Download

1 / 32
320 likes | 452 Views
Understanding the TigerSHARC ALU pipeline. Determining the speed of one stage of IIR filter – Part 2 Understanding the pipeline. Understanding the TigerSHARC ALU pipeline. TigerSHARC has many pipelines If these pipelines stall – then the processor speed goes down

E N D
Understanding the TigerSHARC ALU pipeline Determining the speed of one stage of IIR filter – Part 2Understanding the pipeline
Understanding the TigerSHARC ALU pipeline • TigerSHARC has many pipelines • If these pipelines stall – then the processor speed goes down • Need to understand how the ALU pipeline works • Learn to use the pipeline viewer • Understanding what the pipeline viewer tells in detail • Avoiding having to use the pipeline viewer • Improving code efficiency • Excel and Project (Gantt charts) are useful tool Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
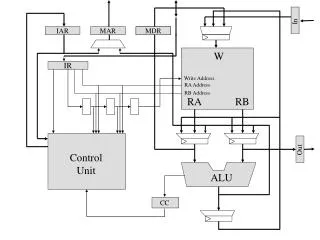
Register File and COMPUTE Units Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
S0 S1 S2 Simple ExampleIIR -- Biquad • For (Stages = 0 to 3) Do • S0 = Xin * H5 + S2 * H3 + S1 * H4 • Yout = S0 * H0 + S1 * H1 + S2 * H2 • S2 = S1 • S1 = S0 Horrible IIR codeexample as can’t re-use in a loop Works as asimple example for understanding TigerSHARCpipeline Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Code return float when using XR8 register – NOTE NOT XFR8 Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Step 2 – Using C++ code as comments set up the coefficients XFR0 = 0.0;; Does not exist XR0 = 0.0;; DOES EXIST Bit-patternsrequireintegerregisters Leave what youwanted to dobehind ascomments Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Expect to take8 cycles to execute Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
PIPELINE STAGESSee page 8-34 of Processor manual • 10 pipeline stages, but may be completely desynchronized (happen semi-independently) • Instruction fetch -- F1, F2, F3 and F4 • Integer ALU – PreDecode, Decode, Integer, Access • Compute Block – EX1 and EX2 Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Pipeline Viewer Result XR0 = 1.0 enters PD stage @ 39025, enters E2 stage at cycle 39830 is stored into XR0 at cycle 39831 -- 7 cycles execution time Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Pipeline Viewer Result XR6 = 5.5 enters PD stage at cycle 39032 enters E2 stage at cycle 39837 is stored into XR6 at cycle 39838 -- 7 cycles execution time Each instruction takes 7 cycles but one new result each cycle Result – ONCE pipeline filled 8 cycles = 8 register transfer operations Key – don’t break pipeline with any jumps Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Doing filter operations – generates different results XR8 = XR6 enters PD at 39833, enters EX2 at 39838, stored 39839 – 7 cyclesXFR23 = R9 * R4 enters PD at 39834, enters EX2 at 39839, stored 39840 – 7 cyclesXFR0 = R0 + R23 enters PD at 39835, enters EX2 at 39841, stored 39842 – 8 cycles WHY? – FIND OUT WITH MOUSE CLICK ON S MARKER THEN CONTROL Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Instruction 0x17e XFR8 = R8 + R23 is STALLED (waiting) for instruction 0x17d XFR23 = R8 * R4 to complete Bubble B means that the pipeline is doing “nothing”Meaning that the instruction shown is “place holder” (garbage) Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Information on Window Event Icons Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Result of Analysis • Can’t use Float result immediately after calculation • WritingXFR23 = R8 * R4;; XFR8 = R8 + R23;; // MUST WAIT FOR XFR23 // calculation to be completedIs the same as codingXFR23 = R8 * R4;; NOP;; Note DOUBLE ;; -- extra cycle because of stallXFR8 = R8 + R23;; • Proof – write the code with the stalls shown in it • Writing this way means we don’t have to use the pipeline viewer all the time • Pipeline viewer is only available with (slow) simulator • #define SHOW_ALU_STALL nop Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Code withstalls shown • 8 code lines • 5 expected stalls • Expect 13 cyclesto completeif theory is correct Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Analysis approach IS correctSame speed with and without nops Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Process for coding for improved speed – code re-organization • Make a copy of the code so can test iirASM( ) and iirASM_Optimized( ) to make sure get correct result • Make a table of code showing ALU resource usage (paper, EXCEL, Project (Gantt chart) ) • Identify data dependencies • Make all “temp operations” use different register • Move instructions “forward” to fill delay slots, BUT don’t break data dependencies Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Copy and paste to makeIIRASM_Optimized( ) Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Need to re-order instructionsto fill delay slots with useful instructions • After refactoring code to fill delay slots, must run tests to ensure that still have the correct result • Change – and “retest” • NOT EASY TO DO • MUST HAVE ASYSTEMATIC PLAN TO HANDLEOPTIMIZATION • I USE EXCEL Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Show resource usage and data dependencies All temporaryregister usageinvolves theSAME XFR23register This typically stallsout the processor Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Change all temporary registers to use different register namesThen check code produces correct answer All temporaryregister usageinvolves a DIFFERENT Register ALWAYS FOLLOWTHIS PROCESSWHENOPTIMIZING Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Move instructions forward, without breaking data dependencies What appears possible! DO one thing at a time and then check that code still works Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Check that code still operates1 cycle saved Have put “our” marker stall instructionin parallel with moved instructionusing ; rather than ;; Move this instruction up in code sequence to fill delay slot Check that code still runsafter this optimization stage Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Move next multiplication up. NOTE certain stalls remain, although reason for STALL changes from why they were inserted before Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Move up the R10 and R9 assignment operations -- check 4 cycle improvement? Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
CHECK THE PIPELINE AFTER TESTING Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Are there still more improvements possible (I can see 4 more moves) Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Problems with approach • Identifying all the data dependencies • Keep track of how the data dependencies change as you move the code around • Handling all of this “automatically” • I started the following design tool as something that might work, but it actually turned out very useful.M. R. Smith and J. Miller, "Microprocessor Scheduling -- the irony of using Microsoft Project","Don’t say “CAN’T do it - Say “Gantt it”! The irony of organizing microprocessors with a big business tool" Circuit Cellar magazine, Vol. 184, pp 26 - 35, November 2005. Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Using Microsoft Project – Step 1 Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Add dependencies and resource usage – then activate level Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Microsoft Project as a microprocessor design tool • Will look at this in more detail when we start using memory operations to fill the coefficient and state arrays Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada
Understanding the TigerSHARC ALU pipeline • TigerSHARC has many pipelines • If these pipelines stall – then the processor speed goes down • Need to understand how the ALU pipeline works • Learn to use the pipeline viewer • Understanding what the pipeline viewer tells in detail • Avoiding having to use the pipeline viewer • Improving code efficiency • Excel and Project (Gantt charts) are useful tool Speed IIR -- stage 1, M. Smith, ECE, University of Calgary, Canada