Download

1 / 28
280 likes | 433 Views
Understanding the TigerSHARC ALU pipeline. Determining the speed of one stage of IIR filter – Part 4 IIR operation with Memory. Understanding the TigerSHARC ALU pipeline. TigerSHARC has many pipelines Review of the COMPUTE pipeline works

E N D
Understanding the TigerSHARC ALU pipeline Determining the speed of one stage of IIR filter – Part 4IIR operation with Memory
Understanding the TigerSHARC ALU pipeline • TigerSHARC has many pipelines • Review of the COMPUTE pipeline works • Interaction of memory (data) operations with COMPUTE operations • What we want to be able to do? • The problems we are expecting to have to solve • Using the pipeline viewer to see what really happens • Changing code practices to get better performance • Specialized C++ compiler options and #pragmas (Will be covered by individual student presentation) • Optimized assembly code and optimized C++ Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
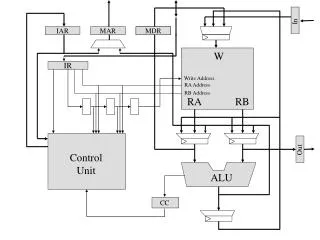
Processor Architecture • 3 128-bitdata busses • 2 Integer ALU • 2 ComputationalBlocks • ALU (Float and integer) • SHIFTER • MULTIPLIER • COMMUNICATIONSCLU Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
S0 S1 S2 Simple ExampleIIR -- Biquad • For (Stages = 0 to 3) Do • S0 = Xin * H5 + S2 * H3 + S1 * H4 • Yout = S0 * H0 + S1 * H1 + S2 * H2 • S2 = S1 • S1 = S0 Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Rewrite Tests so that IIR( ) function can take parameters Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Rewrite the “C++ code” I leave the old “fixed” values in until I can get the code to work. Proved useful this time as the code failed Why did it fail to return the correct value? Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Explore design issues – memory opsProbable memory stalls expected XR0 = 0.0; // Set Fsum = 0; XR1 = [J1 += 1]; // Fetch a coefficient from memory XFR2 = R1 * R4; // Multiply by Xinput (XR4) XFR0 = R0 + R2; // Add to sum XR3 = [J1 += 1]; // Fetch a coefficient from memory XR5 = [J2 += 1]; // Fetch a state value from memory XFR5 = R3 * R5; // Multiply coeff and state XFR0 = R0 + R5; // Perform a sum XR5 = XR12; // Update a state variable (dummy) XR12 = XR13 // Update a state variable (dummy) [J3 += 1] = XR12; // Store state variable to memory [J3 += 1] = XR5; // Store state variable to memory Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Looking much better. Use 10 nops to flush the instruction pipeline Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Pipeline performance predicted When you start reading values from memory, 1 cycle delay for value fetched available for use within the COMPUTE COMPUTE operations – 1 cycle delay expected if next instruction needs the result of previous instruction When you have adjacent memory accesses (read or write) does the pipeline work better with [J1 += 1];; or with[J1 += J4];; where J4 has been set to 1? [J1 += 1];; works just fine here (no delay).Worry about [J1 += J4];; another day Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Use C++ IIR code as comments Things to think about Register name reorganization Keep XR4 for xInput – save a cycle Put S1 and S2 into XR0 and XR1 -- chance to fetch 2 memory values in one cycle using L[ ] Put H0 to H5 in XR12 to XR16 -- chance to fetch 4 memory values in one cycle using Q[ ] followed by one normal fetch -- Problems – if more than one IIR stage then the second stage fetches are not quad aligned There are two sets of multiplications using S1 and S2. Can these by done in X and Y compute blocks in one cycle? float *copyStateStartAddress = state;S1 = *state++;S2 =*state++; *copyStateStartAddress++ = S1;*copyStateStartAddress++ = S2; Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Make copy of COMPUTE optimized codefloat IIRASM_Memory(void); Change the register names and make sure that it still works New assembly code – step 1 Things to think about Register name reorganization Keep XR4 for xInput – save a cycle Put S1 and S2 into XR10 and XR11 -- chance to fetch 2 memory values in one cycle using L[ ] Put H0 to H5 in XR12 to XR16 -- chance to fetch 4 memory values in one cycle using Q[ ] followed by one normal fetch -- Problems – if more than one IIR stage then the second stage fetches are not quad aligned There are two sets of multiplications using S1 and S2. Can these by done in X and Y compute blocks in one cycle? Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Write new testsNOTE: New register names don’t overlap with old namesMakes the name conversion very straight forward Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Register name conversion done in steps Setting Xin – XR4and Yout = XR8saves one cycle Bulk conversionwith no error So many errors made during bulk conversion that went to Find/replace/ test for each register individually Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Update tests to use IIRASM_Memory( ) version with real memory access Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Fix bringing state variables in QUESTION We haveXR18 = [J6 += 1] (load S1) andR19 = [J6 += 1] (load S2) Both are valid What is the difference? Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Need to recalculate the test resultstate[1] is NOT Yout Send state variables outGo for the gusto – use L[ ] (64-bit) Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
S0 = Xin 5.5 + S1 *H4 + 2 * 5 + S2 * H3 + 3 * 4 S1 = S0 Expect stored value of 27.5 Need to fix testof state values after function CHECK(state[0] == 27.5); Redo calculation for value stored as S1 Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Working solution -- I Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Working Solution -- Part 2 Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Working solution – Part 3 I could not spot where any extra stalls would occur because of memory pipeline reads and writes All values were in place when needed Need to check with pipeline viewer Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Lets look at DATA MEMORY and COMPUTE pipeline issues -- 1 No problems here Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Lets look at DATA MEMORY and COMPUTE pipeline issues -- 2 No problems here Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Weird stuff happening with INSTRUCTION pipeline Only 9 instructions being fetched but we are executing 21! Why all these instruction stalls? Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Adjust pipeline view for closer look.Adjust dis-assembler window Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Analysis • We are seeing the impact of the processor doing quad-fetches of instructions (128-bits) into IAB (instruction alignment buffer) • Once in the IAB, then the instructions (32-bits) are issued to the various executionunits as needed. Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Note the fetch into the next subroutine despite return (CJMP) Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Note that processor continues to fetch “the wrong” instructions Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada
Understanding the TigerSHARC ALU pipeline • TigerSHARC has many pipelines • Review of the COMPUTE pipeline works • Interaction of memory (data) operations with COMPUTE operations • What we want to be able to do? • The problems we are expecting to have to solve • Using the pipeline viewer to see what really happens • Changing code practices to get better performance • Specialized C++ compiler options and #pragmas (Will be covered by individual student presentation) • Optimized assembly code and optimized C++ Speed IIR -- stage 4 M. Smith, ECE, University of Calgary, Canada