Download

1 / 36
360 likes | 377 Views
Understand the compressed storage of Web graphs using directed graph definitions and explore document compression techniques with algorithms like LZ77. Discover properties like locality and similarity in Web graph structures.

E N D
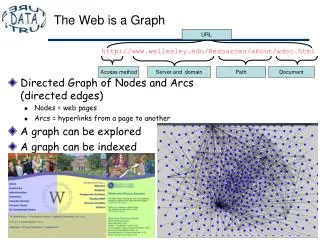
Definition Directed graph G = (V,E) • V = URLs, E = (u,v) if u has an hyperlink to v Isolated URLs are ignored (no IN & no OUT) Three key properties: • Skewed distribution: Pb that a node has x links is 1/xa, a ≈ 2.1
The In-degree distribution Altavista crawl, 1999 WebBase Crawl 2001 Indegree follows power law distribution This is true also for: out-degree, size of CC and SCC,...
Definition Directed graph G = (V,E) • V = URLs, E = (u,v) if u has an hyperlink to v Isolated URLs are ignored (no IN, no OUT) Three key properties: • Skewed distribution: Pb that a node has x links is 1/xa, a ≈ 2.1 • Locality: usually, most of the hyperlinks from URL u point to other URLs on the same host of u (about 80%). • Similarity: if URLs u and v are close in lexicographic order, then they tend to share many hyperlinks
A Picture of the Web Graph j i 21 millions of pages, 150millions of links
URL-sorting Berkeley Stanford
Reference copy-back are small (e.g. 8) Copy-lists: Similarity & Locality Uncompressed adjacency list Adjacency list with copy lists (similarity) Each bit of the copy-list informs whether the corresponding successor of y is also a successor of the reference x; The reference index is the one in[0,W] that gives the best compression. .
This is a Java and C++ lib Called WebGraph ≈3 bits/edge Copy-blocks = RLE(Copy-list) Adjacency list with copy lists. Adjacency list with copy blocks (RLE on bit sequences) 1,3 2 The first bit specifies the first copy block Each RLE-length is decremented by one for all blocks The last block is omitted (we know the length from Outd); More on extra nodes, but not here !! .
What about other graphs? A directed graph G = (V,E) not necessarily satisfy Web properties above Apache Giraph is an iterative graph processing system built for high scalability. It is currently used at Facebook. Giraph originated as the open-source counterpart to Pregel, the graph processing architecture developed at Google (2010). Both systems are inspired by the Bulk Synchronous Parallel model of distributed computation.
Compression of documents Paolo Ferragina Dipartimento di Informatica Università di Pisa
Document Compression Dictionary-based compressors and gzip
LZ77 Algorithm’s step: • Output <dist, len, next-char> • Advance by len + 1 A buffer “window” has fixed length and moves a a c a a c a b c a a a a a a a c <6,3,a> Dictionary(all substrings starting here) a c a a c a a c a b c a a a a a a c <3,4,c>
(3,3,a) a a a a c c a a a a c c a a b b c c a a b b a a a a a a c c (0,0,a) a c a a c a b c a b a a a c a (1,1,c) a a a a c c a a a a c c a a b b c c a a b b a a a a a a c c (3,4,b) a a a a c c a a a a c c a a b b c c a a b b a a a a a a c c (1,2,c) a a a a c c a a a a c c a a b b c c a a b b a a a a a a c c within W Example: LZ77 with window Window size = 6 Longest match Next character Gzip -1…-9
Which is faster in decompression among gzip -1…-9 ? LZ77 Decoding Decoder keeps same dictionary window as encoder. • Finds substring <len,dist,char> in previously decoded text • Inserts a copy of it What if len > dist ? (overlap with text to be compressed) • E.g. seen = abcd, next codeword is <2,9,e> for (i = 0; i < len; i++) out[cursor+i] = out[cursor-d+i] • Output is correct: abcdcdcdcdcdce
Document Compression Can we use simpler copy-detectors?
Simple compressors: too simple? • Move-to-Front (MTF): • As a freq-sorting approximator • As a caching strategy • As a compressor • Run-Length-Encoding (RLE): • FAX compression
Move to Front Coding Transforms a char sequence into an integersequence, that can then be var-length coded • Start with the list of symbols L=[a,b,c,d,…] • For each input symbol s • output the position of s in L [>=1] • move s to the front of L • L=[a,b,c,l] and S = cabala mtf(S) = 3 2 3 2 4 2 Properties: • It is a dynamic code, with memory
MTF is 2-optimal • Lopt is the optimal (static) list whose items are sorted by decreasing probability • x(i) is the item in position i of Lopt • Let P(i) the probability that x(i) is accessed • E[Lopt] = average access cost to the optimal list, by assuming that «access» is via a scan of Lopt • E[Lmtf] = average access cost to the MTF list THEO. It is E[Lmtf] ≤ 2 * E[Lopt] OBS. MTF does not know the underlying P(), so its choice about L’s ordering could be disastrous (e.g. Take L sorted by increasing P).
Proof: MTF is 2-optimal E[Lopt] = ∑i=1,… P(x(i)) * i Notice that x(i) has a dynamic position in Lmtf as accesses are performed on its items. So it is better to talk about average position of x(i) in Lmtf E[pos of x(i) in Lmtf ] = E[numb. of elems that precede x(i) in Lmtf ] = 1 + ∑j<>i P(x(j) precedes x(i) in Lmtf ] = 1 + ∑j<>i P(x(j)) / (P(x(j))+P(x(i))) Idea: Given the way MTF works, we have that P(x(j)) actually coincides with prob x(j) moves to the front (good) P(x(i)) actually coincides with prob x(i) moves to the front (bad) 1-P(x(j))-P(x(i)) = prob others move to the front (not interesting)
Proof: MTF is 2-optimal So we can expand the previous formula: E[Lmtf] = ∑i=1,… P(x(i)) * E[pos of x(i) in Lmtf] = = ∑i=1,… P(x(i)) * (1 + ∑j<>i P(x(i))*P(x(j)) / (P(x(i))+P(x(j)))) By simmetry we can group the items by restricting to pairs (i,j) such that j<i = ∑i=1,… P(x(i)) * (1 + 2 * ∑j<i P(x(i))*P(x(j)) / (P(x(i))+P(x(j)))) Since P(x(j)) / (P(x(i))+P(x(j)))) < 1 we can write ≤ 1 + 2 * ∑i=1,… ∑j<i P(x(i)) ≤ 1 + 2 * ∑i=1,… P(x(i)) (i-1) ≤ 1 + 2 * ∑i=1,… i * P(x(i)) - 2 * ∑i=1,… P(x(i)) ≤ 1 + 2* E[Lopt] – 2 < 2* E[Lopt]
Run Length Encoding (RLE) If spatial locality is very high, then abbbaacccca => (a,1),(b,3),(a,2),(c,4),(a,1) In case of binary strings just numbers and one bit Properties: • It is a dynamic code, with memory
Document Compression Burrows-Wheeler Transform and bzip2
# mississipp i i #mississipp i ppi#mississ i ssippi#miss i ssissippi# m Sort the rows m ississippi# T p i#mississi p p pi#mississ i s ippi#missi s s issippi#mi s s sippi#miss i s sissippi#m i The Burrows-Wheeler Transform (1994) Let us given a text T = mississippi# F L mississippi# ississippi#m ssissippi#mi sissippi#mis issippi#miss ssippi#missi sippi#missis ippi#mississ ppi#mississi pi#mississip i#mississipp #mississippi
A famous example Much longer...
L is highly compressible Algorithm Bzip : • Move-to-Front coding of L • Run-Length coding • Statistical coder Compressing L seems promising... Key observation: • L is locally homogeneous • Bzip vs. Gzip: 20% vs. 33%, but it is slower in (de)compression !
SA L BWT matrix 12 11 8 5 2 1 10 9 7 4 6 3 #mississipp i#mississip ippi#missis issippi#mis ississippi# mississippi pi#mississi ppi#mississ sippi#missi sissippi#mi ssippi#miss ssissippi#m i p s s m # p i s s i i Given SA and T, we have L[i] = T[SA[i]-1] Thisisone of the mainreasons for the number of pubblicationsspurred in ‘94-’10 on Suffix Array construction How to compute the BWT ? We said that: L[i] precedes F[i] in T #mississipp i#mississip ippi#missis issippi#mis ississippi# mississippi pi#mississi ppi#mississ sippi#missi sissippi#mi ssippi#miss ssissippi#m L[3] = T[ 8 - 1 ]
Rankchar(pos) and Selectchar(pos) are key operations nowadays i ssippi#miss Can we map L’s chars onto F’s chars ? i ssissippi# m ... Need to distinguishequal chars... m ississippi# p i#mississi p p pi#mississ i s ippi#missi s s issippi#mi s s sippi#miss i s sissippi#m i Take two equal L’s chars Rotate rightward their rows Same relative order !! A useful tool: L F mapping F L unknown # mississipp i i #mississipp i ppi#mississ
Two key properties: 1. LF-array maps L’s to F’s chars 2. L[ i ] precedes F[ i ] in T i ssippi#miss i ssissippi# m m ississippi# p p i T = .... # i p i#mississi p p pi#mississ i s ippi#missi s s issippi#mi s s sippi#miss i s sissippi#m i The BWT is invertible F L unknown # mississipp i i #mississipp i ppi#mississ Reconstruct T backward: Severalissuesaboutefficiency in time and space
# at 16 Mtf = [i,m,p,s] Alphabet |S|+1 An encoding example T = mississippimississippimississippi L = ipppssssssmmmii#pppiiissssssiiiiii Mtf = 131141111141141 411211411111211111 Bin(6)=110, Wheeler’s code RLE1 = 03141041403141410210 Bzip2-output = 16 the original Mtf-list (i,m,p,s) [also S] Statistical code for |S|+1 symbols