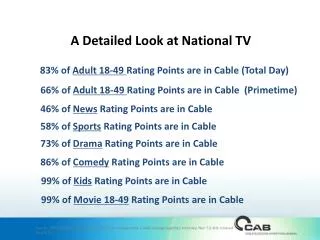
Download

1 / 28
280 likes | 293 Views
Explore the cycle count and performance issues of the DC Removal algorithm on TigerSHARC processor, identifying stalls and optimizing operations for improved efficiency.

E N D
Detailed look at the TigerSHARC pipeline Cycle counting for COMPUTE block versions of the DC_Removal algorithm
To be tackled today • Expected and actual cycle count for Compute Block version of DC_Removal algorithm • Understanding why the stalls occur and how to fix. • Understanding some operations “first time into function” – cache issues? DC_Removal algorithm performance
Set up timeIn principle 1 cycle / instruction 2 + 4 instructions DC_Removal algorithm performance
First key element – Sum Loop -- Order (N) Second key element – Shift Loop – Order (log2N) 4 instructions N * 5 instructions 1 + 2 * log2N DC_Removal algorithm performance
Third key element – FIFO circular buffer-- Order (N) 6 3 6 * N 2 DC_Removal algorithm performance
TigerSHARC pipeline DC_Removal algorithm performance
Set up pointers to buffers Insert values into buffers SUM LOOP SHIFT LOOP Update outgoing parameters Update FIFO Function return 2 4 4 + N * 5 1 + 2 * log2N 6 3 + 6 * N 2 --------------------------- 22 + 11 N + 2 log2N N = 128 – instructions = 1444 1444 cycles + 1100 delay cycles C++ debug mode – 9500 cycles??????? Time in theory Note other tests executed before this test. Means “cache filled” DC_Removal algorithm performance
Set up time Expected 2 + 4 instructions Actual 2 + 4 instructions + 2 stalls Why not 4 stalls? DC_Removal algorithm performance
First time round sum loop Expected 9 instructions LC0 load – 3 stalls Each memory fetch – 4 stalls Actual 9 + 11 stalls DC_Removal algorithm performance
Other times around the loop Expected 5 instructions Each memory fetch – 4 stalls Actual 5 + 8 stalls DC_Removal algorithm performance
Shift Loop – 1st time around Expected 3 instructions No stalls on LC0 load? 4 stall on ASHIFTR BTB hit followed by 5 aborts DC_Removal algorithm performance
Set up pointers to buffers Insert values into buffers SUM LOOP SHIFT LOOP Update outgoing parameters Update FIFO Function return Entry into subroutine 10 stalls? 2 0 stalls 4 2 stalls 4 + N * 5 N * 8 = 1024 stalls 1 + 2 * log2N 9 stalls 6 3 stalls 3 + 6 * N 3 stalls 2 -- Exit from subroutine 10 stalls? --------------------------- -------------- 22 + 11 N + 2 log2N 1061 stalls N = 128 – instructions = 1444 1444 cycles + 1061 stalls = 2505 cycles In practice 2507 cycles C++ debug mode – 9500 cycles??????? Time in theory / practice Note other tests executed before this test. Means “cache filled” DC_Removal algorithm performance
Final sum code – Using XR registers DC_Removal algorithm performance
Set up pointers to buffers Insert values into buffers SUM LOOP SHIFT LOOP Update outgoing parameters Update FIFO Function return Entry into subroutine 10 stalls 2 0 stalls 4 2 stalls 4 + N * 5 Was 1024 stalls 1 Was 1 + 2 * log2N + 9 stalls 6 3 stalls 3 + 6 * N 3 stalls 2 10 stalls --------------------------- 23 + 11 N Was 22 + 11 N + 2 log2N N = 128 – instructions = 1430 1430 + 279 delay cycles = 1709 cycles Was 2,504 cycles with JALU 1444 cycles + 1061 delay cycles Predicted stall with X-compute block = 249 stalls -- close enough to 256 = N * 2 – or one stall for each memory access Time in Practice Improved more than expected as accidentally making better use of available resources DC_Removal algorithm performance
Second time into functionFirst time around the loop 2 stalls per loop iteration as predicted DC_Removal algorithm performance
2nd time into function9th time around the loop Note sets of 5 quad instructions appear to be fetch in Stalls as expected DC_Removal algorithm performance
Interpretation • Currently XR2 = [J0 + J8];; XR6 = R6 + R2;; // Must wait 1 cycle for XR2 to be brought in XR3 = [J1 + J8];; XR7 = R7 + R3;; // Must wait 1 cycle for XR3? • Next improvement? XR2 = [J0 + J8];; XR3 = [J1 + J8];; XR6 = R6 + R2;; // XR2 and XR3 are now ready when we want to use // them? XR7 = R7 + R3;; // or do we get DATA / DATA clash along J-bus? DC_Removal algorithm performance
Pipeline “intermingled” left and right filter operation DC_Removal algorithm performance
Set up pointers to buffers Insert values into buffers SUM LOOP SHIFT LOOP Update outgoing parameters Update FIFO Function return Entry into subroutine 10 stalls 2 0 stalls 4 2 stalls 4 + N * 5 Was 1024 stalls 1 Was 1 + 2 * log2N + 9 stalls 6 3 stalls 3 + 6 * N 3 stalls 2 10 stalls --------------------------- 23 + 11 N Was 22 + 11 N + 2 log2N N = 128 – instructions = 1430 1430 + 279 delay cycles = 1709 cycles Was 2,504 cycles with JALU 1444 cycles + 1061 delay cycles Predicted stall with X-compute block = 249 stalls -- close enough to 256 = N * 2 – or one stall for each memory access Intermingled code – around 1430 cycles + 30 stalls Time in Practice DC_Removal algorithm performance
1st time into function1st time round the loop DC_Removal algorithm performance
1st time into function2nd, 3rd, … time round loop DC_Removal algorithm performance
9th, 17th etc time into the loop DC_Removal algorithm performance
From TigerSHARC p9-11 Reading in 8-words at a time from “memory” into “cache” MIGHTexplain the behaviour DC_Removal algorithm performance
Again, talking about“8” data values DC_Removal algorithm performance
Read buffer DC_Removal algorithm performance
Implications – read buffer • Prefetch buffer • 4 pages • Each page 8 256 bit words = 64 items • Buffer = 256 – exactly enough to handle 128 left and 128 right • Does that imply that speed does not scale up – 256 point arrays are slower than 2 x as slow as 128 points • May make sense to process all of left and then all of right? DC_Removal algorithm performance
Implications – cache • 4 way associative cache • 128 cache sets • Each cache set has four cache ways • Each cache way – 8 32 bit words • That’s 1024 32bit words • Things break down when left / right arrays are of size 512, or else do all left then all right – things change at 1024 DC_Removal algorithm performance
To be tackled today • Expected and actual cycle count for Compute Block version of DC_Removal algorithm • Understanding why the stalls occur and how to fix. • Understanding some operations “first time into function” – cache issues? DC_Removal algorithm performance