Download

1 / 1
10 likes | 109 Views
Development of Social Interaction. Locate target. Foveate Target. Apply Face Filter. Software Zoom. Feature Extraction. Gaze Direction. Development of Commonsense Knowledge. . Development of Sequencing. Development of Coordinated Body Actions. 300 msec. 66 msec.

E N D
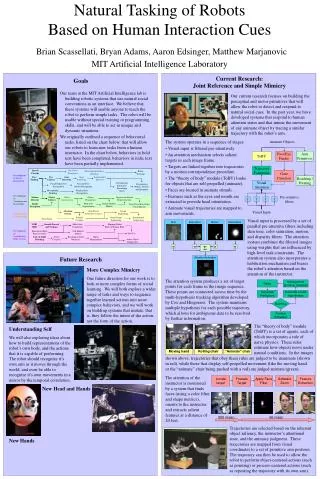
Development of Social Interaction Locate target Foveate Target Apply Face Filter Software Zoom Feature Extraction Gaze Direction Development of Commonsense Knowledge Development of Sequencing Development of Coordinated Body Actions 300 msec 66 msec Speech Prosody Vocal Cue Production Directing Instructor’s Attention Robot Teaching Face Finding Eye Contact Gaze Direction Gaze Following Intentionality Detector Recognizing Instructor’s Knowledge States Facial Expression Recognition Arm and Face Gesture Recognition Recognizing Beliefs, Desires, and Intentions Recognizing Pointing Familiar Face Recognition Motion Detector Object Saliency Object Segmentation Object Permanence Expectation-Based Representations Body Part Segmentation Human Motion Models Depth Perception Long-Term Knowledge Consolidation Attention System Task-Based Guided Perception Action Sequencing Schema Creation Social Script Sequencing Instructional Sequencing Turn Taking Skin Saturation Motion Habituation VOR/ OKR Smooth Pursuit and Vergence Multi-Axis Orientation Mapping Robot Body to Human Body Kinesthetic Body Representation Self-Motion Models Tool Use Line-of-Sight Reaching Simple Grasping Reaching Around Obstacles Object Manipulation Active Object Exploration w w w w Attention Activation Natural Tasking of Robots Based on Human Interaction CuesBrian Scassellati, Bryan Adams, Aaron Edsinger, Matthew MarjanovicMIT Artificial Intelligence Laboratory Current Research: Joint Reference and Simple Mimicry Goals Our team at the MIT Artificial Intelligence lab is building robotic systems that use natural social conventions as an interface. We believe that these systems will enable anyone to teach the robot to perform simple tasks. The robot will be usable without special training or programming skills, and will be able to act in unique and dynamic situations. We originally outlined a sequence of behavioral tasks, listed on the chart below, that will allow our robots to learn new tasks from a human instructor. In the chart below, behaviors in bold text have been completed, behaviors in italic text have been partially implemented. Our current research focuses on building the perceptual and motor primitives that will allow the robot to detect and respond to natural social cues. In the past year, we have developed systems that respond to human attention states and that mimic the movement of any animate object by tracing a similar trajectory with the robot’s arm. • The system operates in a sequence of stages: • Visual input is filtered pre-attentively. • An attention mechanism selects salient targets in each image frame. • Targets are linked together into trajectories by a motion correspondence procedure. • The “theory of body” module (ToBY) looks for objects that are self-propelled (animate). • Faces are located in animate stimuli. • Features such as the eyes and mouth are extracted to provide head orientation. • Animate visual trajectories are mapped to arm movements. Animate Objects Face/Eye Finder Arm Primitives ToBY Trajectory Formation Reaching / Pointing Visual Attention Pre-attentive filters f f f f Visual Input Visual input is processed by a set of parallel pre-attentive filters including skin tone, color saturation, motion, and disparity filters. The attention system combines the filtered images using weights that are influenced by high-level task constraints. The attention system also incorporates a habituation mechanism and biases the robot’s attention based on the attention of the instructor. Future Research More Complex Mimicry One future direction for our work is to look at more complex forms of social learning. We will both explore a wider range of tasks and ways to sequence together learned actions into more complex behaviors, and we will work on building systems that imitate, that is, they follow the intent of the action, not the form of the action. The attention system produces a set of target points for each frame in the image sequence. These points are connected across time by the multi-hypothesis tracking algorithm developed by Cox and Hingorani. The system maintains multiple hypothesis for each possible trajectory, which allows for ambiguous data to be resolved by further information. Delay Management (pruning, merging) Generate Predictions Generate k-best Hypotheses Matching Feature Extraction The “theory of body” module (ToBY) is a set of agents, each of which incorporates a rule of naïve physics. These rules estimate how objects move under natural conditions. In the images Moving hand Rolling chair “Animate” chair Understanding Self We will also exploring ideas about how to build representations of the robot’s own body, and the actions that it is capable of performing. The robot should recognize it’s own arm as it moves through the world, and even be able to recognize it’s own movements in a mirror by the temporal correlation. shown above, trajectories that obey these rules are judged to be inanimate (shown in red), while those that display self-propelled movement (like the moving hand or the “animate” chair being pushed with a rod) are judged animate (green). The attention of the instructor is monitored by a system that finds faces (using a color filter and shape metrics), orients to the instructor, and extracts salient features at a distance of 20 feet. New Head and Hands Trajectories are selected based on the inherent object saliency, the instructor’s attentional state, and the animacy judgment. These trajectories are mapped from visual coordinates to a set of primitive arm postures. The trajectory can then be used to allow the robot to perform object-centered actions (such as pointing) or process-centered actions (such as repeating the trajectory with its own arm). New Hands