Download
1 / 22
220 likes | 899 Views
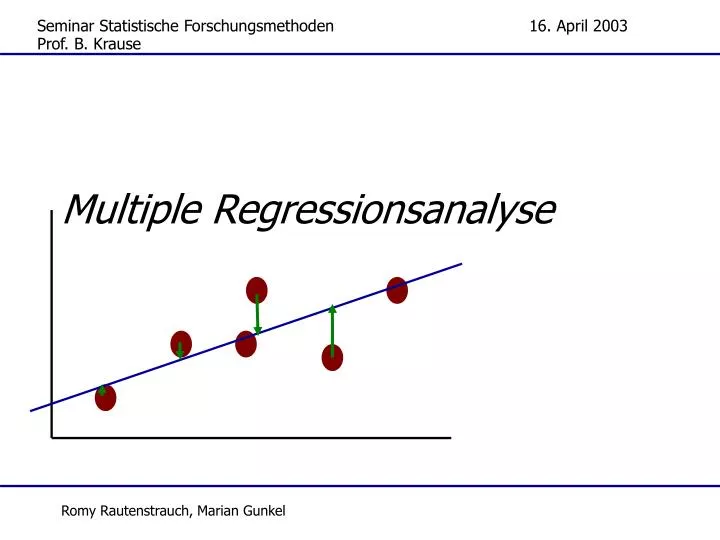
Multiple Regressionsanalyse. Prof. B. Krause. Inhalt. Einleitung – was ist das? Problemstellung – wozu braucht man das? Voraussetzungen – was braucht man? Vorgehensweise – wie macht man es?. Einleitung. Regressionsanalyse: Analyse von Zusammenhängen zwischen Variablen (X,Y)

E N D
Multiple Regressionsanalyse Prof. B. Krause Romy Rautenstrauch, Marian Gunkel
Inhalt • Einleitung – was ist das? • Problemstellung – wozu braucht man das? • Voraussetzungen – was braucht man? • Vorgehensweise – wie macht man es?
Einleitung • Regressionsanalyse: • Analyse von Zusammenhängen zwischen Variablen (X,Y) • Vorhersage der Y-Werte aus X-Werten • Versuch, die Y-Werte auf die X-Werte „zurückzuführen“ • Einfache lineare RA: • Betrachtung einer Zielgröße Y und einer Einflußgröße X • Multiple lineare RA: • Betrachtung einer Zielgröße Y und mehr als einer Einflussgröße X • kann daher mehr Varianz aufklären X1 Y X2
Problemstellung • Ziel: Analyse des stochastischen Zusammenhangs zwischen einer Zielgröße Y und mehreren Einflussgrößen Xi bei verbundenen Stichproben. (Variabilität von Y durch die Variabilitäten der Xi erklären) • stochastisch – gegenseitige Abhängigkeit • Anwendungen • Ursachenanalysen: Wie stark ist der Einfluss von X auf Y? • Wirkungsanalysen: Wie verändert sich Y bei Veränderung von X? • Zeitreihenanalysen: Wie verändert sich Y im Zeitverlauf? Prognose! • Testkonstruktion: Auswahl der Items für Test
Problemstellung • Vorteile: • Lineare Ansätze liefern eine hinreichend gute Anpassung an die Daten (vernünftig interpretierbar) • Lineare Ansätze sind i.d.R. mit geringem Rechenaufwand verbunden. • für die mehrfache Regressionsanalyse ist keine Varianzhomogenität gefordert. • die einzelnen Regressoren weisen unterschiedliche Variabilitäten auf. • die Varianz der Zielgröße wird nicht gleichmäßig durch die einzelnen Regressoren beeinflusst. • Um das zu vermeiden wird häufig eine Normierung der Zufallsgrößen durchgeführt, meist durch die Transformation in eine Standardnormalverteilung. • Entspricht einer Standard-RA (alle Varianzen=1).
Voraussetzungen • Prämissen des linearen Regressionsmodells sollten erfüllt sein • lineare Beziehung zwischen Regressand und Regressor (d.h. Veränderung in konstanten Relationen) • metrisches Datenniveau der Ziel- und der Einflussgrößen • wenn Zielgröße ordinal skaliert: Rangregressionsanalyse • wenn Zielgröße nominal skaliert: pro-bit-Analyse • Xm, Y und R normalverteilt • E (R) = 0; D² (R) minimal (Modellvollständigkeit) • D² (R) konst. (Homoskedastizität) • Cov (Xi; Ri) = 0
Vorgehensweise • Bestimmung des Ursache-Wirkungs-Modells • Regressionsfunktion schätzen • Gilt die Regressionsfunktion auch für die Grundgesamtheit? / Wie gut ist mein Modell (wieviel Varianz kann ich erklären)?
Vorgehensweise • Regressionsfunktion Y=b0+b1X • b0: absolutes Glied, das den Y-Wert für X=0 angibt • b1=ΔY/ΔX: Steigungsmaß b1, das die Neigung der Geraden bestimmt • Abweichungen durch Meßfehler, Beobachtungsfehler, andere Einflußgrößen...
Vorgehensweise • Beispiel: Welche Faktoren können unsere Prüfungsnote Y beeinflussen? • Modell: • konsumierter Wein und Mokka in der Lernzeit beeinflussen die Note • je mehr Wein und Mokka, desto bessere Note • X1: Menge der konsumierten Tassen Mokka in der Lernzeit • X2: Menge der konsumierten Gläser Wein in der Lernzeit Mokka=X1 Y= Note Wein=X2
Vorgehensweise b1 X1 Y X2 b2 • Formulierung des Ursache-Wirkungs-Modells Theoretisch: Empirisch: Beispiel: Note = b0 + b1 * Mokka +b2 * Wein β0 ist das konstante Glied (= nix trinken) βm partielle Regressionskoeffizienten (Einflußgewicht) X wird als fehlerfrei und additiv wirkend angenommen Y ist fehlerbehaftet R ist Vorhersagefehler, ist der Anteil an Y, der nicht durch die Regressionsgerade erklärt wird
Vorgehensweise • 2. Schätzen der Regressionsfunktion • Ziel: Modell bestmöglich an Daten anzupassen • Fehler R dabei möglichst minimal • Vorgehen: Methode der kleinsten quadratischen Abweichungen • Regressionsgerade soll in Punktwolke so liegen, dass Summe der quadrierten Abweichungen aller Werte von der Geraden so klein wie möglich ist.
Vorgehensweise • 2. Schätzen der Regressionsfunktion Formel: zur Minimierung werden die partiellen Ableitungen nach den einzelnen unbekannten Parametern gebildet • Einzelne Ableitungen werden gleich 0 gesetzt -> Gleichungssystem entsteht • Lösung des Gleichungssystems führt zu einzelnen bm
Vorgehensweise Beispiel: Nicht standardisiert: Note Y = 0,465+ 0,27* Mokka + 0,617 * Wein Standardisiert: Note Y = 0,518* Mokka + 0,781 * Wein a. Abhängige Variable: Note
Vorgehensweise • Prüfung der Regressionsfunktion durch • das Bestimmtheitsmaß • Prüfung der Regressionskoeffizienten bm • Prüfung auf Verletzung der Prämissen
Vorgehensweise • Prüfung der Regressionsfunktion durch das Bestimmtheitsmaß = prozentualer Anteil der Varianz der Y-Werte, der aufgrund der X-Werte erklärbar ist • Sagt aus, wie gut sich die Regressionsfunktion an die empirische Punktverteilung anpasst (bzw. wieviel Restschwankung übrigbleibt) Beispiel: Einflußvariablen: (Konstante), Wein, Mokka
Vorgehensweise • Prüfung der Regressionsfunktion durch das Bestimmtheitsmaß Signifikanzprüfung: • 1. Nullhypothese H0: B=0 • n= Anzahl der Beobachtungsdaten • m= Anzahl der βm • 2. Nullhypothese H0: βm1=β2 =...=0 • Werte von TG sind F-verteilt mit df1=m und df2= n-m-1 • H0 wird abgelehnt, falls TG>F(1- , df1, df2) • ist das Modell insgesamt unbrauchbar, erübrigen sich die restlichen Überprüfungen!
Vorgehensweise • Prüfung der Regressionskoeffizienten bm • Prüfung, ob und wie gut einzelne Variablen des Regressionsmodells zur Erklärung der abhängigen Variablen Y beitragen • Maße: T-Wert und Konfidenzintervall der Regressionskoeffizienten • T-Wert:Nullhypothese H0: βm=0 bei Gültigkeit vonH0 wirdβm=0 • Werte von TG sind t-verteilt mit df= n-m-1 • H0 wird abgelehnt, falls TG>t(1- , df) • Aussage: ist der Einfluss der einzelnen Regressoren Xm signifikant?
Vorgehensweise • Prüfung der Regressionskoeffizienten bm • Konfidenzintervall: • gibt an, in welchem Bereich der wahre Regressionskoeffizient mit einer bestimmten festgelegten Vertrauenswahrscheinlichkeit liegt Beispiel:
Zusätzliches • Nichtlineare RA, Quasilineare RA • Ziel: nicht lineare Zusammenhänge bestimmen Beispiel: die Reproduzierbarkeit von Gedächtnisinhalten nimmt im Verlauf der Zeit nicht linear, sondern exponentiell ab
Zusätzliches Alternative Bezeichnungen der Variable
Literatur • Krause, B. / Metzler, P. (1988). Angewandte Statistik (2. Auflage) Berlin: VEB Deutscher Verlag der Wissenschaften • Backhaus, K. et al. (1987). Multivariate Analysemethoden. Berlin: Springer • Schilling, O. (1998). Grundkurs Statistik für Psychologen. München: Fink