Download

1 / 28
300 likes | 509 Views
Procesadores Vectoriales y Matriciales. Unidad 3. Arquitecturas SIMD. Docente: Ing. José Díaz Chow. Taxonomía de Flynn SISD: Flujo simple de instrucciones , flujo simple de datos . SIMD: Flujo simple de instrucciones , flujo de múltiples datos .

E N D
Procesadores Vectoriales y Matriciales Unidad 3. Arquitecturas SIMD Docente: Ing. José Díaz Chow
Taxonomía de Flynn • SISD: Flujo simple de instrucciones, flujo simple de datos. • SIMD: Flujo simple de instrucciones, flujo de múltiplesdatos. • MISM: Flujo de múltiplesinstrucciones, flujo simple de datos. • MIMD: Flujo de múltiplesinstrucciones, flujo de múltiplesdatos. Recordemos …
Explicar las necesidades que propiciaron la aparición de las Arquitecturas Vectoriales y Matriciales, estableciendo diferencias en el enfoque y solución que implementa cada una de ellas. • Identificar el tipo y nivel de paralelismo alcanzado en procesadores vectoriales y matriciales. • Explicar los tipos de Arquitecturas SIMD, tipo y nivel de paralelismo alcanzado en cada una de ellas. Objetivos
Limitaciones de desempeño en el campo de la computación científica. • Necesidad de procesar gran volumen de información. • Necesidad de procesar vectores y Matrices, no solo escalares. Introducción
Algoritmossecuenciales para cálculovectorial. • Ejemplo: Multiplicación de Matrices: C[] = A[] x B[] - Algoritmocostoso: O(n3). FOR I = 1 TO N FOR J=1 TO M C[I,J] = 0.0 FOR K=1 TO L C[I,J] = C[I,J]+A[I,K]*B[K,J] END FOR END FOR END FOR t N Introducción
Colección o arreglo de datos. • Almacenados en celdas contiguas en la memoria. • Independencia de datos (operación en elemento [i, j] no depende de resultado en [i-1, j-1]). • Una misma operación sobre todo un conjunto de datos. Caracteristicas
f1: V V (VSQRT, VSIN, VCOS ) • f2: V E (VSUM:Sumatoriade elementos, VMAX, VMIN) • f3: V x V V (VADD, VMP:Multiplicaciónde vectores o matrices) • f4: V x E V (SMUL:Escalacióndel vector, SADD:Desplazamiento) • f5: V x V E (SMP:Productopunto de vectores) Operaciones
Manejo de operandos vectoriales y escalares • Algoritmos idóneos al cálculo vectorial: múltiples datos operados a la vez. • Ejecución a alta velocidad: Transferencia desde memoria a alta velocidad. Exigencias
Procesadores Vectoriales • Utilizaron el beneficio de los cauces para acelerar el rendimiento de cálculo vectorial. • Procesadores Matriciales • Implementación de retículas de unidades de ejecución denominadas EP (Elementos de Procesamiento) que pueden trasladar datos entre la memoria y otros EPs, y realizar operaciones con estos datos, ya sea síncrona o asincronamente. Soluciones
Inicios de 1960: Proyecto Salomon en Westinghouse. • 1 CPU coordinando múltiples ALUs • Nunca construido • 1972: Illiac IV en la IU@Urbana : PA • Meta: 1 GFlop con 256 EP • Logrado: 100MFlop con 64 EP • Usado en cálculos de dinámica de fluidos. • Demostró la eficacia de los SIMD en cálculos intensivos con matrices. Implementaciones
Mediados de los 70: CDC STAR-100 y Texas Instruments Advanced Scientific Computer TI-ASC. • Procesadores vectoriales • Aprovechamiento de la segmentación • Escalaridad (cada cauce ~ 20 MFlops) • Máquinas Memoria-Memoria • Mediados 70: Cray-1. • Supercomputador vectorial (80 a 240 Mflops) • Máquina Registro a Registro • Encadenamiento de vectores • Enmascaramiento de vectores • 64 registros vectoriales de 64 palabras Implementaciones
Finales 70: Supercomputadoras Japonesas Vectoriales • Fujitsu, Hitachi y NEC • Máquinas Registro a Registro • Rendimiento similar al Cray pero menor tamaño. • Finales 70: FPS ProcessorArray asociado. • ProcessorArray asociado para minicomputadoras. • Finales 70 y 80’s: Cray-2, Cray X-MP y Cray Y-MP • Cray se mantiene como lider. • Migración de Vector Processor – ProcessorArrays –Multiprocesadores. Implementaciones
Otras formas de computación SIMD • Objetivo: Reducción del BW requerido por ProcessorArray. • WaveFrontProcessors • Principio de disparo y expansión. • Procesamiento de señales: DSP, Multimedia • SystolicProcessors • Cauce reticular • AssociativeProcessors • Basado en memoria asociativa • Operación aplicada a coincidencias. Implementaciones
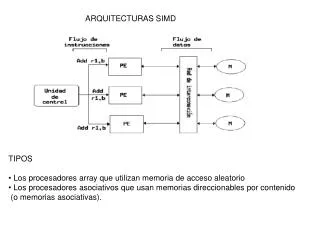
ProcesadoresVectoriales • ArquitecturasMemoria a Memoria • ArquitecturasRegistro a Registro • ProcesadoresMatriciales • Array Processor • Systolic Processors • Associative Processors • Wavefront Processors Arquitecturas SIMD
Las características y exigencias del procesamiento vectorial son propias para la ejecución segmentada. • Alto rendimiento con cauce lleno: resultados en cada ciclo. • Noriesgos estructurales, de datos o control. • Exigencias: flujo de datos de entrada y la recepción de salida. Procesadoresvectoriales
Arquitecturas que emplean cauces para procesamiento de vectores. • Operación del cauceequivalente a ciclocompleto. Reduce fetch, decode y control. Procesadoresvectoriales
Cauces aritméticos. • Entradas: Vector –Vector o Vector-Escalar. • Salida a Vector o Escalar. • Requieren registros especiales para control de la longitud del vector. • Formato especial de instrucción Procesadoresvectoriales
Esquemas o métodos de procesamiento para tratamiento de matrices • Procesamiento horizontal (filas: izq der) • Procesamiento vertical ( columnas: arriba abajo) • Procesamiento en bucle ( ciclos de sub-matrices ) • Tiempo de retardo de inicialización o preparación del cauce y de pasooflushing. t = tinicialización + tpaso ProcesadoresVectoriales
Entrada de datos/Recepción de salida a alta velocidad. • Desde Memoria (Requerido acceso rápido) • Usar registros vectoriales • Dos enfoques de implementación: • Supercomputadores Vectoriales • Procesadores vectoriales Asociados ProcesadoresVectoriales
Los operandos vectoriales residen en memoria. • Operaciónrequierecarga de operandos a cauces y almacenamiento de resultados a memoria al vuelo. • Se requieren memorias de alta velocidad, ideal: entregar un par de datos y recibir un resultado por ciclo. • Alto tiempo de preparación (típico ~20 ciclos) • Rendimiento favorecido con vectores grandes. VP M – M
Uso de memorias entrelazadas. • Una búsqueda + ráfaga de datos. • Capacidad de entregar y recibir múltiples datos. • Procesamiento en flujo continuo. VP M – M
Formato requiere especificar direcciones en memoria de los vectores y en algunas máquinas con palabras variables, el incremento o tamaño del elemento así como el tamaño del vector. VP M – M
Emplean banco de registros vectoriales. • Carga de Memoria a registros a alta velocidad. • Tamaño restringido de los registros vectoriales (64, 72, 128 elementos) • Ejecución en partes para vectores largos. VP R-R
Menor tiempo de preparación y en general menor ciclo de máquina que la M-M. • Mejor desempeño que M-M con vectores de longitud pequeña y mediana. • Capacidad de enmascaramiento de elementos de vectores. • Capacidad de encadenamiento de cauces. • Predominan sobre las M-M. VP R-R
Formatos de instrucción usan directamente registros vectoriales / escalares (Instrucciones de carga) o direcciones de memoria y registros a emplear. VP R-R
Múltiples unidades Vectoriales y Escalares. • Prefetch+ Ejecución simultánea de varias instrucciones Tratar potenciales dependencias de datos. VP R-R
Encadenamiento de cauces: ejecución paralela de varias instrucciones con dependencias R-D. VP R-R
Enmascaramiento de operacionesvectoriales. • Selección de quéelementos son sujetos de operación. • Luego de operación C[] vale: VP R-R