Download

1 / 58
580 likes | 719 Views
V-IRAM Compiler Benchmarks and Applications. Adam Janin, David Judd, Christoforos Kozyrakis, David Martin, Thinh Nguyen, Randi Thomas, David Patterson, Kathy Yelick. Overview of V-IRAM Benchmarks. Hand-Coded Benchmarks Media Kernels FFT H.263 Video Encoder Application

E N D
V-IRAM Compiler Benchmarks and Applications Adam Janin, David Judd, Christoforos Kozyrakis, David Martin, Thinh Nguyen, Randi Thomas, David Patterson, Kathy Yelick
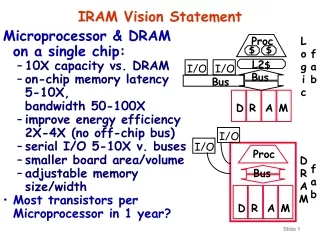
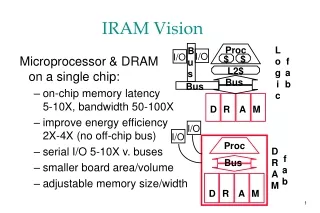
Overview of V-IRAM Benchmarks • Hand-Coded Benchmarks • Media Kernels • FFT • H.263 Video Encoder Application • Compiled Benchmarks • Matrix vector multiplication and VIRAM addressing • Floating point benchmarks • Integer benchmarks • Underway • Speech Application (Janin poster) • Scientific (DOE) Applications (Li and Oliker poster) • Data-intensive (DARPA DIS) Benchmarks (Gaeke)
Hand-Coded Applications Update • Image processing kernels (old FPU model) • Note BLAS-2 performance
Media Kernel Comparisons • All numbers in cycles/pixel • VIRAM uses 4 lanes, 1 sub-bank per bank • MMX and VIS results assume all data in L1 cache
FFT: Uses In-Register Permutations Without in-register permutations
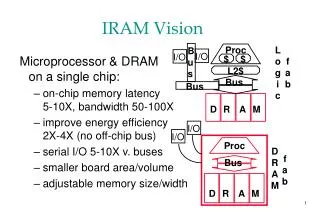
2 lanes, 4 MB 1.6 Gops Scaling number of lanes for performance, energy, area Number of DRAM banks may scale independently e.g., 16 banks rather than 8 May also scale up to 8 lanes Single executable file used across lane scaling experiments Scalable Design 4 lanes, 8 MB 3.2 Gops (32-bit) 1 lane, 2 MB .8 Gops
Virtual Processors (vl) VP0 VP1 VPvl-1 vr0 vr1 Data Registers vr31 vpw Vector Architectural State • Number of VPs given by the Vector Length register vl • Width of each VP given by the register vpw • vpw is one of {8b,16b,32b,64b} • Maximum vector length is given by a read-only register mvl • mvl depends on implementation and vpw: {128,128,64,32} in VIRAM-1
VIRAM Compiler • Based on the Cray’s production compiler • Challenges: • narrow data types and scalar/vector memory consistency • Advantages relative to media-extensions: • powerful addressing modes and ISA independent of datapath width Frontends Optimizer Code Generators C T3D/T3E Cray’s PDGCS C++ C90/T90/SV1 Fortran95 SV2/VIRAM
Compiler Challenges • Can compiled code effectively use VIRAM design? • Is on-chip DRAM bandwidth sufficient? • How well do multimedia applications vectorize? • Does VIRAM’s model of variable width data (VPW) fit into a compilation framework?
Source vector Matrix Assume row layout Destination vector Matrix-Vector Multiplication • Matrix vector multiply • dot: 2 vloads, (both unit stride + a reduction) • saxpy: 2 vloads, 1 vstore (2 strided + 1 unit) • Vector matrix multiply (= mvm with column layout) • saxpy: 2 vloads, 1 vstore (all unit stride) • Sparse matrix-vector multiply • dot: 3 vloads (1 indexed, 2 unit + reduction) • saxpy: 3 vloads, 1 vstore (2 indexed, 2 unit) (column layout)
Matrix Vector Multiplication • Performance of various source optimizations Column layout mvm = row layout vmm Column performance ~= peak
Comparison of MVM Performance • Double precision floating point • compiled for VIRAM (note: chip only does single) • hand- or Atlas-optimized for other machines 100x100 matrix • As matrix size increases, performance: • drops on cache-based designs • increases on vector designs • but 64x64 about 20% better on VIRAM MFLOPS
Sparse MVM Performance • Performance is matrix-dependent: lp matrix • compiled for VIRAM using “independent” pragma • sparse column layout • Sparsity-optimized for other machines • sparse row (or blocked row) layout MFLOPS
Generating Code for Variable VPW • Strategy: vectorizer determines minimum correct vpw for each loop nest • Vectorizer assumes vpw=64 initially • At end of vectorization, discard vectorized copy of loop if greatest width encountered is less than 64 and start vectorization over with new vpw. • Code gen checks vpw for each loop nest. • Limitation: a single loop nest will run at the speed of the widest type. • Reason: simplicity & performance of the common case • No attempt to split/combine loops based on vpw
Media Benchmarks • Mostly from U Toronto’s benchmark suite • 8-bit data, 16-bit operations • Colorspace: strided loads/stores • Composition: unit stride • Convolve: strided • Mixed 16 and 32-bit integer • Detect • Decrypt • 32-bit Floating point • FIR filter • SAXPY 64: 64 element • SAXPY 1K: 1024 element • matmul: matrix multiplication
Integer Benchmarks • Strided access important, e.g., RGB • narrow types limited by address generation • Outer loop vectorization and unrolling used • helps avoid short vectors • spilling can be a problem • Tiling could probably help
Floating Point DSP Benchmarks • Performance is competitive with hand-coding • Vector length is important (e.g., saxpy) • but multiple vectors is fine (e.g., matmul)
Conclusions • VIRAM ISA shows high performance on compiled code • competitive with modern processors • limitations are address generation for strided and indexed memory operations • Compiler effectively uses variable width data • allows media applications to vectorize • performance scales with inverse data width • Future compiler work • Fixed point support • Better register allocation
Performance Summary • Performance of compiled code is generally good • matmul and saxpy meet or beat hand-coded • 3 addressing modes very useful • Limitations to performance • Dependencies or inadequate compiler analysis • Inadequate memory bandwidth • Lack of address generators • Short vectors • Future compiler work • Tiling • Fixed point support • Better register allocation
Compiled matrix-vector multiplication: 2 Flops/element • Easy compilation problem; stresses memory bandwidth • Compare to 304 Mflops (64-bit) for Power3 (hand-coded) • Performance scales with number of lanes up to 4 • Need more memory banks than default DRAM macro for 8 lanes
Outline • Why vectors for IRAM? • Including media types • The virtual lane model • Virtual processor width • Limitations to performance • Dependencies or inadequate compiler analysis • Inadequate memory bandwidth • Lack of address generators • Short vectors • Comparisons to other architectures • Conclusions
Matrix-Vector Multiply • Scaling Matrix-Vector Multiplication
Performance on Media Benchmarks • Using compiled code: 1, 2, 4, and 8 lanes
Compiled matrix-vector multiplication: 2 Flops/element • Easy compilation problem; stresses memory bandwidth • Compare to 304 Mflops (64-bit) for Power3 (hand-coded) • Performance scales with number of lanes up to 4 • Need more memory banks than default DRAM macro for 8 lanes MFLOPS
Compiling Media Kernels on IRAM • The compiler generates code for narrow data widths, e.g., 16-bit integer • Compilation model is simple, more scalable (across generations) than MMX, VIS, etc. • Strided and indexed loads/stores simpler than pack/unpack • Maximum vector length is longer than datapath width (256 bits); all lane scalings done with single executable
Vector Vs. SIMD: Example • Simple image processing example: • conversion from RGB to YUV Y = [( 9798*R + 19235*G + 3736*B) / 32768] U = [(-4784*R - 9437*G + 4221*B) / 32768] + 128 V = [(20218*R – 16941*G – 3277*B) / 32768] + 128
VIRAM Code (22 instructions) RGBtoYUV: vlds.u.b r_v, r_addr, stride3, addr_inc # load R vlds.u.b g_v, g_addr, stride3, addr_inc # load G vlds.u.b b_v, b_addr, stride3, addr_inc # load B xlmul.u.sv o1_v, t0_s, r_v # calculate Y xlmadd.u.sv o1_v, t1_s, g_v xlmadd.u.sv o1_v, t2_s, b_v vsra.vs o1_v, o1_v, s_s xlmul.u.sv o2_v, t3_s, r_v # calculate U xlmadd.u.sv o2_v, t4_s, g_v xlmadd.u.sv o2_v, t5_s, b_v vsra.vs o2_v, o2_v, s_s vadd.sv o2_v, a_s, o2_v xlmul.u.sv o3_v, t6_s, r_v # calculate V xlmadd.u.sv o3_v, t7_s, g_v xlmadd.u.sv o3_v, t8_s, b_v vsra.vs o3_v, o3_v, s_s vadd.sv o3_v, a_s, o3_v vsts.b o1_v, y_addr, stride3, addr_inc # store Y vsts.b o2_v, u_addr, stride3, addr_inc # store U vsts.b o3_v, v_addr, stride3, addr_inc # store V subu pix_s,pix_s, len_s bnez pix_s, RGBtoYUV
RGBtoYUV: movq mm1, [eax] pxor mm6, mm6 movq mm0, mm1 psrlq mm1, 16 punpcklbw mm0, ZEROS movq mm7, mm1 punpcklbw mm1, ZEROS movq mm2, mm0 pmaddwd mm0, YR0GR movq mm3, mm1 pmaddwd mm1, YBG0B movq mm4, mm2 pmaddwd mm2, UR0GR movq mm5, mm3 pmaddwd mm3, UBG0B punpckhbw mm7, mm6; pmaddwd mm4, VR0GR paddd mm0, mm1 pmaddwd mm5, VBG0B movq mm1, 8[eax] paddd mm2, mm3 movq mm6, mm1 paddd mm4, mm5 movq mm5, mm1 psllq mm1, 32 paddd mm1, mm7 punpckhbw mm6, ZEROS movq mm3, mm1 pmaddwd mm1, YR0GR movq mm7, mm5 pmaddwd mm5, YBG0B psrad mm0, 15 movq TEMP0, mm6 movq mm6, mm3 pmaddwd mm6, UR0GR psrad mm2, 15 paddd mm1, mm5 movq mm5, mm7 pmaddwd mm7, UBG0B psrad mm1, 15 pmaddwd mm3, VR0GR packssdw mm0, mm1 pmaddwd mm5, VBG0B psrad mm4, 15 movq mm1, 16[eax] MMX Code (part 1)
paddd mm6, mm7 movq mm7, mm1 psrad mm6, 15 paddd mm3, mm5 psllq mm7, 16 movq mm5, mm7 psrad mm3, 15 movq TEMPY, mm0 packssdw mm2, mm6 movq mm0, TEMP0 punpcklbw mm7, ZEROS movq mm6, mm0 movq TEMPU, mm2 psrlq mm0, 32 paddw mm7, mm0 movq mm2, mm6 pmaddwd mm2, YR0GR movq mm0, mm7 pmaddwd mm7, YBG0B packssdw mm4, mm3 add eax, 24 add edx, 8 movq TEMPV, mm4 movq mm4, mm6 pmaddwd mm6, UR0GR movq mm3, mm0 pmaddwd mm0, UBG0B paddd mm2, mm7 pmaddwd mm4, pxor mm7, mm7 pmaddwd mm3, VBG0B punpckhbw mm1, paddd mm0, mm6 movq mm6, mm1 pmaddwd mm6, YBG0B punpckhbw mm5, movq mm7, mm5 paddd mm3, mm4 pmaddwd mm5, YR0GR movq mm4, mm1 pmaddwd mm4, UBG0B psrad mm0, 15 paddd mm0, OFFSETW psrad mm2, 15 paddd mm6, mm5 movq mm5, mm7 MMX Code (part 2)
pmaddwd mm7, UR0GR psrad mm3, 15 pmaddwd mm1, VBG0B psrad mm6, 15 paddd mm4, OFFSETD packssdw mm2, mm6 pmaddwd mm5, VR0GR paddd mm7, mm4 psrad mm7, 15 movq mm6, TEMPY packssdw mm0, mm7 movq mm4, TEMPU packuswb mm6, mm2 movq mm7, OFFSETB paddd mm1, mm5 paddw mm4, mm7 psrad mm1, 15 movq [ebx], mm6 packuswb mm4, movq mm5, TEMPV packssdw mm3, mm4 paddw mm5, mm7 paddw mm3, mm7 movq [ecx], mm4 packuswb mm5, mm3 add ebx, 8 add ecx, 8 movq [edx], mm5 dec edi jnz RGBtoYUV MMX Code (pt. 3: 121 instructions)
IRAM Status • Chip • ISA has not changed significantly in over a year • Verilog complete, except SRAM for scalar cache • Testing framework in place • Compiler • Backend code generation complete • Continued performance improvements, especially for narrow data widths • Application & Benchmarks • Handcoded kernels better than MMX,VIS, gp DSPs • DCT, FFT, MVM, convolution, image composition,… • Compiled kernels demonstrate ISA advantages • MVM, sparse MVM, decrypt, image composition,… • Full applications: H263 encoding (done), speech (underway)
VIRAM Tools • vas: assembler • vdis: disassembler • vsim-isa: simulator • vsim-db: debugger • vsim-p: performance simulator • vsim-sync:memory consistency simulator
Compiler Testing • C regression test suite (commercial test suite) • Scalar emphasis, C conformance • All tests pass except: • Small numerical differences due to lack on 128 f.p. support • C++ test suite • 1167 of 1183 tests execute correctly. • 12 failures in compilation: “undefined variables” • 4 failures in execution: bad answers
Compiler Testing • Vector regression test suites (CRAY) • Specifically tests for vectorization • Compares vector and scalar results • Easy to isolate problems • “vector” status: • 59 of 62 tests pass • Some minor numerical differences • 1 bad answer, 2 integer overflow • “vector4” status • 163 of 165 tests execute correctly • 1 bad anwer, 1 illegal use of vector inst.
Kernel Performance: mvmmatrix-vector multiplication 64x64, 32 bit floating pt.
Mods to mvm code /* Original code mvm.c */ /* Modified code */ void mvm (float * A, void mvm (float * restrict A, float * X, float * restrict X, float * Y, float * restrict Y, int n, int n, int acol ) { int acol ) { int i,j; int i,j; float x_elem < if ( n <= 64 ) { if ( n <= 64 ) { for (i = 0; i < n; i++) { for (i = 0; i < n; i++) {#pragma shortloop for (j = 0; j < n; j++) { for (j = 0; j < n; j++) { Y[j] += A[j*acol+i] * x_elem; Y[j] += A[j*acol+i] * X[i]; } } } } } }} }
Kernel performance: mm_mulmatrix –matrix multiplication • 64x64x64, 32 bit float, 1.6 gigaflop theoretical peak
Kernel performance: saxpy • 32 bit floating point ops
Kernel performance: motion_estimate 32 bit integer ops, finding the minimum sum of absolute differences for a reference block and a region in an image. *No improvement because of spilling.
Dongarra loops • 100 loops to test compiler vectorization capability • Rewritten in C by Cray (?) • vcc vectorizes 74 loops • vcc partially vectorizes 3 loops • vcc conditionally vectorizes 3 loops • 1 loop not vectorized because vector sin/cos not currently available on viram. • 19 other loops not vectorized • Data provided by Sam Williams
Features Remaining: • Support version 3 isa and version 4 isa: • Isa changes required by Mips Inc. scalar core • Performance simulator only supports “old”isa • Finish sync support • take advantage of Cray implementation • VIRAM machine “target” • Allow easier maintainence of frontend and optimizer mods for viram • User documentation • Summary of differences w/Cray compiler • Useful options, hints for vector code
Performance Features Remaining • Additional tuning: instruction scheduler • Support new SV2 inliner for C/C++ • Shortloop enhancements • Reduce spilling • Scheduler concern with registers • Ordering of blocks for register assignment within “priority groups” • Special vector registers carried across calls • Loop unrolling for vector loops • Tune for key benchmarks
Other Future Compiler Features ? • Support for speculative execution • Compiler extensions for fixed point hardware • Support for vector functions; vector mlib
Summary • vcc is a reasonably robust compiler for VIRAM • Performance on kernels is good w/appropriate directives, some effort for optimum vectorization • Need to prioritize remaining work
Codegen/optimizer issues for VIRAM • Variable virtual processor width (VPW) • Variable maximum vector register length (MVL) • Vector flag registers treated as 1 bit wide vector register • Multiple base, incr, stride regs. + autoincrement • Fixed point arithmetic (saturating add, etc.) • Memory consistency • New vector instructions not available on SV2
Generating Code for Variable MVL • Maximum vector length is not specified in IRAM ISA. • However, compiler assumes mvl at compile time • mvl based on vpw • mvl assumption dependent on VIRAM-1 hardware implementation • Recompiling required for future hardware versions if mvl changes • MVL knowledge useful for code gen and vectorizer: • register spilling • short loop vectorization • length-dependent vectorization ( and may eliminate safe vector length computation at run time) for (i = 0; i < n; i=++) a[i] = a[i+32]
Why Vectors? • Utilizes on-chip bandwidth of IRAM • parallelism within instructions • Efficient architecture for vectorizable code • avoids area, power, and design of reorder logic • low instruction decode overhead • Multimedia algorithms are vectorizable • e.g., vectorize across pixels in an image • Scales easily across chip generations • e.g., 32-way parallelism in instruction can be implemented by 1, 2, 4, 8-way • Leverages well-known compiler technology