilskud til energibesparende foranstaltning støtte og tilskud er synonymer solvarme erunderbegreb til energibesparende foranstaltning
Semantik Niveau 3: ’Fuld’ maskinel fortolkning til programmer som skal ’forstå’ naturligt sprog: Hans dansede med sin borddame For at maskinen skal kunne ’identificere’ hvem der refereres til med ordet borddame - skal den vide at det er den kvinde han sad ved siden af under middagen.
Hvor står semantikken i almindelige ordbøger? NUDANSK ORDBOG: Puslespil ORDKLASSE: subst.BØJNING: puslespillet, plur. puslespil, puslespilleneBETYDNING: et spil med træ- el. papbrikker i forskellige faconer som skal lægges sammen så de danner et heleEKSEMPEL: lægge puslespil på 2.000 brikkerSAMMENSÆTNING: puslespilsbrik
puslespil som flerdimensionel type et spil med træ- el. papbrikker i forskellige faconer som skal lægges sammen så de danner et heleoverbegrebdele formåloprindelse spil træbrikkersamles til et heleudskære papbrikker puslespil
En ordbogsindgang med semantik Semantic Unit puslespil Definition: et spil med træ- el. papbrikker i forskellige faconer som skal lægges sammen så de danner et hele (NDO) Corpus example:nu var hun næsten ved at være færdig med det puslespil, hun var begyndt på lige efter påske Ontological type:Artifact Unification Path Concrete_Entity|Agentive|Telic Domain: General Formal quale: is_a = spil Agentive quale: created_by = udskære Telic quale: used_for = samle til et hele Constitutive quale:has_as_parts=træbrikker OR papbrikker
Eksempel på anvendelse af semantisk opmærkning i applikation • Indholdsbaseret søgning er en applikationstype hvor sprogteknologi har en funktion
Problemer ved informationssøgning - kort fortalt for mange informationer: • ord kan betyde flere ting; de er flertydige • ca. 23 % af alle ord der søges på er flertydige; • ca. 10% af alle navne der søges på er flertydige) Torkildsen, Holen og Johannessen 2000 for få informationer: • vi har flere ord for de samme begreber, synonymer og synonyme udtryk
Problemer ved informationssøgning • vi får for mange informationer som ikke er prioriteret godt nok og som derfor er vanskelige at holde rede på idet meget af det er irrelevant • vi får for få informationer i forhold til hvad der rent faktisk er tilgængeligt på nettet fordi vi ikke har ’ramt’ den rigtige formulering i forespørgslen begge problemer vil delvist kunne afhjælpes hvis søgesystemerne har en større sproglig viden
Sproglig viden til informationssøgning sproglige problemer på basisniveau • vi har mere eller mindre den sproglige viden - også for dansk og i en formaliseret version - men den er ikke indarbejdet i alle søgesystemer sproglige problemer der kræver mere indholdsmæssig viden • de sproglige ressourcer skal udvikles problem: nye tekster - nyt indhold
Sproglige problemer på basisniveau • ordene kan antage flere former orlovsordninger, orlovsordningen, orlovsordningerne reduktion til grundformer (lemmatisering) kan afhjælpe dette problem • simpel flertydighed: ordene kan tilhøre forskellige ordklasser klager/N;U over/PRÆP; ADV læger/N;U syntaktisk tagger kan afhjælpe problemet efter tagging: klager/N over/PRÆP læger/N
Sproglige problemer der kræver mere indholdsmæssig viden flertydighed inden for samme ordklasse vitaminrig kost/ fejekost - mad flere indholdsmæssige forhold kan afhjælpe flertydighedsproblemet: • domæneviden hvis vi kender domænet, kan vi vælge • viden om ordenes interne struktur hvis vi ved noget om kosts nærende funktioner, kan vi vælge • kost og sygdomme • klager/N;U over/PRÆP; ADV læger/N;U • syntaktisk tagger kan afhjælpe problemet • efter tagging: klager/N over/PRÆP læger/N • begge problemer vil delvist kunne afhjælpes hvis søgesystemerne har en større sproglig viden • sproglige problemer på basisniveau • sproglige problemer der kræver indholdsmæssig viden
Sproglige problemer der kræver mere indholdsmæssig viden synonymi - flere betegnelser for det samme kan betyde at vi får for få søgeresultater forældreorlov - børnepasningsorlov støtte - tilskud / computer - datamat / diabetes - sukkersyge anvendelse af synonymiordbog kan afhjælpe problemet
Ontologisk viden • underbegreber kan være relevante vitaminer har_som_underbegreber k-vitamin, c-vitamin, d-vitamin,thiamin • overbegreber kan være relevante solvarme har_som_overbegreb energibevarende foranstaltning
Ontologisk viden er central ontologisk viden kan danne baggrund for en semantisk beregning sådan at søgeresultater prioriteres på basis af sprogligt indhold den semantiske afstand mellem søgeudtryk og søgeresultat beregnes f.eks. ud fra hvor mange ’niveauer’ man skal ned i en given ontologi for at finde resultatet: søgeudtryk: sygdom tekst1: sygdom tekst2: kræft tekst3: lungekræft
Forskningsområde: hvor vigtig er relationerne ml. ordene? Traditionelle søgemaskiner ser på nærhed ml. søgeordene men ikke på relationerne forespørgsel: hvilke sygdomme har at gøre med mangel på vitamin i kosten ? googlesvar: alkoholforbrug og mangel på fysisk aktivitet ... hvordan kosten er sammensat kilde: Paggio, Pedersen & Haltrup (forthcoming)
SIMPLEs anvendelse i indholdsbaseret søgning OntoQuery: Ontology-based Querying Et dansk samarbejdsprojekt 1999-2004 Partnere: Roskilde Universitet Danmarks Tekniske Universitet Handelshøjskolen i København Syddansk Universitet Center for Sprogteknologi
Formålet med OntoQuery- projektet At udvikle en metode til indholdsbaseret søgning • at gå videre end mønstergenkendelse ved at lave en ‘rå’ lingvistisk analyse på baggrund af en ontologi • der produceres en ‘rå’ semantisk analyse af tekst og af forespørgsel • søgning foregår ved at sammenligne beskrivelser og finde det bedste ‘match’ mellem forespørgsel og tekst på basis af ontologien dels på begreberne alene, dels på relationerne mellem begreberne
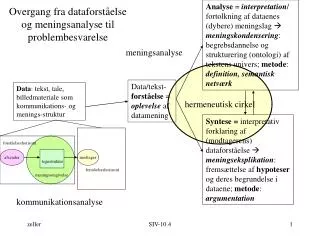
SystemOverview Text fragment Query Description Generator Lexicons Ontology Linguistic Analysis Mapping to description Text database OntoLog descriptions Query Engine
Eksempel fra SIMPLE-ontologien kanin - 3 betydninger: 1. animal, 2. meat, 3. material kanin kød mad Substance Food Food Telic Top Concrete entity Entity Top
Ernæringsontologien • lavet på baggrund af Den Store Danske Encyklopædi • enkelte knuder er etableret for at strukturere ontologien,f.eks. stof-i-krop • ernæringsontologien er organiseret under 2 forskellige knuder i SIMPLE-ontologien
Eksempel fra ernæringsontologien A-vitamin fedtopløseligt vitamin vitamin mikronæringsstof næringsstof Natural Substance Substance Concrete entity Entity Top
Anvendelse af ontologien:analyse af tekst og forespørgsler Tekster og forespørgsler (NP’er) analyseres mangel på vitaminer i kosten (mangel x (WRT: vitamin) x (LOC: diet))
Opmærkning af teksterne Der bygges begrebsrepræsentationer på basis af: • POS-tagging • NP-genkendelse • semantisk opnmærkning
Lingvistiske komponenter Hvilke sygdomme har at gøre med mangel på vitaminer i kosten? POS-Tagger hvilke/PRON sygdomme/N har/V_PRES at /UNIK gøre/V_INF med/PRÆP mangel/N på/PRÆP vitaminer/N i/PRÆP kosten/N ?/TEGN NP recogniser [NP hvilke sygdomme]har at gøre med [NP mangel på vitaminer i kosten]. NP parser ... NP Sem: CONCEPTmangel RELwrtRELloc ARGvitamin ARG kost N PP P NP Mapping to Descriptions N PP (mangel x (WRT: vitamin) x (LOC: kost))
OntoQuerys hypotese: Hvis vi kan identificere den semantiske relation der holder mellem 2 begreber kan vi prioritere gode hits bedre og vi kan genkende det samme eller lignende begreber i forskellig forklædning, f.eks. overvægtige børn, børn med overvægt, fede børn børn med fedmeproblemer, børn der har fedmeproblemer